
导出
关于awr报告的导出,上一篇博客已经进行过讲述了。博客链接地址:https://www.cnblogs.com/liyasong/p/oracle_report1.html 这里就不再赘述。
各个字段的含义
awr报告的HTML报告,可以在网页上直接打开。这里,按照每一部分介绍下awr报告的各个字段。
1.报告基本信息
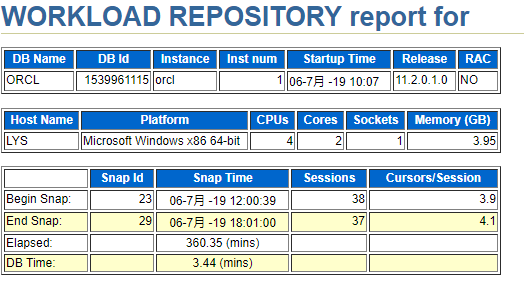
这一部分,是报告的一些基本信息。分别包括:
上面部分,数据库物理环境相关信息。
第一行,DB Name 数据库名(数据库名是存储在控制文件中,代表数据库所有物理文件的总称)。DB Id 数据库id(数据库的dbid可能在数据库文件恢复中需要用到,查询数据库DB Id的sql语句为:select dbId from v$database;)。Instance 实例名 (实例名(sid),写数据库地址的时候,192.168.*.*:1521/orcl 这里的orcl就是实例名)初始实例编号(暂时不知道干什么用的,欢迎指导)。Startup Time 数据库启动时间(本次导出awr报告对应时段的数据库启动时间)。Release 数据库版本(不同的版本awr报告不全一样,这里是11.2版本的数据库)。RAC real application cluster 数据库自己的集群系统(分布式数据库,安装设置好集群后,从集群的任何一个节点数据库都可以同步到其他节点,这里没有开启)
第二行,HostName 服务器名(oracle所在服务器的名称,链接的时候需要验证的一个信息)。Platform 操作系统(orale的安装环境,什么系统,多少位)。CPUs(服务器多少颗cpu)。Cores(服务器几核)。Sockets (主板上CPU插槽个数)Memory (GB) 内存大小。
下面部分,快照信息。
|
snap id 快照id |
snap time 快照时间 |
session 会话 |
Cursors/Session 游标/ 会话 |
|
| begin Snap(起始快照) | ||||
| end snap (终止快照) | ||||
| elapsed: (跨度) | ||||
| DB TIme(请求时间) |
其中,快照起始/终止时间和起始/终止Id是创建awr报告的时候自己选的。会话数量表示在这次快照采集的时间内,oracle总共有多少次会话链接。Cursors/Session 每个会话平均使用多少个游标(游标,一个内存工作区,临时存储从数据库中提取的数据块)。DB Time:是记录的服务器花在数据库运算 ( 非后台进程 ) 和等待( 非空闲等待 ) 上的时间。不包括 Oracle 后台进程消耗的时间。db time= cpu time + wait time(不包含空闲等待) (非后台进程) 这里是这样算的:首先,有四个cpu总共耗时3.4mins 。平均每隔cpu耗时不到一分钟。cpu利用率只有 1/360(快照采集总间隔时间) 百分之0.3不到,说明系统处于空闲状态。这也是为什么我们要尽可能使用需要分析的时间段的快照来进行分析的原因,因为快照跨度太长,有可能会导致dbtime的指标受到影响。
2.报告简要信息
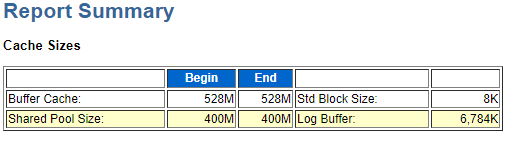
①.cache size 缓存大小
这里粗略的展示下系统的内存使用情况。其中包括:Buffer Cache 数据高速缓冲区,存放着oracle访问的数据块,存满后,自动去除最不常用的数据。通俗讲,就是将高频率使用的sql查询结果进行缓存,提高查询效率。Std Block Size 数据块大小 。 Shared Pool Size 共享池 ,用来缓存被执行的sql和被使用的数据定义。包括 Library cache和Data dictionary cache ,Library cache 用来存放sql语句的文本,分析后代码及执行计划。Data dictionary cache 缓存数据字典,存放有关表、列和其他字段及相对应的权限。Log Buffer 全名redo log buffer 缓存被执行的SQL语句和被使用的数据定义。
②.Load Profile 数据库负载属性信息

DB Times 请求时间 等待cpu的时间与数据库消耗CPU时间的总和。
DB CPU 数据库消耗cpu时间(所有用户的累加值)
Redo size 产生日志的大小,标识数据库的变更语句执行频率,数据库任务的繁忙程度。
