

python中jieba库的介绍和应用
jieba库作为python中的第三方库,在平时是非常实用的,例如一些网站就是利用jieba库的中文分词搜索关键词进行工作。
一、安装环境
window + python
二、安装方式
在电脑命令符(cmd)中直接写进下面的语句:pip install jieba 即可
三、jieba库分词的基本原理
1、利用中文词库,分析汉字与汉字之间的关联几率
2、还有分析汉字词组的关联几率
3、还可以根据用户自定义的词组进行分析
四、jieba库三种模式和对应的三个函数
精确模式 : 把文本精确的切分开,不存在冗余单词 (就是切分开之后一个不剩的精确组合)
全模式 : 把文本中所有可能的词语都扫描出来,有冗余
即: 可能有一个文本,可以从不同的角度来切分,变成不同的词语。在全模式下把不同的词语都挖掘出来
搜索引擎模式:在精确模式基础上,对长词语再次切分
| 函数 | 对应模式 |
| lcut(s) | 精确模式,没有多余 |
| lcut(s,cut_all=Ture) | 全模式,有多余,长词组 |
| lcut_for_search(s) | 搜索引擎模式,有多余,长词组 |
例如:


以上就是jieba库的一些基本的知识。
五、jieba库词频统计实例
利用jieba库找出一篇文章中的关键词
1、先把文章存为记事本的txt文件
2、利用结巴库
代码如下:
1 import jieba 2 txt = open("jiebatxt.txt","r", encoding = 'GBK').read() #读取已存好的txt文档 3 words = jieba.lcut(txt) #进行分词 4 counts = {} 5 for word in words: 6 if len(word)== 1: #去掉标点字符和其它单字符 7 continue 8 else: 9 counts[word] = counts.get(word, 0) + 1 #计数 10 items = list(counts.items()) #把对象对象转化为列表形式,利于下面操作 11 12 #sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数 13 #reverse 排序规则,reverse = True 降序, reverse = False 升序(默认) 14 #key 是用来比较的参数 15 16 items.sort(key=lambda x: x[1], reverse = True) 17 for i in range(10): 18 word, count= items[i] 19 print("{0:<10}{1:>5}".format(word, count))
得出结果:
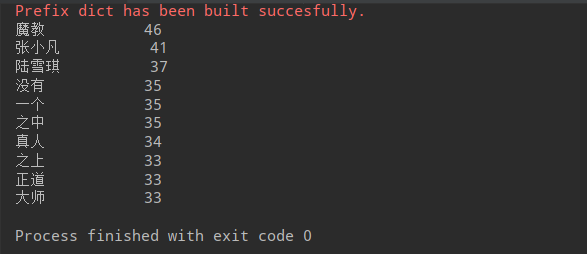
还有一种就是词云图显示,具体请进入下面链接:
https://www.cnblogs.com/liyanyinng/p/10652472.html
可以先看效果:

