
一、数据库存储概述
1、数据文件类型
· Primary data files:每个数据库都有一个单独的主要数据文件,默认以.mdf扩展名。主要数据文件不仅包含数据信息,还包含与该数据库结构相关的信息。创建数据库 时,数据库结构相关信息不仅存在于master数据库中,同时还包含在primary data file上.
· Secondary data files一个数据库可以有一个或者多个二级数据文件,默认以.ndf为扩展名。一般来说二级数据文件并不是必须的,因为二级数据文件不包含文件位置等信息。
· Transaction logs: 数据库必须至少有一个事务日志文件,默认以.ldf为扩展名。日志是整个数据库的命脉,事务日志不可读的话,将无法对数据库进行任何操作。
当 你在数据库上进行数据操作时,数据并不是直接写入数据文件,而是先将相关操作信息写入事务日志文件。当一个事务结束时,该事务被标记为已提交,但这也并不 意味着数据从日志文件写入了数据文件中。一个标记为已提交的事务仅仅意味着所有与该事务相关的元素已经成功完成。The buffer cache may be updated, but not necessarily the data file.
检查点(checkpoint)会周期性的发生。检查点发生时,是确认所有已提交的事务,不管是在buffer cache或者事务日志中,都被写入相关的数据文件中。检查点(checkpoint)可以通过以下方式来触发:
1、 显示调用checkpoint命令;
2、 Recover Interval 实例设置的周期达到(用来标识多久发生一次checkpoint)
3、 做了数据库备份(在简单模式下);
4、 数据库文件结构被改变(在简单模式下);
5、 数据库引擎被结束。
一般来说,写数据的过程是由系统自动完成的,如下图所示,但数据并不是直接写入.mdf或者.ndf文件中,而是先将有关变化写入事务日志中,这也是数据库中的write-ahead机制。

1. 用户执行insert, update, delete等语句;
2. 数据立即被写入内部日志缓存中(internal log cache)
3. 日志缓存会更新物理事务日志文件,同时将在buffer cache上执行相关变化
4.数据缓存(data buffer)清除所有在缓存上的脏数据,数据文件被更新。
1、恢复模式类型
所有的数据库都可以设置为三个不同的恢复模式:简单(simple), 完全(full),大容量日志(Bulk-Logged).
A完全恢复模式
完 全恢复模式是默认的恢复模式。在完全恢复模式下,需要手工的对事务日志进行管理。使用完全恢复模式的优点是可以恢复到数据库失败或者指定的时间点上。缺点 则是,如果没有进行管理的话,事务日志将会快速增长,消耗磁盘空间。要清除事务日志,只能通过备份事务日志,或者切换至简单模式。
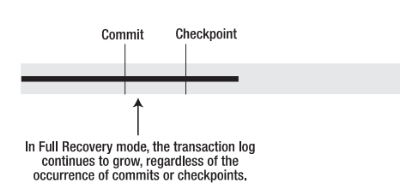
如上图所示,在完全恢复模式下,事务日志会持续增长,而不管checkpoint的发生。
B简单恢复模式
与完全恢复模式不同的是,在简单恢复模式下,在检查点发生时(checkpoint),当前已被提交的事务日志将会被清除。
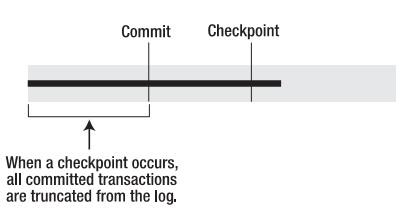
如上图所示,在检查点发生时,所有已提交的事务日志信息将会从事务日志里面删除。
因此,在简单恢复模式下,容易造成数据丢失,因为无法将数据库恢复到失败的那一刻。
需要注意的是,虽然在简单恢复模式下,系统会自动定期清除日志,但这并不意味着事务日志文件不会增长。例如,如果执行一个批量插入操作时,SQL SERVER会将该相关操作当成一个事务,期间产生的日志量在极端情况下,还是非常可观的。
C大容量日志恢复模式
大容量日志恢复模式与完全恢复模式非常相似,但与完全恢复模式不同的是,批量操作将会尽量被最少记录。
批量操作有以下几种类型:
1. 批量导入数据,例如使用BCP(Bulk Copy Import) , BULK INSERT命令 ,或者是在BULK使用OPENROWSET命令;
2. 大对象操作(LOB),例如在TEXT, NTEXT, IMAGE 列上使用WRITETEXT 或者UPDATETEXT;
3. SELECT INTO 字句;
4. CREATE INDEX, ALTER INDEX, ALTER INDEX REBUILD, DBCC REINDEX
在完全恢复模式下,上述操作产生的日志将会是非常大的。而使用大容量日志恢复模式将会阻止不需要或者非预期的日志增长。
在批量操作发生时,SQL SERVER仅仅记录了相关数据页(data page)的ID, 在SQL SERVER中,SQL SERVER pages 都有内部 ID,如5:547。用这种方式,能够将大量的page ID记录在小的日志文件里。

使用大容量日志恢复模式,将会使数据仓库或者有大批量操作的数据库减少很大的空间。但使用大容量恢复模式时,会使得恢复变得比较困难,一般来说,只能恢复到最后的事务日志备份点上,但如果所有的事务日志都被备份后,还是可以恢复成功的。
只要在必要时才使用大容量恢复模式,而且使用完成后,还需切换至完全恢复模式,同时进行备份。
2、改变恢复模式
改变数据库的恢复模式,可以通过以下语句来实现:
ALTER DATABASE database_name SET RECOVEY BULK_LOGGED
也可以通过GUI界面来修改。
改变恢复模式并不需要重启数据库实例。
二、数据库备份介绍
1、备份位置
在SQL Server上,有多种备份位置可以选择,如本地磁盘,网络磁盘,远程地址,磁带等。
各种备份位置均有自己的优点和缺点。
2、逻辑备份设备
