Java set接口之HashSet集合的学习
Set接口的简单概述
java.util.set接口继承自Collection接口,它与Collection接口中的方法基本一致,并没有对 Collection接口进行功能上的扩充,只是比collection接口更加严格了。set接口中元素是无序的,并且都会以某种规则保证存入的元素不出现重复。
简述其特点:
- 不允许存储重复的元素
- 没有索引,也没有带索引的方法,不能使用普通的for循环遍历
Set接口有多个实现类,java.util.HashSet是其常用的子类
HashSet集合的介绍
- java.util.HashSet是set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。
- java.util.HashSet底层的实现其实是一个java.util.HashMap支持
- HashSet是根据对象的哈希值来确定元素在集合中的存储位置的,因此具有良好的存取和查找性能。
- 保证元素唯一性的方式依赖于:hashCode与 equals方法。
代码简单理解
复制import java.util.HashSet; import java.util.Iterator; public class DemoHashSet { public static void main(String[] args) { // 创建set集合(HashSet) HashSet<String> hashSet = new HashSet<>(); // 使用add方法想HashSet集合中添加元素 hashSet.add("A"); hashSet.add("B"); hashSet.add("C"); hashSet.add("D"); hashSet.add("A"); System.out.println("集合中的元素:" + hashSet); System.out.println("=============================="); // 使用迭代器遍历集合 Iterator<String> ite = hashSet.iterator(); while (ite.hasNext()) { System.out.println(ite.next()); } System.out.println("=============================="); // 使用增强for循环遍历集合(不能使用普通的for循环,对HashSet集合进行遍历) for (String s: hashSet) { System.out.println(s); } } }
复制输出结果: 集合中的元素:[A, B, C, D] ============================== A B C D ============================== A B C D
注意:普通for循环不能遍历HashSet集合,HashSet集合中没有重复的元素,元素的存储顺序不一致。
HashSet集合存储数据的结构(哈希表)
什么是哈希表
- 哈希表(又称散列表),它是根据关键码值(Key - Value)而直接进行访问的数据结构。
- 也就是说,哈希表是通过把关键码值(Key)映射到表中一个位置来访问记录(Value),以加快查找的速度。这个映射函数叫做哈希函数(散列函数),存放记录的数组叫做哈希表。
- 在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同hash值的链表都存储在一个链表里。
- 但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
- 而JDK1.8中,哈希表存储采用数组+链表+或数组+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
什么是链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
什么是红黑树
红黑树(又称对称二叉B树),是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。
什么是关联数组
是一种具有特殊索引方式的数组。不仅可以通过整数来索引它,还可以使用字符串或者其他类型的值(除了NULL)来索引它。
哈希值
- 哈希值是通过一定的哈希算法,将一段较长的数据映射为较短小的二进制数据,这段小数据就是大数据的哈希值。
- 特点:它是唯一的,一旦大数据发生了变化,哪怕是一个微小的变化,他的哈希值也会发生变化。
- 作用:主要用途是用于文件校验或签名。
在Java程序中的哈希值
复制/** * 在Java中哈希值:是一个十进制的整数,由系统随机给出的二进制数经过换算得到的 * 其实它就是对象的地址值,是一个逻辑地址,是模拟出来得到地址,并不是数据实际存储的物理地址 * * 在Object类有一个方法,可以获取对象的哈希值: * int hashCode() 返回对象的哈希码值 * hashCode()方法源码: * public native int hashCode(); * native:代表该方法是调用本地操作系统的方法 */ // 随便创建一个类 public class Person extends Object{ private String name; private int age; public Person() { } public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }
复制// 用这个类创建对象,查看对象的哈希值 public class DemoHashCode { public static void main(String[] args) { // 创建一个p1对象,查看其哈希值 Person p1 = new Person("LeeHua", 21); // 调用Object的hashCode方法,获取哈希值,p1的哈希值是不变的 int h1 = p1.hashCode(); System.out.println(h1); // 创建一个p2对象,查看其哈希值 Person p2 = new Person("WanTao", 20); // 调用Object的hashCode方法,获取哈希值,p2的哈希值也是不变的 int h2 = p2.hashCode(); System.out.println(h2); // 查看p1、p2的地址值 System.out.println(p1); System.out.println(p2); } }
复制输出结果: 1639705018 1627674070 view.study.demo18.Person@61bbe9ba view.study.demo18.Person@610455d6
假如覆盖重写hashCode方法,所创建的对象的哈希值就会被影响
如:
复制public class Person1 extends Object{ /** * 重写hashCode方法 * @return 哈希值 */ @Override public int hashCode() { return 666; } }
复制public class DemoHashCode1 { public static void main(String[] args) { // 创建一个p1对象,查看其哈希值 Person1 p1 = new Person1(); // 调用Object的hashCode方法,获取哈希值,p1的哈希值是不变的 int h1 = p1.hashCode(); System.out.println(h1); // 查看p1、p2的地址值 System.out.println(p1); } }
复制输出结果: 666 view.study.demo18.Person1@29a
如:我们常用的String类,它也覆盖重写了hashCode方法
复制public class DemoStringHashCode { public static void main(String[] args) { /* String类的哈希值 (String类重写了Object类的hashCode方法) */ String s1 = new String("LeeHua"); String s2 = new String("WanTao"); System.out.println(s1.hashCode()); System.out.println(s2.hashCode()); } }
复制输出结果: -2022794392 -1711288770
图形理解
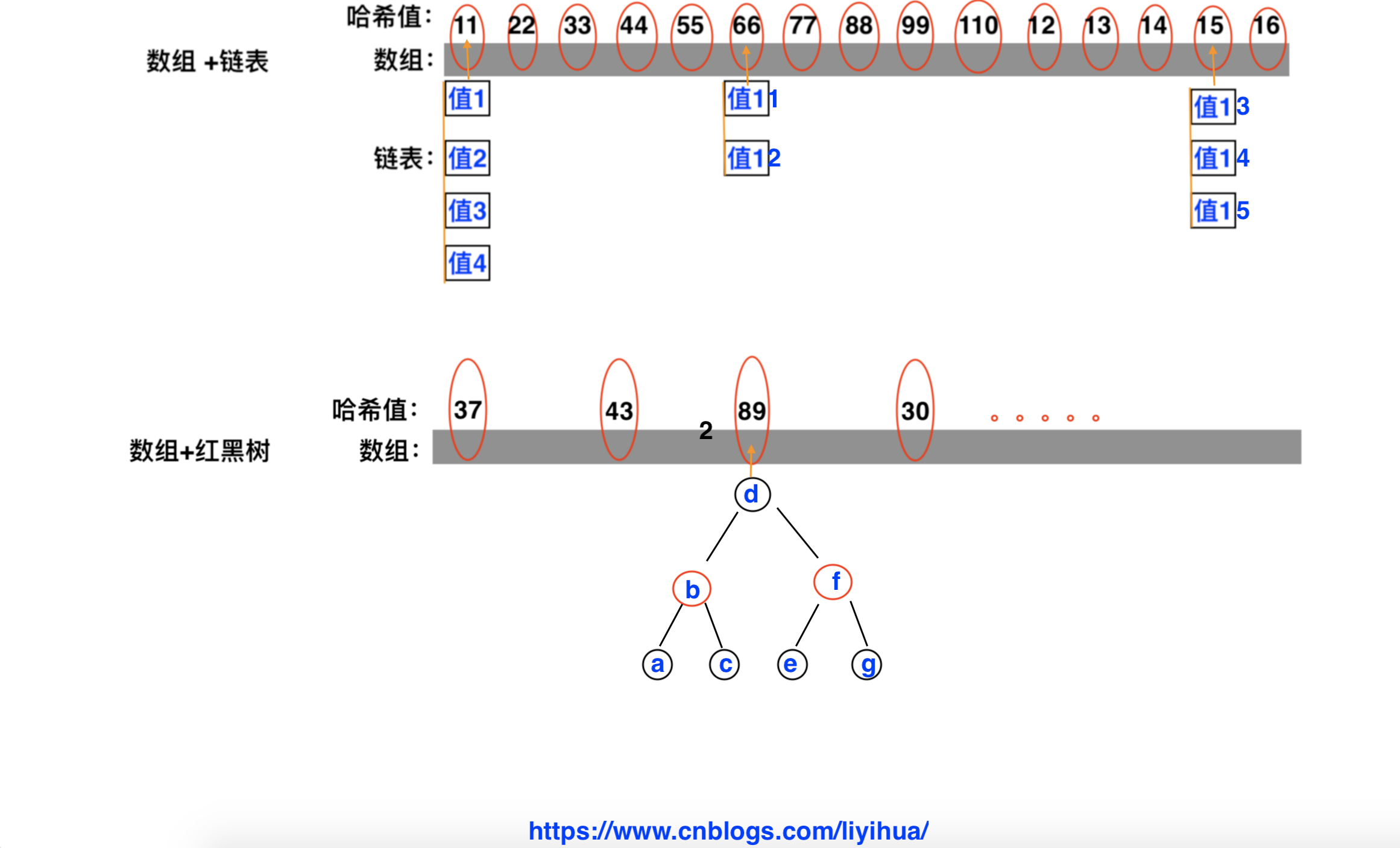
-
可以看到,数组的每个位置放到一定的值,每部分值都对应一个哈希值。
-
当值的个数超过8个的时候,采用数组+红黑树;当值的个数不到8个的时候,采用数组+链表
-
如:
值1、2、3、4的哈希值都是11
值13、14、15的哈希值都是15
值a、b、c、d、e、f、g的哈希值都是89
Set集合存储元素不重复原理
set集合在调用add()方法的时候,add()方法会调用元素的hashCode()方法和 equals()方法判断元素是否重复
代码举例
复制import java.util.HashSet; public class DemoStringHashCode1 { public static void main(String[] args) { HashSet<String> hashSet = new HashSet<>(); String s1 = new String("abc"); String s2 = new String("abc"); hashSet.add(s1); hashSet.add(s2); hashSet.add("一号"); hashSet.add("二号"); System.out.println("s1的哈希值:" + s1.hashCode()); System.out.println("s2的哈希值:" + s2.hashCode()); System.out.println("一号的哈希值:" + "一号".hashCode()); System.out.println("二号的哈希值:" + "二号".hashCode()); System.out.println("HashSet集合:" + hashSet); } }
复制输出结果: s1的哈希值:96354 s2的哈希值:96354 一号的哈希值:640503 二号的哈希值:644843 HashSet集合:[二号, abc, 一号]
代码讲解
最初,hashSet集合是空的
- hashSet.add(s1)的时候
- 第一步:add()方法首先会调用s1的hashCode()方法,计算字符串"abc"的哈希值,其哈希值是96354,
- 第二步:查找集合中哈希值是96354中的元素,没有发现哈希值是96354的key
