正则表达式和python中的re模块
常用的正则匹配规则
-
元字符
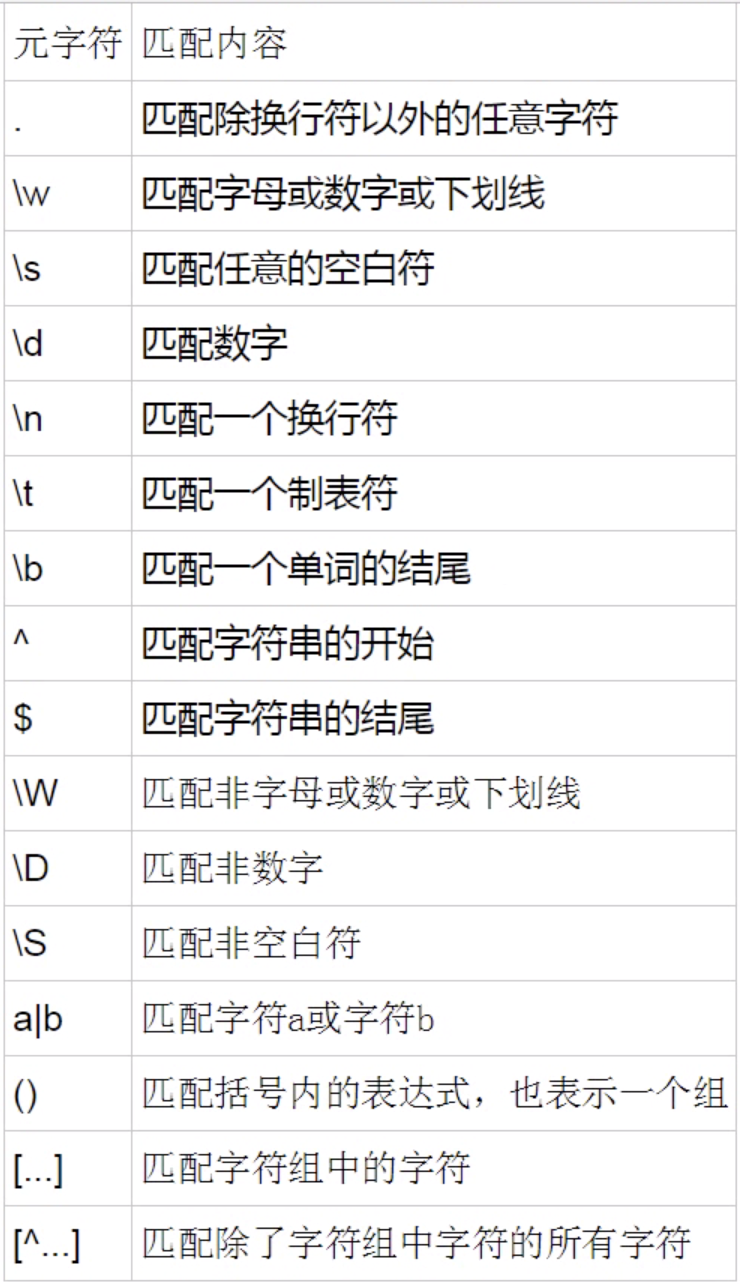
-
量词

-
字符组
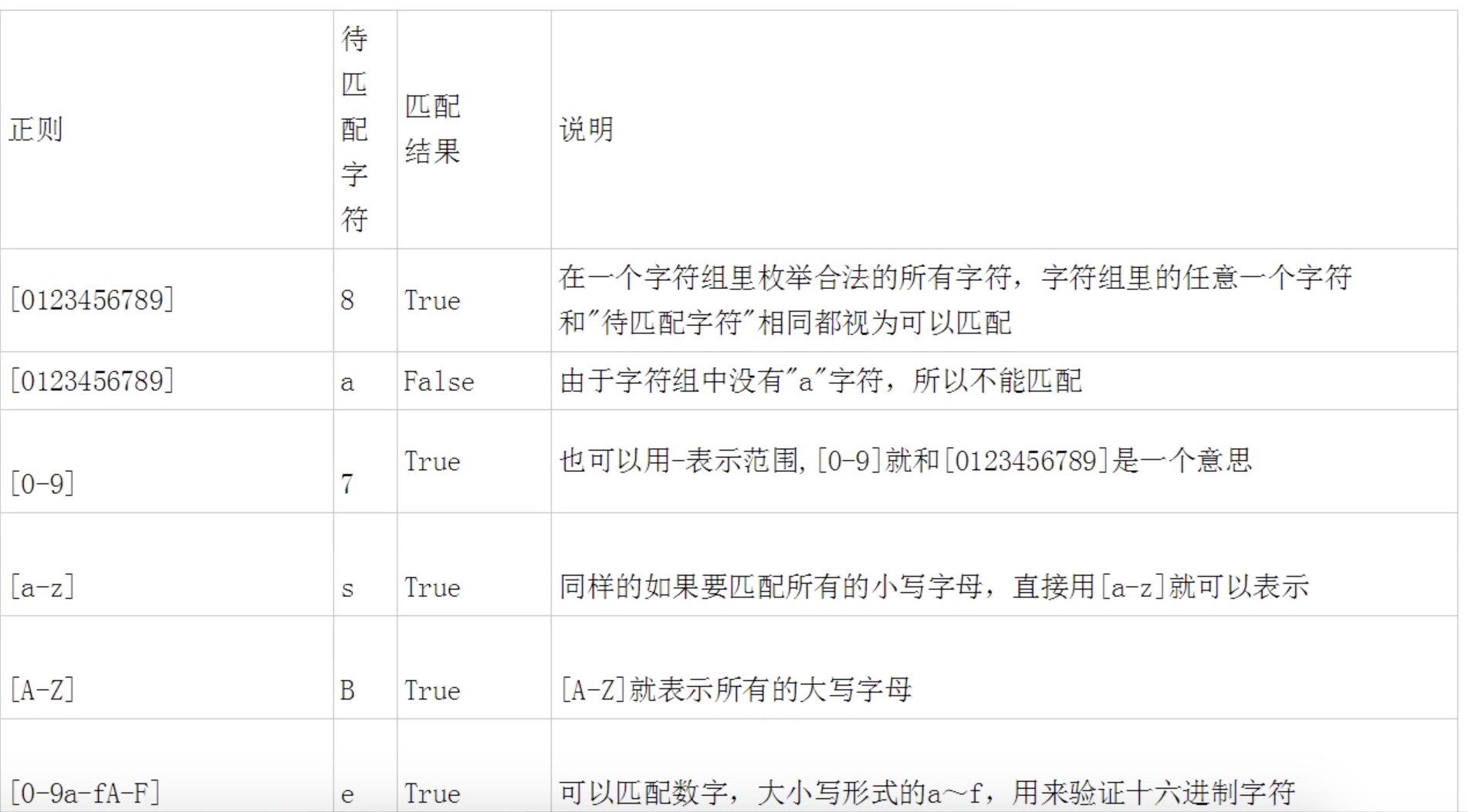
-
字符集
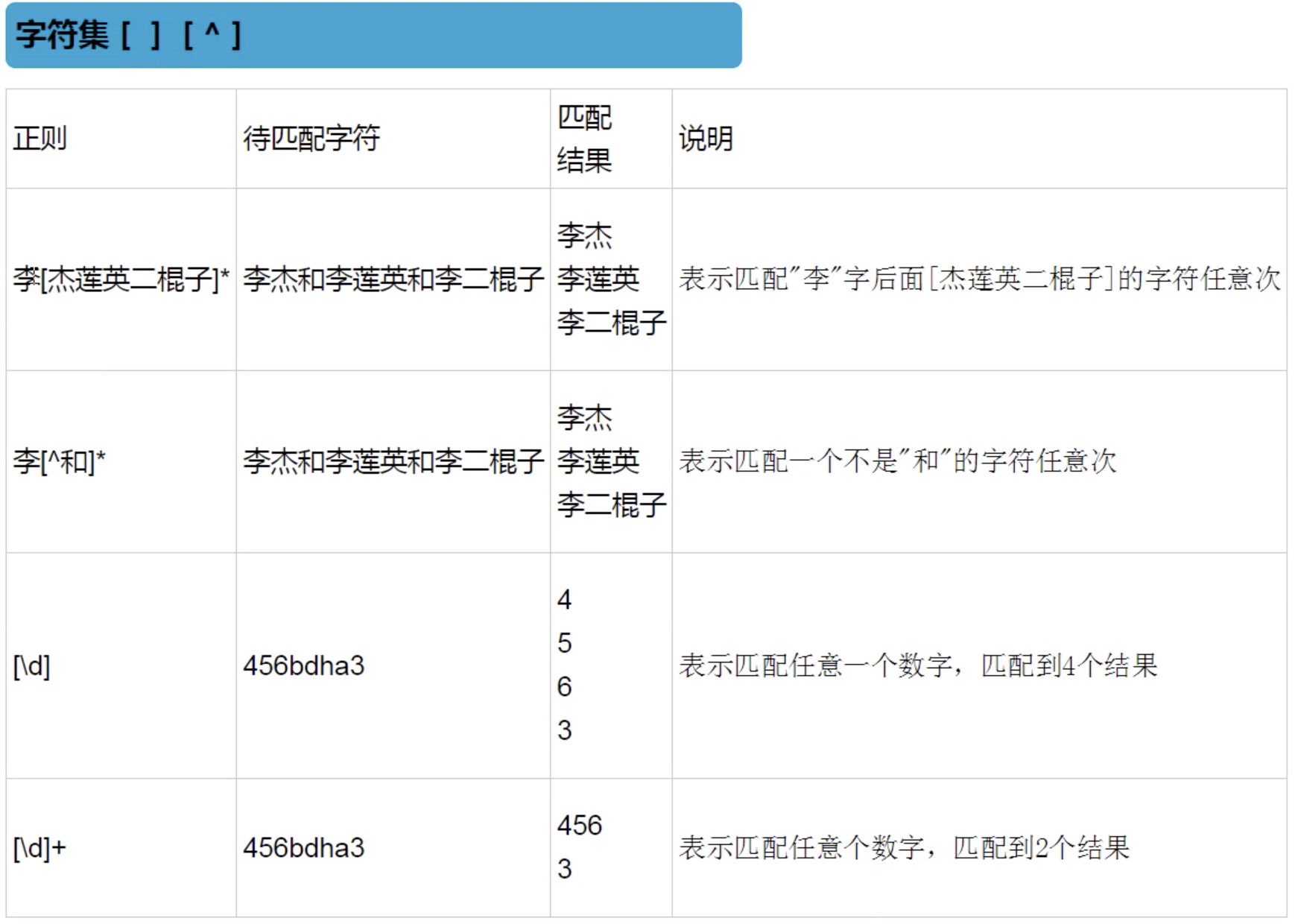
-
转义符

-
贪婪匹配

re模块使用正则表达式
举例:判断一个手机号码是否合法
-
不使用正则表达式
复制# 不使用正则表达式 phone_number = input("请输入一个11位数导入手机号码 :") if len(phone_number) == 11 \ and phone_number.isdigit() \ and (phone_number.startswith('13') or phone_number.startswith('15') or phone_number.startswith('17') or phone_number.startswith('18') or phone_number.startswith('19')): print("这个手机好码是合法的") else: print("这个手机号码是不合法的") -
使用正则表达式
复制# 调用re模块使用正则表达式 import re phone_number = input("请输入一个11位数导入手机号码 :") if re.match('^(13|15|17|18|19)[0-9]{9}$', phone_number): 正则规则 : ^(13|15|17|18|19)[0-9]{9}$ print("这个手机好码是合法的") else: print("这个手机号码是不合法的")
match 方法
- 是从头开始匹配,如果正则规则开头可以匹配上,就返回一个变量。匹配的内容需要调用group才能显示。
- 如果没有找到匹配内容,则返回None,调用group会报错
复制import re string = 'Hello! Regular expression, 520' result = re.match('^Hello!\s\w*\s\w+.\s\d{3}', string=string) print(len(string), result, result.group(), result.span(), sep='\n\n') # 输出: 30 <re.Match object; span=(0, 30), match='Hello! Regular expression, 520'> Hello! Regular expression, 520 (0, 30) # span()方法可以输出皮牌的范围
修饰符
- re.I 使匹配对大小写不敏感
- re.L 做本地化识别( locale-aware )匹配
- re.M 多行匹配,影响^和$
- re.S. 使 .匹配包括换行在内的所有字符
- re.U. 根据Unicode字符集解析字符。 这个标志影响\w、\W、\b和\B
- re.X. 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解