在SQL Server上,可以通过创建逻辑备份设备来完成备份。使用逻辑备份设备的好处是,当变更备份地址时,不需要更改备份脚本,只需要更改逻辑备份设备的定义即可。
创建逻辑备份设备的脚本如下:
删除备份设备的脚本:
上述脚本只是删除逻辑备份设备的定义,下述脚本将同时删除备份文件:
使用逻辑备份设备的方法如下:
当然,还可在逻辑备份设备上指定过期时间等备份属性,如:
或:
3、备份集与存储集
每一份备份包含于一个备份集,而一个备份集包含于一个存储集。通过系统GUI进行备份时,SQL Server会自动指定备份集和存储集,目的则是为了简化管理。用T-SQL显示指定则用如下语法:
NAMEs是指备份集名称,MEDIANAME是指存储集名称。
4、全备份
不管恢复模式是哪一个,所有的备份都必须要有一个全备份,特别是日志备份和差异备份,如果没有全备份的话,将无法进行恢复。
简单的全备份脚本如下所示,也可以通过维护计划来指定全备份:
但需要注意的是,上述命令是将数据库备份附加到当前的存在的文件上,如果不存在则创建它,并不会覆盖原有文件。要覆盖同名的备份文件,需要指定INIT参数。
5、日志备份
在完全恢复模式或者大容量日志恢复模式下,日志备份不仅仅是恢复的需要,同时也是手工管理事务日志文件的一种方式。如果从不进行备份的话,在完全恢复模式或者大容量恢复模式下,事务日志将会持续增长,直至消耗完所在磁盘。
日志备份的脚本如下:
需要养成使用.trn为日志备份的扩展名的习惯。
每个在数据库上的动作都会被安排一个Log Sequence Number (LSN)。如果需要还原到指定的时间点,需要有持续的LSN记录。也就是说,在完全恢复模式或者大容量日志模式下,一个不被打断的事务日志备份链是恢复数据库的基本要求。
6、差异备份
使用日志备份来恢复时,无疑是一个很慢的过程,特别是上一个全备份的历史比较悠久时。使用差异备份,便能缩短恢复时间。事实上,差异备份只是BACKUP DATABASE的一个选项,如下:
进行数据库恢复时,先恢复数据库全备份,再恢复数据库差异备份,最后才恢复日志备份。
差 异备份是与上一次全备份紧密相连的,不管期间有多少次日志备份和差异备份,差异备份还是会从上一次全备开始备份。因此,经常会遇到这样的一种情况,在生产 库上需要临时使用数据库时,便用BACKUP DATABASE … TO DISK=’..’进行了一个备份,下一次的差异备份便会以这回的全备为准,如果过后把这个临时全备删除掉后,后面的差异备份就没用了。
差异备份并不意味着磁盘空间肯定会少,这取决于实际情况。当期间大量操作发生时,差异备份还是会变得很大。
7、错误检测
在备份过程中,备份进程会同时验证数据,或者校验不完整页(torn page),或者验证校验和(checksum)。要使用该功能,需要激活该选项。
不完整页检测(Torn-page dection)仅仅检查每一个页看是否已经写完成。如果发现一个页只有部分被写入,那么就将其标记为torn。
校验和验证(checksum validation)是一种新的页验证机制。它会为每个页添加一个值来表明该页实际的大小。虽然看起来是个代价很高影响性能的操作,但事实上,它的效率非常高,与torn-page差不多。
备份进程在备份数据库时,会通过比较在数据库里的和随着备份页写入硬盘时这两个之间的值来进行验证。但是,这个验证并不是自动完成的,需要显示指定,在GUI页面上是个选项。如果通过T-SQL来备份的话,语句如下:
如果备份过程中,发现了错误,SQL Server会错误信息写入MSDB上的SUSPECT_PAGE表里面。同时,在默认情况下,备份行为会停止的(STOP_ON_ERROR),以便管理员排查错误。
但 备份过程中的校验和验证还有另外一个选项(CONTINUE_ON_ERROR),也就是说,如果发现错误,备份过程并不会中断,而是将错误页信息记录在 MSDB..SUSPECT_PAGE上而已。需要注意的是,SUSPECT_PAGE表是有行限制的,最多只能达到1000行,如果达到了的话,备份同 样会失败。
激活校验和验证的话,很明显会影响备份的性能。但还是很有必要的。
8、安全备份
完全备份和日志备份语句还支持使用密码属性,如:
所指定的密码是很容易破解的。因此,如果确实需要对某些备份数据进行加密的话,可以将备份存放于加密的文件系统或者其它安全的存储设备上。
同时,SQL Server还提供了对真实列进行加密的功能。该加密功能是工业标准。
9、条带备份
有些情况下,单独一个硬盘无法存储一个完整的数据库备份时,可以将数据库备份分成多个部分存储在不同的磁盘上,这种备份方式成为条带备份。使用条带备份的优点很明确,就是能很好的利用空间,但如果某部分备份丢失或者损坏,那整个备份将无效。
其语句如下:
上述D盘和E盘上的备份是不可分割的。
10、镜像备份
与条带备份在多个磁盘上保留同一份备份不同的是,镜像备份是在不同磁盘上保留多份备份。其语句如下:
在实际情况下,对日志备份采取镜像备份方式会比较合适。
11、COPY-ONLY 备份
在差异备份里曾提到过,差异备份是建立在上一个全备份的基础上的。因此如果在一个事先安排好的备份计划里,如果在全备份和差异备份之间再进行了一次全备份后,其差异备份会被打断,如果把临时全备份删除掉后,就产生了数据丢失。
在SQL SERVER 2005以后,SQL SERVER提供了一个选项copy-only.使用copy-only选项进行的全备份便不会打算原先的备份计划,语句如下:
三、文件和文件组备份
在SQL SERVER 7.0以后,SQL Server提供了filegroup的概念。文件组不仅仅提供了一个逻辑的存储地址,还允许将不同的表和索引放在不同的文件组上来提高性能和减少备份时间。