Logical Read 逻辑读,从(或试图从)Buffer Cache中读取数据块。逻辑读包括当前数据读取和一致性读取:Logical Reads= Consistent Gets + DB Block Gets 。逻辑读受制于CPU性能,可以反映CPU使用情况。
Block changes 修改的数据块数量,标识数据的变化频率。
Physical Read 物理读数据块数量,物理读消耗io资源。
Physical writes 物理写数据块数量,包括写入数据库+写入缓存
User Calls 用户调用次数
Parses 解析次数,包括 fast parse ,软解析和硬解析。其中fast parse 是最快的,直接在PGA中命中(需要设置session_cached_cursors=n);其次是软解析,在shared pool中命中;都不命中,则触发hard parse 。parses 超过300 意味着SQL解析复用效率不高。
Hard Parses 硬解析,硬解析标识SQL不命中的次数,每秒应小于20次。超过一百次,需要检查是不是共享池(shared pool)设置的不合理。
W/A MB processed 工作区处理的任务数量 。
Logons 用户登录次数。并发session越高,数值越大。
Executes 标识 SQL执行次数,反映执行效率。
Rollback 回滚次数。
Transactions 事物数。每秒的事物数可以反映任务的繁重情况。
SQL解析过程:
软解析和硬解析,Oracle对SQL的处理过程:
1.语法检查(syntax check) 检查SQL语法是否符合规范。
2.语义检查(semantic check) 检查SQL中对应的对象(表,视图等)是否存在及该用户是否具备相应的权限。
3.解析SQL语句 (prase) 对SQL进行解析,生成解析树(parse tree)及执行计划(execution plan)。
4.执行SQL 返回结果集。
首先,fast prase :在设置session_cursor_cache 这个参数后,Cursor被直接Cache在当前Session的PGA中,在解析的时候对SQL进行语法分析、权限对象分析之后。先转到PGA中查找,如果发现完全相同的SQL,直接获取结果返回。
其次,软解析(soft parse) 在第3步执行前,先在共享池(Shared Pool )中找是否有相同的SQL,如果找到,直接使用该SQL解析好的解析树和执行计划。
最后,硬解析(Hard Parse) 没有任何缓存,直接解析SQL并运行,得到相应返回结果。
逻辑读,物理读
逻辑读:指从Buffer Cache中读取数据块
1、及时读:即时读即读取数据块当前的最新数据。任何时候在Buffer Cache中都只有一份当前数据块。即时读通常发生在对数据进行修改、删除操作时。这时,进程会给数据加上行级锁,并且标识数据为“脏”数据。
2、数据一致性读:Oracle是一个多用户系统。当一个会话开始读取数据还未结束读取之前,可能会有其他会话修改它将要读取的数据。如果会话读取到修改后的数据,就会造成数据的不一致。一致性读就是为了保证数据的一致性。在Buffer Cache中的数据块上都会有最后一次修改数据块时的SCN。如果一个事务需要修改数据块中数据,会先在回滚段中保存一份修改前数据和SCN的数据块,然后再更新Buffer Cache中的数据块的数据及其SCN,并标识其为“脏”数据。当其他进程读取数据块时,会先比较数据块上的SCN和自己的SCN。如果数据块上的SCN小于等于进程本身的SCN,则直接读取数据块上的数据;如果数据块上的SCN大于进程本身的SCN,则会从回滚段中找出修改前的数据块读取数据。通常,普通查询都是一致性读。
物理读:数据块是oracle最基本的读写单位,但用户所需要的数据,并不是整个块,而是块中的行,或列.当用户发出SQL语句时,此语句被解析执行完毕,就开始了数据的抓取阶段,在此阶段,服务器进程会先将行所在的数据块从数据文件中读入buffer cache,这个过程叫做物理读,每读取一个块,就算一次物理读。
③. Instance Efficiency Percentages (Target 100%)
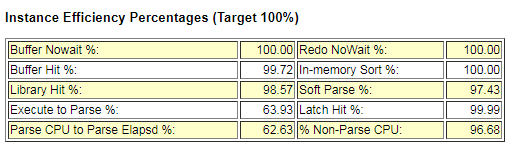
上面这些所有目标都是100%,越大越好。正常情况下,值在0-100之间。
Buffer Nowat: session 在访问一个buffer时,立即可以访问的比率。如果低于99%说明存在内存争用的情况。