- 第三步:将s1存储到集合hashSet中(于是集合hashSet中存在哈希值96354,且对应这数据s1)
- hashSet.add(s2)的时候
- 第一步:add()方法首先会调用s2的hashCode()方法,计算字符串"abc"的哈希值,其哈希值是96354,
- 第二步:查找集合hashSet中是否存在哈希值是96354,即哈希值96354冲突,
- 第三步:s2调用equals()方法,和集合中哈希值是96354对应的元素进行比较
- 第四步:s2.equals(s1)返回true,即哈希值是96354对应的元素已经存在,所以就不添加s2进集合了(其中:s1 = "abc",s2 = "abc")
- hashSet.add("一号")的时候
- 第一步:调用 "一号" 的hashCode()方法,计算字符串 "一号" 的哈希值,其哈希值是640503,
- 第二步:查找集合中哈希值是640503中的元素,没有发现哈希值是640503的key,
- 第三步:将 "一号" 存储到集合hashSet中(于是集合hashSet中存在哈希值640503,且对应这数据 "一号")
- hashSet.add("二号")的时候
- 第一步:调用 "二号" 的hashCode()方法,计算字符串 "二号" 的哈希值,其哈希值是644843,
- 第二步:查找集合中哈希值是644843中的元素,没有发现哈希值是644843的key,
- 第三步:将 "二号" 存储到集合hashSet中(于是集合hashSet中存在哈希值644843,且对应这数据 "二号")
- 添加完成,集合hashSet = [abc, 一号, 二号]
HashSet存储自定义类型元素
hashSet存储自定义类型元素,那么自定义的类必须重写hashCode()方法和equals()方法,否则添加的元素可以出现重复,我们平时使用的类型,它们都重写类hashCode()方法和equals()方法。
假如不重写hashCode()方法和equals()方法
例子:
复制// 随便创建一个类,作为HashSet存入数据的类型 public class Person{ private String name; private int age; @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } public Person() { } public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }
IDEA 编译,阿里巴巴Java Code规范会抛出警告
测试一下会出现什么情况
复制import java.util.HashSet; public class Demo01PersonHashSet { public static void main(String[] args) { HashSet<Person> hashSet = new HashSet<>(); Person p1 = new Person("小明", 20); Person p2 = new Person("小明", 20); Person p3 = new Person("小红", 20); hashSet.add(p1); hashSet.add(p2); hashSet.add(p3); System.out.println(hashSet); } }
复制输出结果: [Person{name='小明', age=20}, Person{name='小明', age=20}, Person{name='小红', age=20}]
可以看到,hashSet集合里面可以存在重复的元素。
重写hashCode()方法和equals()方法
还是上面这个例子:
在Person类里面添加要重写hashCode()、equals()方法的代码即可,要添加的代码如下
复制public class Person{ @Override public boolean equals(Object o) { // 参数 == 对象 if (this == o) { return true; } // 传入参数为空,或者对象与参数的hashCode不相等 if (o == null || getClass() != o.getClass()) { return false; } // 向下转型,把Object类型转型为Person类型 Person person = (Person) o; // 返回 age,name return age == person.age && Objects.equals(name, person.name); } @Override public int hashCode() { return Objects.hash(name, age); } }
再次用上面的代码测试一下Person类型的数据添加是否会出现重复:
复制输出结果: [Person{name='小明', age=20}, Person{name='小红', age=20}]
可以看到,输出结果中,hashSet集合的元素并没有重复,因此,如果我们想要用HashSet集合存储自定义类型的数据,一定要记得覆盖重写hashCode()方法和equals()方法。
本文来自博客园,作者:LeeHua,转载请注明原文链接:https://www.cnblogs.com/liyihua/p/12194084.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)