在数据存储概述上,提到了数据库有三类数据文件,一般来说,数据库至少需要两个(.mdf和.ldf)或者更多的文件。SQL Server不仅允许有多个文件存在(.ldf),还允许多个文件组存在。
一个文件组可以有多个文件,每个文件需要仔细规划好初始大小及增量。
1、默认文件组
在创建对象时,如果未明确指定文件组,那么该对象将会存放在默认的文件组上。在默认情况下,默认的文件组是primary,但由于primary文件组不仅可以包含用户数据,同时还存储着数据库结构等技术信息,因此一般建议添加额外的一个文件组,并将其指定为默认文件组。
SQL Server只能有一个默认的文件组。
修改默认文件组的语句如下:
2、为对象指定文件组
当创建表或者索引时,不管是用户还是系统都需要将表或索引放在某个文件组上。如果在创建表或索引时指定文件组,那么表或索引将会存储在指定的文件组上,而不是默认的文件组。
其指定语句如下:
也可以通过GUI创建表的页面来指定文件组。
3、将对象迁移至指定文件组
如果需要变更对象的存储位置,最简单的方式则是通过GUI属性页面来进行修改通过该方法,可以直观的看到对象的迁移过程。
同时也可以通过T-SQL来修改,例如:
4、备份数据文件
备份数据文件同样可以通过BACKUP DATABASE语句来实现。如下:
上述语句相当于数据文件级别的全备份,与数据库级别的备份类似,文件级别上的备份也有差异备份,当然前提是要有相对应的文件全备份。
差异备份的语句如下:
5、备份文件组
与单独备份文件类似,也可以对文件组进行类似的备份操作。备份文件组的方式也有两种,一种是通过GUI界面指定,一种则是通过T-SQL。
T-SQL的语句如下:
6、不完全备份(partial backup)
在文件组备份上,不完全备份其实相当于完全备份,可以通过指定关键字READ_WRITE_FILEGROUPS来实现不完全备份。
语句如下:
显示指定RECOVERY 或者NORECOVERY是个良好的习惯。
2、在RECOVERY过程中的可用性
一般情况下,如果SQL Server处于Recovery过程中时,用户是无法使用数据库的。但可以通过设置fast recovery使得用户在Recovery中使用数据库。
在所有已提交的事务都被ROLL FORWARD后,数据库就是联机状态。
一 般情况下,SQL Server强制已提交的事务写入数据库中,这个过程叫做检查点(CHECKPOINT)。可以通过强制使用CHECKPOINT命令来触发,默认则是以 RECOVERY INTERVAL为周期,可以通过SP_CONFIGURE命令来设置RECOVERY INTERVAL。
默认情况下,RECOVERY INTERVAL 设置为0,表示SQL Server根据需要动态管理CHECKPOINT的发生。
3、备份文件里面的信息
在primary文件里,存储着与数据库结构有关的一些信息,如文件位置等。因此备份后,这些信息同样保留在备份文件里面。如果要恢复到不同的磁盘上或服务器后,需要进行额外的更改。
在SQL Server里,提供了 RESTORE HEADERONLY, RESTORE FILELISTONLY, RESTORE LABELONLY, RESTORE VERIFYONLY 等命令来读取备份文件的信息。也可以通过MSDB里的表来获取备份集的相关信息。
A.RESTORE HEADERONLY
各字段的含义可以查看联机丛书。
B.RESOTRE FILELISTONLY
C.RESOTRE LABELONLY
D.RESOTORE VERIFYONLY
4、从全备份中恢复
不管是在简单恢复模式或者完全恢复模式下和大容量日志模式下,对全备份恢复都是差不多的。最大的差别在于完全恢复模式与大容量日志恢复模式,除了需要恢复全备份外,还需要指定WITH NORECOVERY,以便后续的差异备份和日志备份的恢复。
当然,在简单恢复模式下,也是有差异备份的,这种情况下,同样需要指定WITH NORECOVERY。
需要注意的是,在做恢复之前,应该养成对当前日志进行备份的习惯,否则容易造成数据丢失。SQL Server虽然提供REPLACE选项以便强制恢复,但这样子末尾日志就丢掉了。
通常,如果未对当前日志进行备份,那么会收到如下错误
上述错误,提到了使用WITH REPLACE 或者WITH STOPAT命令来完成恢复,但应尽量避免使用这两个命令。
如果要将数据库恢复到不同的磁盘上,可以通过GUI页面指定,也可以通过T-SQL语句来实现。
T-SQL实现的方式如下:
5、恢复到指定的时间点
要恢复到指定的时间点有三种选择,一种是通过明确指定时间,一种通过指定LSN号,另外一种则是通过创建和指定log marks。
A. TIME
通常情况下,恢复都会有要求恢复到指定时间点的要求,可通过GUI界面来实现,也可以通过T-SQL 来实现
B. LSN
如果知道确切的LSN号,也可以通过LSN号来恢复指定的LSN。获取LSN相关信息,可以通过RESOTRE HEADERONLY。这种方式只能通过T-SQL来实现。
C. Log Marks
也可以通过创建Log Mark,可以恢复至指定的Log Marks。例如,创建了一个logmarkexample,则在恢复时,恢复到logmarkexample。
6、对镜像备份或条带备份的恢复
对镜像备份而言,每一份备份都是一样的,因此恢复任何一份备份都可以完成恢复。
对条带备份而言,则需要同时指定所有的条带备份,这种备份可以比单独一个备份来得快。
条带备份例子如下:
7、恢复数据页
在SQL Server2005以后,SQL Server提供了对数据页恢复的功能。对数据页恢复可以在联机或者脱机状态下进行
