树形数据结构:并查集(基本+按秩合并优化+路径压缩)
迟来的笔记,早就学了并查集了,只是没有搬到博客园,一直存放在本地里了。
放两个讲得好的链接以便于复习:https://blog.csdn.net/dellaserss/article/details/7724401
https://www.xuebuyuan.com/3212977.html
找寻根节点,两种写法:
递推 //findFather函数返回元素x所在集合的根节点。 int findFather(int x) { while(x!=father[x])//如果不是根节点,继续循环。 { x=father[x];//获得自己的父亲结点。 } return x; }
递归 //findFather函数返回元素x所在集合的根节点。 int findFather(int x) { if(x==father[x]) return x;//如果找到根节点,则返回根节点编号x。 else return findFather(father[x]);//否则,递归判断x的父亲结点是否是根节点。 }
合并操作:
合并 void Union(int a,int b) { int faA=findFather(a);//查找a的根结点,记为faA。 int faB=findFather(b);//查找b的根结点,记为faB。 if(faA!=faB)//如果不属于同一个集合。 { father[faA]=faB;//合并它们。 } }
基本板子题:HDU1213:http://acm.hdu.edu.cn/showproblem.php?pid=1213
2:合并的优化:按秩合并。
合并x,y,先要搜到根节点,然后合并。这俩根节点的高度不同,如果把高度小的合并到大的树上,可以减少树的高度。这个高度,是根节点到叶节点的最长长度。摘一个博主的话:
对于每个结点x,有一个整数rank[x],它是x的高度(从x到其某一个后代叶结点的最长路径上边的数目)的一个上界。(即树高)。小的树忘大的树上靠就可以了。下面代码以hig[]为记录树的高度,初始化为0。pr[]为记录根节点,初始化为i。
void join(int x,int y) { x=find(x); y=find(y); if(hig[x]==hig[y]) { pr[y]=x; hig[x]++; } else { if(hig[x]<hig[y]) { pr[x]=y; } else { pr[y]=x; } } return ; }
路径压缩:
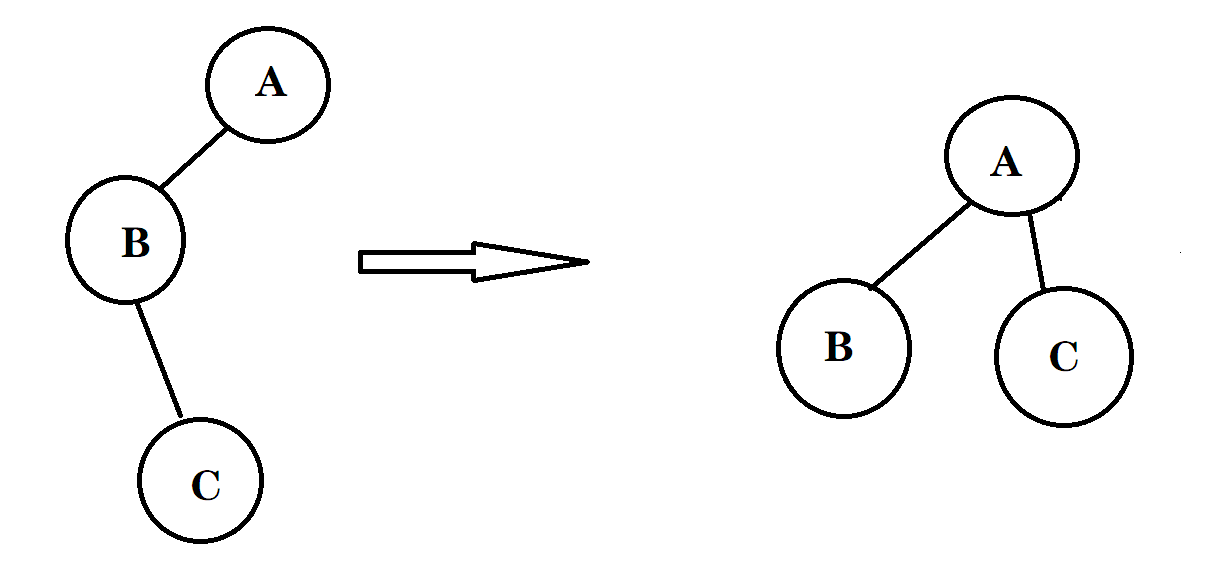
依然是减少树的层数,在查询某个数的根节点过程中,顺便把它的pr[]换掉,指向父亲节点的父亲节点,大大减少了下次查询的次数,效率大大提高。
int find(int p){ while(p != pr[p]){//如果p元素的父亲指针指向的不是自己,说明p并不是集合中的根元素,还需要一直向上查找和路径压缩 //在find查询中嵌入一个路径压缩操作 pr[p]=pr[pr[p]]; //p元素不再选择原来的父亲节点,而是直接选择父亲节点的父亲节点来做为自己新的一个父亲节点 //树的层数被压缩了 p=pr[p];//p压缩完毕后且p并不是根节点,p变成p新的父节点继续进行查找和压缩的同时操作 } return p;//经过while循环后,p=parent[p],一定是一个根节点,且不能够再进行压缩了,我们返回即可 }
递归版:
int find(int x) { if(x!=pr[x]) { int md=pr[x]; pr[x]=find(pr[x]); } return pr[x]; }