举例:
复制import re string = 'Hello! Regular expression, 520' result = re.match('^Hello!\s\w*\s\w+.\s\d{3}', string, re.S)
search 方法
从前往后,寻找到一个就返回,返回的变量需要调用group才能拿到结果。如果没有找到,那么返回None,调用group回报错
复制import re string = 'Hello! Regular expression, 5201314,Learning makes me happy and addicted to learning.' regular = 'Hello!\s\w*\s\w+.\s\d{3}' ret = re.search(regular, string) # 从前面往后面找到一个"Hello!\s\w*\s\w+.\s\d{3}"就返回 print(ret) # 返回的是一个对象 : <re.Match object; span=(0, 30), match='Hello! Regular expression, 520'>
findall 方法
想要获取匹配正则表达式的所有内容,借助findall()方法,该方法会搜索整个字符串
举例:
复制ret = re.findall('[a-z]+', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret) # 输出:['eva', 'egon', 'yuan']
sub 方法 和 subn 方法
sub()方法修改文本
举例:
复制ret = re.sub('\d', '马冬梅', '马什么梅? 0 马什么冬? 0 冬什么梅? 0', 3) # 将数字替换成'马冬梅',其中3代表替换了3次 print(ret) # 输出: 马什么梅? 马冬梅 马什么冬? 马冬梅 冬什么梅? 马冬梅
subn()方法和sub()方法很相似
举例:
复制import re ret = re.subn('\d', '马冬梅', '马什么梅? 0 马什么冬? 0 冬什么梅? 0') # 将数字替换成'马冬梅',返回元组(替换的结果,替换了多少次) print(ret) # 输出: ('马什么梅? 马冬梅 马什么冬? 马冬梅 冬什么梅? 马冬梅', 3)
compile 方法
将正则字符串编译成一个正则表达式对象
举例:
复制import re obj = re.compile('\d{3}') # 将正则表达式编译成一个正则表达式对象,这里正则规则是要匹配三个数字 ret = obj.search('abc123cba') # 正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) # 输出结果 : 123
finditer 方法
返回一个存放匹配结果的迭代器
举例:
复制import re ret = re.finditer('\d', 'ab2cd4567efg') # finditer返回一个存放匹配结果的迭代器 print(ret) print(next(ret).group()) # 查看第一个结果 print(next(ret).group()) # 查看第二个结果 print(i.group() for i in ret) # 查看剩余的所有结果 # 上一条print已经输出了所有的结果,所以这个for循环不输出任何字符 for i in ret: print(i.group()) # 输出: <callable_iterator object at 0x10a077cf8> 2 4 <generator object <genexpr> at 0x1142f5f48> 5 6 7
举例理解正则和re模块
-
例子1
复制ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # # ['oldboy'] 这是因为findall会优先匹配结果组内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # # ['www.oldboy.com'] 取消优先级别的权限 -
例子2
复制ret = re.split('\d+', 'eva3egon4yuan') print(ret) # 结果 : ['eva', 'egon', 'yuan'] ret = re.split('(\d+)', 'eva3egon4yuan') print(ret) # 结果 : ['eva', '3', 'egon', '4', 'yuan'] # 在匹配部分加上()之后,切出的结果是不同的, # 没有()的没有保留匹配的项,但是有()却能够保留匹配的项 # 这个在某些需要保留匹配部分的使用过程是非常重要的 -
例子3
复制ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>", "<hi>hello</hi>") # 还可以利用?P<name>的形式给分组起个名字 # 获取匹配的结果可以直接用group('名字')拿到对应的值 print(ret.group('tag_name')) # 结果 : hi print(ret.group()) # 结果 : <hi>hello</hi> -
例子4
复制ret = re.search("<(\w+)>\w+</\1>", "<hi>hello</hi>") # 如果不给组起名字也可以用\序号来找到对应的组,表示要找的内容要和前面组的内容一致 # 获取匹配的结果可以用group(序号)拿到对应的值 print(ret.group(1)) print(ret.group())
正则在线测试网址:http://tool.chinaz.com/regex/
抓取猫眼电影
复制import requests import re from requests.exceptions import RequestException import json import time # 抓取首页 def get_one_page(url): try: headers = { # 伪浏览器 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36' } response = requests.get(url, headers) # 响应 # 根据状态码返回响应内容 if response.status_code == 200: return response.text return None # 请求异常 except RequestException: return None # 正则表达式提取所需内容 def paser_one_page(html): # 正则 pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>' '.*?integer">(.*?)</i>.*?fraction">(.*?)</i></p>.*?</dd>', re.S) # 提取内容 items = re.findall(pattern, html) print(items) # 每部电影对应一个字典 for item in items: yield{ 'index': item[0], # 电影排名 'image': item[1], # 电影图片 'title': item[2], # 电影名称 'actor': item[3].strip()[3:], # 演员 'time': item[4].strip()[5:], # 上映时间 'score': item[5]+item[6] # 电影评分 } # 将提取的内容写入文件 def write_to_file(content): with open('result.txt', 'a', encoding='utf-8') as f: # 通过json.dumps(),实现字典的序列化,指定ensure_ascii=False保证输出结果是中文形式而不是Unicode编码 f.write(json.dumps(content, ensure_ascii=False)+'\n') f.close() def main(offset): url = 'http://maoyan.com/board/4?offset='+str(offset) # URL html = get_one_page(url) # 抓取网页 paser_one_page(html) # 提取抓取的内容 for item in paser_one_page(html): # 输出结果和写入文件 print(item) write_to_file(item) if __name__ == '__main__': for i in range(10): main(offset=i*10) time.sleep(1) # 现在猫眼多了反爬虫 , 如果速度过快,则会无响应,所以这里又增加了一个延时等待 # 运行后,生成一个result.txt文件,输出内容雨文件内容一致
本文来自博客园,作者:LeeHua,转载请注明原文链接:https://www.cnblogs.com/liyihua/p/11068362.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)