但只能对实际用户数据页进行恢复,而其他的页则无法通过备份来恢复。如Global Allocation Map(GAM), Secondary Global Allocation Map(SGAM), Page Free Space(PFS)等。
恢复数据页相当于进行完全恢复,不同的是需要指定具体的页面。
数据页可以通过MSDB..SUSPECT_PAGE或者DBCC CHECKDB来查找。
8、对系统数据库的恢复
系统数据库存储着一个SQL Server实例上相关数据库的信息,如果丢失,将会带来更大的损失。
A. MASTER
Master数据库的恢复与其他数据库的恢复是不同的。要恢复MASTER数据库,需要从将SQL Server切换至单用户模式,如果无法切换,则停止SQL Server服务,然后用sqlserver –m命令行启动。
当然,也可以用net start “服务器名” 来启动SQL Server服务。启动后,再用SQLCMD命令进行还原
B. MSDB
在MSDB里面存储得比较多的是SQL Agent里的内容,如作业,调度,操作员,警告等信息;同时还存放SQL Server Integration Service(SSIS)等信息。
其恢复过程与普通数据库恢复过程是一样的。并且由于是在简单模式下,因而其恢复过程更加简单。
C. MODEL
Model数据库用来存放创建数据库时需要的信息,如果有使用MODEL数据库的话,也需要对其进行备份和恢复。
备份与恢复的过程与普通数据库一致。
D. Tempdb
Tempdb是不需要备份和恢复的,在每次的启动过程中,SQL Server会自动清除tempdb,并重新启动tempdb。在tempdb上需要注意的是其空间规划,因为某些情况下tempdb会变得非常大,耗尽空间,最终导致SQL Server关掉。
若要修改tempdb的存储路径,请使用如下语句:
E. Resource
Resource是SQL Server2005以后新引进的一个数据库,将以前存放于master等其他系统数据库的部分信息存放于Resource数据库里。
对Resource不能通过T-SQL或者GUI备份,因为看不到它,要对其进行备份,只能通过手工直接拷贝其物理文件。
6、数据文件备份的恢复
在第三部份里面提到了文件的备份,这种单个或多个文件的备份,其恢复方式与数据库恢复类似。
但要养成一个良好的习惯,在恢复前,备份当前的日志文件。
接着对需要还原的文件进行还原,如
如果在数据文件上还有差异备份,日志恢复前进行差异备份恢复,如:
7、文件组的恢复
与数据文件恢复原理是一致的,只不过是将具体文件文件组。
五、小结
对SQL Server来讲,从2005开始,提供了很多智能化的备份方式,如可以通过制定维护计划来进行备份,并自动产生备份作业,通过结合SQL Mail就能够方便DBA建立一个良好的备份计划。但备份是与恢复结合在一起的,备份的目的是为了减少数据丢失,而要求数据零丢失,又需要间隔更短的备份 周期,进而影响性能。因此,一个良好的备份计划应该要是多种因素的折中。
一个良好的备份/恢复计划,应该要做好如下几点:
1、 文档化的数据保护需求;
2、 文档化的日/周/月的备份计划;
3、 文档化的恢复过程;
4、 文档化的测试及验证结果。
可见,关键在于文档化,养成良好的文档功能是很必要的。
1、数据文件类型
· Primary data files:每个数据库都有一个单独的主要数据文件,默认以.mdf扩展名。主要数据文件不仅包含数据信息,还包含与该数据库结构相关的信息。创建数据库 时,数据库结构相关信息不仅存在于master数据库中,同时还包含在primary data file上.
· Secondary data files一个数据库可以有一个或者多个二级数据文件,默认以.ndf为扩展名。一般来说二级数据文件并不是必须的,因为二级数据文件不包含文件位置等信息。
· Transaction logs: 数据库必须至少有一个事务日志文件,默认以.ldf为扩展名。日志是整个数据库的命脉,事务日志不可读的话,将无法对数据库进行任何操作。
当 你在数据库上进行数据操作时,数据并不是直接写入数据文件,而是先将相关操作信息写入事务日志文件。当一个事务结束时,该事务被标记为已提交,但这也并不 意味着数据从日志文件写入了数据文件中。一个标记为已提交的事务仅仅意味着所有与该事务相关的元素已经成功完成。The buffer cache may be updated, but not necessarily the data file.
检查点(checkpoint)会周期性的发生。检查点发生时,是确认所有已提交的事务,不管是在buffer cache或者事务日志中,都被写入相关的数据文件中。检查点(checkpoint)可以通过以下方式来触发:
1、 显示调用checkpoint命令;
2、 Recover Interval 实例设置的周期达到(用来标识多久发生一次checkpoint)
3、 做了数据库备份(在简单模式下);
4、 数据库文件结构被改变(在简单模式下);
5、 数据库引擎被结束。
一般来说,写数据的过程是由系统自动完成的,如下图所示,但数据并不是直接写入.mdf或者.ndf文件中,而是先将有关变化写入事务日志中,这也是数据库中的write-ahead机制。
1. 用户执行insert, update, delete等语句;
2. 数据立即被写入内部日志缓存中(internal log cache)
3. 日志缓存会更新物理事务日志文件,同时将在buffer cache上执行相关变化
4.数据缓存(data buffer)清除所有在缓存上的脏数据,数据文件被更新。
1、恢复模式类型
所有的数据库都可以设置为三个不同的恢复模式:简单(simple), 完全(full),大容量日志(Bulk-Logged).
