

Linux & Shell 学习笔记【2/2】
0. 概述
此篇文章内容为上一篇文章的后续,主要详述通过shell解析swift 569报文到指定的格式。因为需要通过sqlLoader将内容load入库,所以目标文本格式为各个字段以‘|’分隔。
因为MT569报文有有些sequence会重复,所以在解析的过程中会将其与普通的sequence分开处理。
一. MT569报文信息
MT569报文总共包含4个Sequence(A/B/C/D),根据每个Sequence的subSequence再细分,总共有10个sequence(A/A1/A2/B/C/C1/C1a/C1a1/C1a1A/D), 其中Sequence A1/A2/C/C1/C1a/C1a1/C1a1A/D会重复,而Sequence A/B不会重复,故将A/B的内容作合并解析,其余重复的Sequence会各自单独解析。
二. 脚本信息
主要包含如下4个脚本
MT569_Config.sh --- 该脚本包含了针对MT569报文的相关配置
CommonFunction.sh --- 该脚本包含了一些通用的方法,如针对报文中某些字段需要特殊解析成多个字段
BasicExtraction.sh --- 该脚本包含了针对类似MT569报文格式(16R/16S)的通用解析方法
ExtractMT569.sh --- 该脚本为主脚本,其中会调用到如上三个脚本
下面依次对各个脚本进行讲解。
2.1 MT569_Config.sh
包含了如下几个变量:
2.1.1 AllSeq

AllSeq是一个数组变量,包含了两个元素,分别对应sequence(A/B)的信息。针对每个元素包含了多个以空格个隔开的内容,目的是为了在脚本中将元素再作为数组遍历处理。
每个元素中第一个内容为该Sequence 16R的取值,如Sequence A 16R=GENL,用于在脚本匹配到Sequence A。
每个元素中第二个内容为解析后需要输出的目标文件名,此处为MT569.txt。
每个元素中后面的内容为针对序列A需要解析的Tag,此处的Tag有三种情况:
①. 只有一种format且不存在qualifier --- 直接填写Tag,如28E/23G
②. 存在多种format且存在qualifier --- 省略掉Tag中format对应的字母,并且在后面添加上:index。如98:2表示匹配Tag 98a,且qualifier的可取值为SpecialMappingTag[2]的内容(该参数会在后续提到)
③. 只有一种format且存在qualifier --- 在Tag后面添加上:index,与第二点类似。如13A:0表示匹配Tag 13A,且qualifier的可取值为SpecialMappingTag[0]的内容(该参数会在后续提到)
2.1.2 RepetitiveSeq

RepetitiveSeq是一个数组变量,包含了需要解析的重复组的Sequence,定义格式和变量AllSeq类似。
2.1.3 SpecialMappingTag

SpecialMappingTag变量是一个数组变量,数组中的每个元素为针对单一Tag对应的qualifier列表,每个元素中若存在多个qualifier,则以空格隔开。如在2.1.1中提到的13A:0, 即该数组的第0个元素STAT,即13A的qualifier为STAT。如上的截图中仅为部分内容。
2.1.4 FileList/ReceiveFolder/ReceiveFolderBak/DestinationFolder
FileList定义了解析后的输出文件列表,就是在2.1.1和2.1.2定义的数组中的每个元素的第二个内容的集合。这里重新定义一遍只是为了脚本中处理更方便。如下截图仅为部分内容。

ReceiveFolder/ReceiveFolderBak/DestinationFolder定义了遍历处理的文件夹/处理完成后备份的文件夹/处理成功后需要移动至的目的文件夹

2.2 CommonFunction.sh
该脚本包含了一些通用的方法。
2.2.1 IsCharExistInArray
该方法判断了字符串是否在数组中,是则返回0,反之返回1。其中主要使用到了grep -wq,w为精确匹配,q为quiet,即不输出匹配的内容。此处使用到了shell中if then来判断,需要注意的是在shell中if后面跟的中括号的各个内容均需要空格隔开,可以理解为传入中括号中的三个参数,所以需要空格隔开。

2.2.2 SplitStatementLine
该方法主要用于split field StatementLine,部分截图如下。
在使用字符串截取的时候可以${variable:index:length}的方式,其中index从0开始,length为截取的长度
因为shell中默认的变量类型为字符,所以如果需要对变量进行运算,可以借助let,如图中所示(此时等号后面的变量无需加美元符号)。也可以使用中括号的方式实现:index=$[$index+$length]
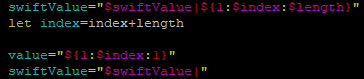
2.2.3 FindAlphabet
该方法是一个递归方法,用于寻找字母在字符串中的位置。调用到方法DetermineCharType返回当前字符的类型。

2.2.4 DetermineCharType
该方法用于判断单个字符的类型,数字返回0,字母返回1,其他返回2。使用到了shell中的case来处理不同的情况。

2.2.5 ProcessSwiftValue
该方法根据不同的Tag和qualifier对报文中的值进行处理,主要用于针对一个Tag中需要解析成多个字段的处理。如下为部分内容的截图,其中传入该方法的参数分别用$1 $2 $3标识,$1为tag,$2为需要处理的value,$3为qualifier。如下针对Tag 92A和99A需要先以'//'为分隔符后取到第二个字符,在将字符中的‘,’替换成'.',取到的字符中如果首个字符为字母,则会去除字母并取剩下的内容。最后如果qualifier是PRIC,则需要加上‘||’。