Buffer Hit : 内存命中率。在一般数据库中,如果此值低于80% 应该给数据库分配更多的内存。如果命中率突然增大, 可以检查 top buffer get SQL,查看导致大量逻辑读的语句和索引,如果命中率突然减小,可以检查 top physical reads SQL,检查产生大量物理读的语句,主要是那些没有使用索 引或者索引被删除的。
Redo NoWait: 缓冲区获得Buffer未等待比例。不低于90%,不太需要考虑。
In-memory Sort 内存中完成的排序比例。应大于 95%,不太需要考虑。
Library Hit : 执行计划命中率,当应用程序调用SQL或存储过程的时候,如果在library Cache 中可以检索到执行计划,直接执行。不存在,解析SQL并缓存。如果该值低于90% 可能需要调大共享池的内存大小。应保持在95%以上。
Soft Parse: 软解析比例。重要解析指标。软解析次数和总解析次数的比值,应该大于95 % 。
Execute to Parse 执行解析比 1-(parse/execute) 这里软解析也是解析次数,软解析依然会消耗DBTime 所以可以通过使用静态SQL,动态绑定、session_cached_cursor、open cursors等技术减少软解析。
Latch Hit :数据块内部行锁不需要等待的比例。应大于99%。当前是因为系统中未共享SQL导致的低于该值。
Parse CPU To Parse Elapsd:该指标反映了 快照内解析CPU时间和总的解析时间的比值(Parse CPU Time/ Parse Elapsed Time); 若该指标水平很低,那么说明在整个解析过程中 实际在CPU上运算的时间是很短的,而主要的解析时间都耗费在各种其他非空闲的等待事件上了(如latch:shared pool,row cache lock之类等)
Non-Parse CPU 非解析cpu比例,公式为 (DB CPU – Parse CPU)/DB CPU,比值越高,说明执行查询工作的资源越多,分析查询的资源消耗越少。
④.Shared Pool Statistics

一个大概的SQL重用及共享池内存使用。
Memory Usage 共享池内存使用率,应稳定在 75%-90%之间。如果太小,说明内存空间有浪费。如果高于90% 说明内存不足,有内存争用的情况。
SQL with executions >1 复用的SQL占总的SQL语句的比率,如果值太小,需要优化SQL。
Memory for SQL w/exec>1 :执行次数大于 1 的 SQL消耗内存的占比。大概值会在 75-85% 之间。
⑤。Top 5 Time Events

系统最严重的5个等待,正常情况下,DBCPU应该排在最前面。
Waits : 该等待事件发生的次数, 对于DB CPU此项不可用
Times : 该等待事件消耗的总计时间,单位为秒, 对于DB CPU 而言是前台进程所消耗CPU时间片的总和,但不包括Wait on CPU QUEUE
Avg Wait(ms) : 该等待事件平均等待的时间, 实际就是 Times/Waits,单位ms, 对于DB CPU此项不可用
Wait Class: 等待类型:Concurrency,System I/O,User I/O,Administrative,Other,Configuration,Scheduler,Cluster,Application,Idle,Network,Commit
⑥ CPU
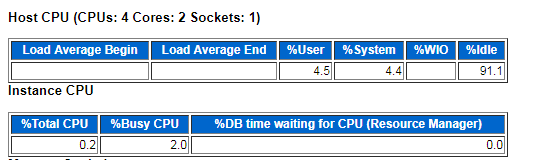
“Load Average” begin/end值代表每个CPU的大致运行队列大小。
%User+%System=> 总的CPU使用率。
%Total CPU,该实例所使用的CPU占总CPU的比例
%Busy CPU,该实例所使用的Cpu占总的被使用CPU的比例
`⑦.内存使用

host mem 主机内存.
SGA use SGA 使用内存。SystemGlobal Area是OracleInstance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区。
PGA use PGA内存。ProcessGlobal Area是为每个连接到Oracledatabase的用户进程保留的内存。
Host Mem used for SGA+PGA: 数据库使用内存占总内存比例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号