A完全恢复模式
完 全恢复模式是默认的恢复模式。在完全恢复模式下,需要手工的对事务日志进行管理。使用完全恢复模式的优点是可以恢复到数据库失败或者指定的时间点上。缺点 则是,如果没有进行管理的话,事务日志将会快速增长,消耗磁盘空间。要清除事务日志,只能通过备份事务日志,或者切换至简单模式。
如上图所示,在完全恢复模式下,事务日志会持续增长,而不管checkpoint的发生。
B简单恢复模式
与完全恢复模式不同的是,在简单恢复模式下,在检查点发生时(checkpoint),当前已被提交的事务日志将会被清除。
如上图所示,在检查点发生时,所有已提交的事务日志信息将会从事务日志里面删除。
因此,在简单恢复模式下,容易造成数据丢失,因为无法将数据库恢复到失败的那一刻。
需要注意的是,虽然在简单恢复模式下,系统会自动定期清除日志,但这并不意味着事务日志文件不会增长。例如,如果执行一个批量插入操作时,SQL SERVER会将该相关操作当成一个事务,期间产生的日志量在极端情况下,还是非常可观的。
C大容量日志恢复模式
大容量日志恢复模式与完全恢复模式非常相似,但与完全恢复模式不同的是,批量操作将会尽量被最少记录。
批量操作有以下几种类型:
1. 批量导入数据,例如使用BCP(Bulk Copy Import) , BULK INSERT命令 ,或者是在BULK使用OPENROWSET命令;
2. 大对象操作(LOB),例如在TEXT, NTEXT, IMAGE 列上使用WRITETEXT 或者UPDATETEXT;
3. SELECT INTO 字句;
4. CREATE INDEX, ALTER INDEX, ALTER INDEX REBUILD, DBCC REINDEX
在完全恢复模式下,上述操作产生的日志将会是非常大的。而使用大容量日志恢复模式将会阻止不需要或者非预期的日志增长。
在批量操作发生时,SQL SERVER仅仅记录了相关数据页(data page)的ID, 在SQL SERVER中,SQL SERVER pages 都有内部 ID,如5:547。用这种方式,能够将大量的page ID记录在小的日志文件里。
使用大容量日志恢复模式,将会使数据仓库或者有大批量操作的数据库减少很大的空间。但使用大容量恢复模式时,会使得恢复变得比较困难,一般来说,只能恢复到最后的事务日志备份点上,但如果所有的事务日志都被备份后,还是可以恢复成功的。
只要在必要时才使用大容量恢复模式,而且使用完成后,还需切换至完全恢复模式,同时进行备份。
2、改变恢复模式
改变数据库的恢复模式,可以通过以下语句来实现:
ALTER DATABASE database_name SET RECOVEY BULK_LOGGED
也可以通过GUI界面来修改。
改变恢复模式并不需要重启数据库实例。
二、数据库备份介绍
1、备份位置
在SQL Server上,有多种备份位置可以选择,如本地磁盘,网络磁盘,远程地址,磁带等。
各种备份位置均有自己的优点和缺点。
2、逻辑备份设备
在SQL Server上,可以通过创建逻辑备份设备来完成备份。使用逻辑备份设备的好处是,当变更备份地址时,不需要更改备份脚本,只需要更改逻辑备份设备的定义即可。
创建逻辑备份设备的脚本如下:
- SQL code
- EXEC sp_adddumpdevice @devtype=’disk’,@logicalname=’MYBackup’,@physicalname=’D:\backup\mydb.bak’
删除备份设备的脚本:
- SQL code
- Sp_dropdevice @logicalname=’MYBackup’
上述脚本只是删除逻辑备份设备的定义,下述脚本将同时删除备份文件:
- SQL code
- Sp_dropdevice @logicalname=’MYBackup’,@devfile=’DELFILE’
使用逻辑备份设备的方法如下:
- SQL code
- Backup database mydb to MYBackup
当然,还可在逻辑备份设备上指定过期时间等备份属性,如:
- SQL code
- Backup database mydb to MYBackup WITH EXPIREDATE=’13/01/2010’
或:
- SQL code
- BACKUP DATABASE mydb to MYBackup WITH RETAINDAYS=7
3、备份集与存储集
每一份备份包含于一个备份集,而一个备份集包含于一个存储集。通过系统GUI进行备份时,SQL Server会自动指定备份集和存储集,目的则是为了简化管理。用T-SQL显示指定则用如下语法:
- SQL code
- BACKUP DATABASE mydb to MYBackup WITH RETAINDAYS=7,
NAME=’FULL’,
MEDIANAME=’ALLBackups’
NAMEs是指备份集名称,MEDIANAME是指存储集名称。
4、全备份
不管恢复模式是哪一个,所有的备份都必须要有一个全备份,特别是日志备份和差异备份,如果没有全备份的话,将无法进行恢复。
简单的全备份脚本如下所示,也可以通过维护计划来指定全备份:
- SQL code
- BACKUP DATABASE mydb to DISK=’D:\Backup\mydb.bak’
但需要注意的是,上述命令是将数据库备份附加到当前的存在的文件上,如果不存在则创建它,并不会覆盖原有文件。要覆盖同名的备份文件,需要指定INIT参数。
- SQL code
- BACKUP DATABASE mydb to DISK=’D:\Backup\mydb.bak’ WITH INIT
5、日志备份
在完全恢复模式或者大容量日志恢复模式下,日志备份不仅仅是恢复的需要,同时也是手工管理事务日志文件的一种方式。如果从不进行备份的话,在完全恢复模式或者大容量恢复模式下,事务日志将会持续增长,直至消耗完所在磁盘。
日志备份的脚本如下:
- SQL code
- BACKUP LOG mydb_log TO DISK=’D:\backup\mydb.trn’
需要养成使用.trn为日志备份的扩展名的习惯。
每个在数据库上的动作都会被安排一个Log Sequence Number (LSN)。如果需要还原到指定的时间点,需要有持续的LSN记录。也就是说,在完全恢复模式或者大容量日志模式下,一个不被打断的事务日志备份链是恢复数据库的基本要求。
6、差异备份
使用日志备份来恢复时,无疑是一个很慢的过程,特别是上一个全备份的历史比较悠久时。使用差异备份,便能缩短恢复时间。事实上,差异备份只是BACKUP DATABASE的一个选项,如下:
- SQL code
- BACKUP DATABASE mydb TO DISK=’D:\backup\mydb.dif’ WITH DIFFERENTIAL,INIT
进行数据库恢复时,先恢复数据库全备份,再恢复数据库差异备份,最后才恢复日志备份。
差 异备份是与上一次全备份紧密相连的,不管期间有多少次日志备份和差异备份,差异备份还是会从上一次全备开始备份。因此,经常会遇到这样的一种情况,在生产 库上需要临时使用数据库时,便用BACKUP DATABASE … TO DISK=’..’进行了一个备份,下一次的差异备份便会以这回的全备为准,如果过后把这个临时全备删除掉后,后面的差异备份就没用了。