2.2.6 GetMultiLineValue
报文中某些Tag的内容存在多行,该方法用于处理这种情况,将取到所有行的内容。

2.3 BasicExtraction.sh
该脚本包含了针对类似569报文的解析步骤。
2.3.1 GetAllSeq
该方法用于解析2.1提到的配置文件中变量AllSeq的内容

如上图所示,在第11行遍历了配置文件中定义的AllSeq数组,在13行把当前元素转化成数组currentSeq,在15和16行通过匹配16R和16R对应的值来获取当前Sequence所在的起始行并将获取到的结果转成数组startLineArr,而后在17行对获其进行遍历,根据起始行号和下一个16R来获取endLineNum。获取完成后通过GetContent方法来获取需要当前Sequence需要解析Tag的值。在25-29行中对解析好的content进行处理并输出到对应的文件中。
2.3.2 GetRepetitiveSeq

如上图所示,在38行中遍历数组RepetitiveSeq,在40-45行处关联表间的引用关系(如C与C1,C1与C1a之间),在46-52行获取当前元素的数组currentSeq并且获取起始/终止行的行数数组startLineArr和endLineArr。在54行开始根据起始行数组startLineArr遍历,在5-64行中获取到终止行并调用GetContent获取content的内容并调用GetRefValue获取当前Sequence引用值(给下一个Sequence使用)并输出至指定文件。
2.3.3 GetContent
该方法用于获取报文中的每个tag的content
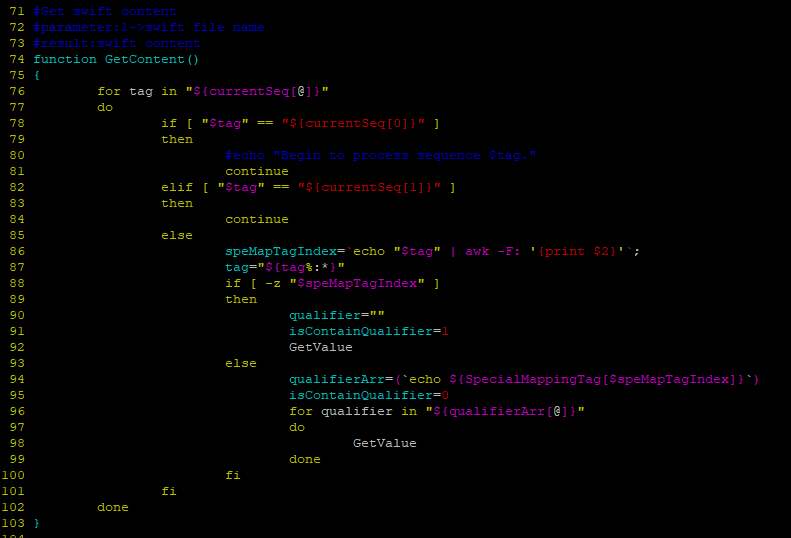
如上图所示,在76行中会遍历当前序列currentSeq中的元素,在78-84中对第一个和第二个元素特殊处理直接跳过。86行中获取存在qualifier需要mapping的index,87行获取匹配的tag,根据获取到的speMapTagIndex是否为空,在88-99行中分别做不同的处理后再调用GetValue方法去获取当前Tag的值,针对存在qualifier的 tag,需要遍历根据index映射的数组,依次获取该Tag下不同qualifier的值。
2.3.4 GetValue
该方法用于获取Tag的值。

如上图所示,在113行中获取该Tag所在行的细节内容lineDetail遍历,包含了Tag,行号,Tag value。获取Tag的原因是某些Tag存在多种format,在配置时候忽略的匹配format的字母,此处需要获取完整的Tag用于后续Tag Value的处理。如果该Tag为查询找,则变量lineDetail为空,则通过124-125行对其赋空值;反之在116-122行中进行处理,依次获取下一行行号nextLineNum后,通过调用GetMultiLineValue方法进行获取当前Tag的value。
2.3.5 GetRefValue
该方式用于获取当前Sequence中的引用值,即当前Sequence和上一个Sequence关联字段的值。

2.4 ExtractMT569.sh
该脚本为主要的调用脚本,主要做的就是一些文件/文件夹存在判断,解析完成的文件移动,以及初始变量的赋值。
部分内容截图如下:

在调用 GetAllSeq之前,需要设定好refTag和refQualifier两个变量,用于获取当前Sequence中的Tag/qualifier作为之后部分Sequence的reference Value。同样在调用GetRepetitiveSeq,需要设定好refInfoArr数组变量,元素的顺序需要和配置文件中RepetitiveSeq中定义的Sequence顺序相同。每个元素包含三个值,以‘|’隔开,第一个值为refTag(不需要则置空),第二个值为refQualifier(不需要则置空),第三个为refValue。以第一个元素为例,该元素对应A1sequence,通过refValue和AllSeq进行关联;第三个元素中通过refValue和AllSeq关联的同时,通过refTag=22 and refQualifier=COLA与next Sequence进行关联。
三. 运行测试
在执行脚本后会根据配置的输出文件名输出对应的文件,如下所示
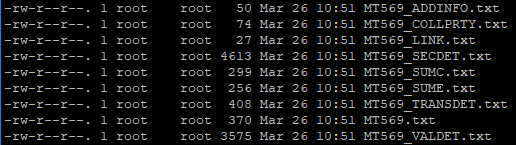
内容以主表MT569.txt为例,字段值之间以‘|’分隔,作为后续SqlLoader的源文件:

四. 小结
不同类型的Swift报文在格式上略有差异,此shell基本上能够满足与MT569报文类似的报文(以16R/16S标识Sequence的开头/结尾),只需根据Swift报文所需解析的字段对配置文件进行配置,并对通用方法脚本进行配置,最后新建针对Swift报文的主解析脚本即可,如果没有特殊的情况,build所需的工作量已经不多了。
最后附上相关配置dataLoader.zip

