

索引选择性是什么
索引的选择性,指的是不重复的索引值(基数)和表记录数的比值。选择性是索引筛选能力的一个指标。索引的取值范围是 0—1 ,当选择性越大,索引价值也就越大。
举例说明:假如有一张表格,总共有一万行的记录,其中有一个性别列sex,这个列的包含选项就两个:男/女。那么,这个时候,这一列创建索引的话,索引的选择性为万分之二,这时候,在性别这一列创建索引是没有啥意义的。假设个极端情况,列内的数据都是女,那么索引的选择性为万分之一,其效率还不如直接进行全表扫描。如果是主键索引的话,那么选择性为1,索引价值比较大。可以直接根据索引定位到数据。
索引选择性计算
索引选择性 = 基数 / 总行数
举例:有个学校表 school ,学校名称 school_nick 的索引选择性为: SELECT COUNT(DISTINCT(school_nick))/COUNT(id) AS Selectivity FROM school;
结果如下:
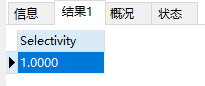
school_nick 的选择性为1,从选择性方面分析,适合建立索引。
索引选择性与前缀索引
前缀索引是用列的一部分字符去建立索引,更加节省空间(因为只使用一部分字符,索引建立时长度会降低),选择合适的话,效率也会更高。具体见 mysql 索引及索引创建原则
这里主要介绍下,前缀索引在建立的时候,怎样选择一个合适的长度作为前缀索引的字符数。选择性当然是越高越好,不过随着字符数的增加,选择性的提升会变得越来越不明显。这里,就以学校表为例子,进行前缀索引的一个创建。
首先,我们通过刚才的测试已经知道,如果使用全部列作为索引的话,选择性为1,是很好的。现在,我们取这一列的第一个字符,计算一个字符情况下的索引选择性。代码如下:
SELECT COUNT(DISTINCT(LEFT (school_nick, 1)))/COUNT(id) AS Selectivity FROM school;
结果如下:
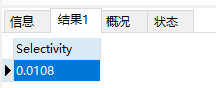
可以看出,索引的选择性很低了。然后,我们将前缀索引改为两个字符、三个字符。。。依次得到结果如下:
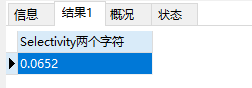
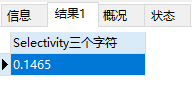
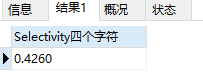
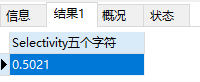
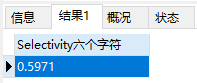
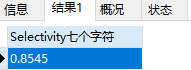
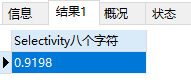

在第九个字符的时候,选择性为0.99 已经很接近1了。而且再添加字符的话,效果也不大,所以我们可以选择九个字符作为 school_nick 的前缀索引。这样索引长度仅为9 比字段长度255 短了特别多。
做一下性能对比:
school 表总共有17万行的数据。分别在没有索引,字段索引及前缀索引下按照学校名称查询一条记录用时对比:
没有索引:
全列索引: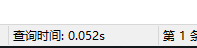
前缀索引:
到这里,我们的额前缀索引就创建成功了,而且性能还是比较可观的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号