差异备份并不意味着磁盘空间肯定会少,这取决于实际情况。当期间大量操作发生时,差异备份还是会变得很大。
7、错误检测
在备份过程中,备份进程会同时验证数据,或者校验不完整页(torn page),或者验证校验和(checksum)。要使用该功能,需要激活该选项。
不完整页检测(Torn-page dection)仅仅检查每一个页看是否已经写完成。如果发现一个页只有部分被写入,那么就将其标记为torn。
校验和验证(checksum validation)是一种新的页验证机制。它会为每个页添加一个值来表明该页实际的大小。虽然看起来是个代价很高影响性能的操作,但事实上,它的效率非常高,与torn-page差不多。
备份进程在备份数据库时,会通过比较在数据库里的和随着备份页写入硬盘时这两个之间的值来进行验证。但是,这个验证并不是自动完成的,需要显示指定,在GUI页面上是个选项。如果通过T-SQL来备份的话,语句如下:
- SQL code
- BACKUP DATABASE mydb TO DISK=’D:\data\mydb.bak’ WITH CHECKSUM
如果备份过程中,发现了错误,SQL Server会错误信息写入MSDB上的SUSPECT_PAGE表里面。同时,在默认情况下,备份行为会停止的(STOP_ON_ERROR),以便管理员排查错误。
但 备份过程中的校验和验证还有另外一个选项(CONTINUE_ON_ERROR),也就是说,如果发现错误,备份过程并不会中断,而是将错误页信息记录在 MSDB..SUSPECT_PAGE上而已。需要注意的是,SUSPECT_PAGE表是有行限制的,最多只能达到1000行,如果达到了的话,备份同 样会失败。
激活校验和验证的话,很明显会影响备份的性能。但还是很有必要的。
8、安全备份
完全备份和日志备份语句还支持使用密码属性,如:
- SQL code
- BACKUP DATABASE mydb TO DISK=’D:\mydb.bak’ WITH PASSWORD=’mydb’
所指定的密码是很容易破解的。因此,如果确实需要对某些备份数据进行加密的话,可以将备份存放于加密的文件系统或者其它安全的存储设备上。
同时,SQL Server还提供了对真实列进行加密的功能。该加密功能是工业标准。
9、条带备份
有些情况下,单独一个硬盘无法存储一个完整的数据库备份时,可以将数据库备份分成多个部分存储在不同的磁盘上,这种备份方式成为条带备份。使用条带备份的优点很明确,就是能很好的利用空间,但如果某部分备份丢失或者损坏,那整个备份将无效。
其语句如下:
- SQL code
- BACKUP DATABASE mydb TO DISK=’D:\mydb.bak’,
DISK=’E:\mydb.bak’ WITH INIT,CHECKSUM,
CONTINUE_ON_ERROR
上述D盘和E盘上的备份是不可分割的。
10、镜像备份
与条带备份在多个磁盘上保留同一份备份不同的是,镜像备份是在不同磁盘上保留多份备份。其语句如下:
- SQL code
- BACKUP DATABASE mydb TO DISK=’D:\mydb.bak’
MIRROR TO DISK=’E:\mydb.bak’
WITH INIT,CHECKSUM,CONTINUE_ON_ERROR
在实际情况下,对日志备份采取镜像备份方式会比较合适。
11、COPY-ONLY 备份
在差异备份里曾提到过,差异备份是建立在上一个全备份的基础上的。因此如果在一个事先安排好的备份计划里,如果在全备份和差异备份之间再进行了一次全备份后,其差异备份会被打断,如果把临时全备份删除掉后,就产生了数据丢失。
在SQL SERVER 2005以后,SQL SERVER提供了一个选项copy-only.使用copy-only选项进行的全备份便不会打算原先的备份计划,语句如下:
- SQL code
- BACKUP DATABASE mydb TO DISK=’D:\mydb.bak’
WITH INIT,CHECKSUM,COPY_ONLY
三、文件和文件组备份
在SQL SERVER 7.0以后,SQL Server提供了filegroup的概念。文件组不仅仅提供了一个逻辑的存储地址,还允许将不同的表和索引放在不同的文件组上来提高性能和减少备份时间。
在数据存储概述上,提到了数据库有三类数据文件,一般来说,数据库至少需要两个(.mdf和.ldf)或者更多的文件。SQL Server不仅允许有多个文件存在(.ldf),还允许多个文件组存在。
一个文件组可以有多个文件,每个文件需要仔细规划好初始大小及增量。
1、默认文件组
在创建对象时,如果未明确指定文件组,那么该对象将会存放在默认的文件组上。在默认情况下,默认的文件组是primary,但由于primary文件组不仅可以包含用户数据,同时还存储着数据库结构等技术信息,因此一般建议添加额外的一个文件组,并将其指定为默认文件组。
SQL Server只能有一个默认的文件组。
修改默认文件组的语句如下:
- SQL code
- ALTER DATABASE mydb MODIFY FILEGROUP mydb DEFAULT;
2、为对象指定文件组
当创建表或者索引时,不管是用户还是系统都需要将表或索引放在某个文件组上。如果在创建表或索引时指定文件组,那么表或索引将会存储在指定的文件组上,而不是默认的文件组。
其指定语句如下:
- SQL code
- CREATE TABLE test( [id] int,[notes] text) on mydbdata
也可以通过GUI创建表的页面来指定文件组。
3、将对象迁移至指定文件组
如果需要变更对象的存储位置,最简单的方式则是通过GUI属性页面来进行修改通过该方法,可以直观的看到对象的迁移过程。
同时也可以通过T-SQL来修改,例如:
- SQL code
- ALTER TABLE test drop constraint PK_test WITH (MOVE TO DATA)
4、备份数据文件
备份数据文件同样可以通过BACKUP DATABASE语句来实现。如下:
- SQL code
- BACKUP DATABASE mydb FILE=’D:\Data\mydb.ndf’ TO DISK=’E:\Backup\mydbdata.bak’
上述语句相当于数据文件级别的全备份,与数据库级别的备份类似,文件级别上的备份也有差异备份,当然前提是要有相对应的文件全备份。
差异备份的语句如下:
- SQL code
- BACKUP DATABASE mydb FILE=’D:\Data\mydb.ndf’
WITH DIFFERENTIAL
TO DISK=’E:\Backup\mydbdata_dif.bak’
5、备份文件组
与单独备份文件类似,也可以对文件组进行类似的备份操作。备份文件组的方式也有两种,一种是通过GUI界面指定,一种则是通过T-SQL。
T-SQL的语句如下:
- SQL code
- BACKUP DATABASE mydb FILEGROUP=’PRIMARY’ TO DISK=’E:\Backup\mydbpri.bak’
6、不完全备份(partial backup)
在文件组备份上,不完全备份其实相当于完全备份,可以通过指定关键字READ_WRITE_FILEGROUPS来实现不完全备份。
语句如下:
- SQL code
- BACKUP DATABASE mydb READ_WRITE_FILEGROUPS TO DISK=’D:\mydb.bak’
那不完全备份到底是什么意思呢?什么时候需要不完全备份?如果对一个文件组设置了只读,而这只读的文件组又需要进行一次备份,这时,可以不用BACKUP DATABASE语句进行备份,只需要挑个时间停止实例,然后执行不完全备份。
四、数据恢复
1、Restore vs. Recovery
Restore和Recovery是两个不同的概念,但在数据恢复过程中又是紧密联系的。
Restore相当于从备份集中重建整个或者部分数据库,Restore是无法改变数据库状态的,如脱机和联机等。
Recovery 则是将数据库从脱机状态恢复到联机状态中供用户使用。Recovery在SQL Server启动时也会发生,在数据库启动过程中,SQL Server会检查事务日志,看是否存在已提交或未提交的事务,如果发现在最后一次检查点发生后,还有已提交的事务,则SQL Server会对这些事务进行REDO(ROLL FORWARD);而如果发现未提交的事务,则进行UNDO(ROLL BACK)。
一旦对数据库进行了Recovery,则将无法再进行Restore操作。
Recovery 事实上是Restore的一个选项,默认情况下,进行Restore操作时,SQL Server还会进行Recovery操作。在单独对全备份进行恢复时,可以不用考虑Recovery,但如果后续仍有日志备份或差异备份需要恢复,则必 须注意Recovery选项的选择。
数据库恢复的语句如下:
- SQL code
- RESTORE DATABASE mydb FROM mydbdevice WITH RECOVERY
显示指定RECOVERY 或者NORECOVERY是个良好的习惯。
2、在RECOVERY过程中的可用性
一般情况下,如果SQL Server处于Recovery过程中时,用户是无法使用数据库的。但可以通过设置fast recovery使得用户在Recovery中使用数据库。
在所有已提交的事务都被ROLL FORWARD后,数据库就是联机状态。
一 般情况下,SQL Server强制已提交的事务写入数据库中,这个过程叫做检查点(CHECKPOINT)。可以通过强制使用CHECKPOINT命令来触发,默认则是以 RECOVERY INTERVAL为周期,可以通过SP_CONFIGURE命令来设置RECOVERY INTERVAL。
- SQL code
- sp_configure 'Show Advanced Options',1
sp_configure 'recovery interval',5
RECONFIGURE WITH OVERRIDE
sp_configure 'Show Advanced Options',0
默认情况下,RECOVERY INTERVAL 设置为0,表示SQL Server根据需要动态管理CHECKPOINT的发生。
3、备份文件里面的信息
在primary文件里,存储着与数据库结构有关的一些信息,如文件位置等。因此备份后,这些信息同样保留在备份文件里面。如果要恢复到不同的磁盘上或服务器后,需要进行额外的更改。
在SQL Server里,提供了 RESTORE HEADERONLY, RESTORE FILELISTONLY, RESTORE LABELONLY, RESTORE VERIFYONLY 等命令来读取备份文件的信息。也可以通过MSDB里的表来获取备份集的相关信息。
A.RESTORE HEADERONLY
- SQL code
- RESTORE HEADERONLY
FROM DISK='D:\family_20100108.bak'
各字段的含义可以查看联机丛书。
B.RESOTRE FILELISTONLY
- SQL code
RESTORE FILELISTONLY
FROM DISK='D:\family_20100108.bak'
C.RESOTRE LABELONLY
- SQL code
- RESTORE LABELONLY
FROM DISK='D:\family_20100108.bak'
D.RESOTORE VERIFYONLY
- SQL code
- RESTORE VERIFYONLY
FROM DISK='D:\family_20100108.bak'
4、从全备份中恢复
不管是在简单恢复模式或者完全恢复模式下和大容量日志模式下,对全备份恢复都是差不多的。最大的差别在于完全恢复模式与大容量日志恢复模式,除了需要恢复全备份外,还需要指定WITH NORECOVERY,以便后续的差异备份和日志备份的恢复。
当然,在简单恢复模式下,也是有差异备份的,这种情况下,同样需要指定WITH NORECOVERY。
需要注意的是,在做恢复之前,应该养成对当前日志进行备份的习惯,否则容易造成数据丢失。SQL Server虽然提供REPLACE选项以便强制恢复,但这样子末尾日志就丢掉了。
通常,如果未对当前日志进行备份,那么会收到如下错误
上述错误,提到了使用WITH REPLACE 或者WITH STOPAT命令来完成恢复,但应尽量避免使用这两个命令。
如果要将数据库恢复到不同的磁盘上,可以通过GUI页面指定,也可以通过T-SQL语句来实现。
T-SQL实现的方式如下:
- SQL code
- RESTORE DATABASE Family
FROM DISK='D:\family_20100108.bak'
WITH MOVE 'Family'TO 'D:\Family.mdf',
MOVE 'Family_Log' TO 'D:\Family.ldf'
WITH RECOVERY
5、恢复到指定的时间点
要恢复到指定的时间点有三种选择,一种是通过明确指定时间,一种通过指定LSN号,另外一种则是通过创建和指定log marks。
A. TIME
通常情况下,恢复都会有要求恢复到指定时间点的要求,可通过GUI界面来实现,也可以通过T-SQL 来实现
- SQL code
- RESTORE DATABASE Family
FROM DISK='D:\family_20100108.bak'
WITH NORECOVERY
RESTORE LOG Family
FROM DISK='D:\family_20100108.trn'
WITH RECOVERY,STOPAT 'jan 8,2009 3:10pm'
B. LSN
如果知道确切的LSN号,也可以通过LSN号来恢复指定的LSN。获取LSN相关信息,可以通过RESOTRE HEADERONLY。这种方式只能通过T-SQL来实现。
- SQL code
- RESTORE DATABASE Family
FROM DISK='D:\family_20100108.bak'
WITH NORECOVRY
RESTORE LOG Family
FROM DISK='D:\family_20100108.trn'
WITH RECOVRY,STOPATMARK LSN:2433:5422
C. Log Marks
也可以通过创建Log Mark,可以恢复至指定的Log Marks。例如,创建了一个logmarkexample,则在恢复时,恢复到logmarkexample。
- SQL code
- RESTORE DATABASE Family
FROM DISK='D:\family_20100108.bak'
WITH NORECOVRY
RESTORE LOG Family
FROM DISK='D:\family_20100108.trn'
WITH RECOVRY,STOPATMARK 'logmarkexample'
6、对镜像备份或条带备份的恢复
对镜像备份而言,每一份备份都是一样的,因此恢复任何一份备份都可以完成恢复。
对条带备份而言,则需要同时指定所有的条带备份,这种备份可以比单独一个备份来得快。
条带备份例子如下:
- SQL code
- RESTORE DATABASE Family
FROM DISK='D:\family_20100108.bak',
DISK='D:\family_20100108.bak'
WITH NORECOVRY
7、恢复数据页
在SQL Server2005以后,SQL Server提供了对数据页恢复的功能。对数据页恢复可以在联机或者脱机状态下进行
但只能对实际用户数据页进行恢复,而其他的页则无法通过备份来恢复。如Global Allocation Map(GAM), Secondary Global Allocation Map(SGAM), Page Free Space(PFS)等。
恢复数据页相当于进行完全恢复,不同的是需要指定具体的页面。
- SQL code
- RESTORE DATABASE Family PAGE '20:1570,20:1571,20:1572'
FROM DISK='D:\family_20100108.bak'
WITH NORECOVRY
数据页可以通过MSDB..SUSPECT_PAGE或者DBCC CHECKDB来查找。
8、对系统数据库的恢复
系统数据库存储着一个SQL Server实例上相关数据库的信息,如果丢失,将会带来更大的损失。
A. MASTER
Master数据库的恢复与其他数据库的恢复是不同的。要恢复MASTER数据库,需要从将SQL Server切换至单用户模式,如果无法切换,则停止SQL Server服务,然后用sqlserver –m命令行启动。
当然,也可以用net start “服务器名” 来启动SQL Server服务。启动后,再用SQLCMD命令进行还原
B. MSDB
在MSDB里面存储得比较多的是SQL Agent里的内容,如作业,调度,操作员,警告等信息;同时还存放SQL Server Integration Service(SSIS)等信息。
其恢复过程与普通数据库恢复过程是一样的。并且由于是在简单模式下,因而其恢复过程更加简单。
C. MODEL
Model数据库用来存放创建数据库时需要的信息,如果有使用MODEL数据库的话,也需要对其进行备份和恢复。
备份与恢复的过程与普通数据库一致。
D. Tempdb
Tempdb是不需要备份和恢复的,在每次的启动过程中,SQL Server会自动清除tempdb,并重新启动tempdb。在tempdb上需要注意的是其空间规划,因为某些情况下tempdb会变得非常大,耗尽空间,最终导致SQL Server关掉。
若要修改tempdb的存储路径,请使用如下语句:
- SQL code
- use master
go
Alter database tempdb modify file (name = tempdev, filename = 'E:\Sqldata\tempdb.mdf')
go
Alter database tempdb modify file (name = templog, filename = 'E:\Sqldata\templog.ldf')
Go
E. Resource
Resource是SQL Server2005以后新引进的一个数据库,将以前存放于master等其他系统数据库的部分信息存放于Resource数据库里。
对Resource不能通过T-SQL或者GUI备份,因为看不到它,要对其进行备份,只能通过手工直接拷贝其物理文件。
6、数据文件备份的恢复
在第三部份里面提到了文件的备份,这种单个或多个文件的备份,其恢复方式与数据库恢复类似。
但要养成一个良好的习惯,在恢复前,备份当前的日志文件。
- SQL code
- BACKUP LOG Family
TO DISK='E:\Familylog.bak'
WITH NORECOVERY
接着对需要还原的文件进行还原,如
- SQL code
- RESTORE DATABASE Family
FILE='D:\DATA\Family.mdf'
FROM DISK='E:\Familyprimary.bak'
WITH NORECOVERY
RESTORE LOG Family
FROM DISK='E:\Familylog.bak'
WITH NORECOVERY
RESTORE DATABASE Family
WITH RECOVERY
如果在数据文件上还有差异备份,日志恢复前进行差异备份恢复,如:
- SQL code
- RESTORE DATABASE Family
FILE='D:\DATA\Family.mdf'
FROM DISK='E:\Familyprimary.bak'
WITH NORECOVERY
RESTORE DATABASE Family
FILE='D:\DATA\Family.mdf'
FROM DISK='E:\Familyprimay.dif'
WITH NORECOVERY
RESTORE LOG Family
FROM DISK='E:\Familylog.bak'
WITH NORECOVERY
RESTORE DATABASE Family
WITH RECOVERY
7、文件组的恢复
与数据文件恢复原理是一致的,只不过是将具体文件文件组。
- SQL code
- BACKUP LOG Family
TO DISK='E:\Familylog.bak'
WITH NORECOVERY
RESTORE DATABASE Family
FILEGROUP='PRIMARY'
FROM DISK='E:\Familyprimary.bak'
WITH NORECOVERY
RESTORE LOG Family
FROM DISK='E:\Familylog.bak'
WITH NORECOVERY
RESTORE DATABASE Family
WITH RECOVERY
五、小结
对SQL Server来讲,从2005开始,提供了很多智能化的备份方式,如可以通过制定维护计划来进行备份,并自动产生备份作业,通过结合SQL Mail就能够方便DBA建立一个良好的备份计划。但备份是与恢复结合在一起的,备份的目的是为了减少数据丢失,而要求数据零丢失,又需要间隔更短的备份 周期,进而影响性能。因此,一个良好的备份计划应该要是多种因素的折中。
一个良好的备份/恢复计划,应该要做好如下几点:
1、 文档化的数据保护需求;
2、 文档化的日/周/月的备份计划;
3、 文档化的恢复过程;
4、 文档化的测试及验证结果。
可见,关键在于文档化,养成良好的文档功能是很必要的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号