


2019年3月1日14:30:47
2.特征工程
2.1 数据集
- 目标
- 知道数据集分为:训练集和测试集
- 会使用sklearn数据集
- 应用
2.1.1 可用数据集
- 公司内部 (比如百度等自己收集资料)
- 数据接口 (比如第三方的,可能需要花钱)
- 不开放的机密数据集(自己一般不可用)
学习阶段可用的数据集:
- sklearn
- kaggle(已经被google收购)
- UCI(加州大学)

Kaggle 网址:https://www.kaggle.com/datasets
UCI 数据集网址:http://archive.ics.uci.edu/ml/
scikit-learn 网址:http://scikit-learn.org/stable/datasets/index.html#datasets

https://scikit-learn.org/stable/
实现代码量比较少。
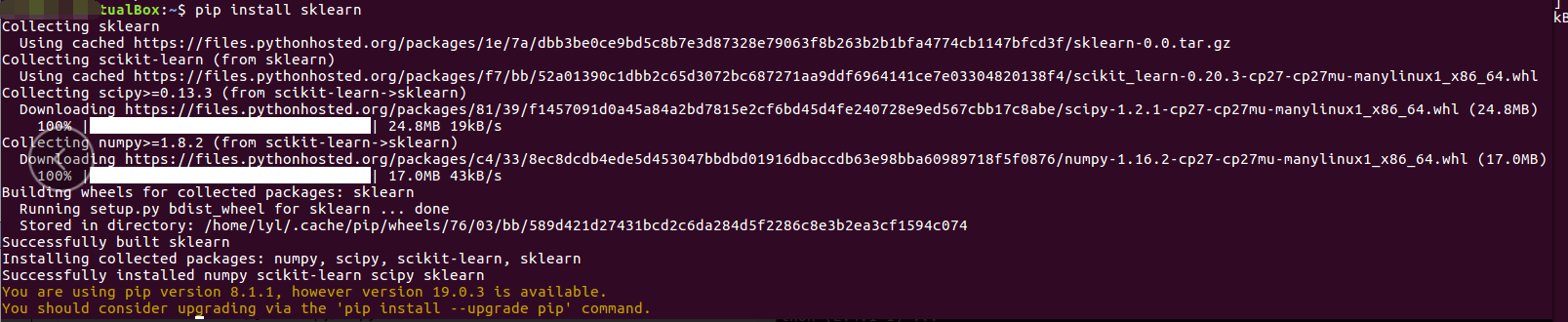
2.安装
pip3 install Scikit-learn==0.19.1
安装之后检查是否安装成功的命令:
import sklearn
注:安装scikit-learn 需要Numpy,Scipy等库

https://www.jianshu.com/p/ce85f5bd900f
那么应该怎么解决呢,其实很简单, 编辑 /usr/bin/pip 文件,修改代码
from pip._internal import main
另存为时,提示没有权限保存。
sudo chmod 600 ××× (只有所有者有读和写的权限)
sudo chmod 644 ××× (所有者有读和写的权限,组用户只有读的权限)
sudo chmod 700 ××× (只有所有者有读和写以及执行的权限)
sudo chmod 666 ××× (每个人都有读和写的权限)
sudo chmod 777 ××× (每个人都有读和写以及执行的权限)
若分配给某个文件所有权限,则利用下面的命令:
sudo chmod -R 777 文件或文件夹的名字(其中sudo是管理员权限)
---------------------
作者:langzi7758521
来源:CSDN
原文:https://blog.csdn.net/langzi7758521/article/details/51190425
版权声明:本文为博主原创文章,转载请附上博文链接!


3.Scikit-learn 包含的内容

2019年3月1日10:53:24
https://www.bilibili.com/video/av39137333?from=search&seid=10652255103060463445
1.4 机器学习开发流程
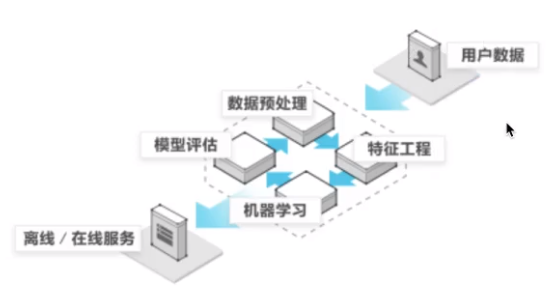
1>.获取数据
2>.数据处理(数据判断)
3>.特征工程(将数据处理成:更能直接被使用的数据 (特征值))
4>.机器学习算法进行训练---得到---模型。
5>.模型评估(如果不合适,重新进行(2)数据处理)
1.5 学习框架和资料介绍
学习机器学习时,重点:
(1)算法是核心,数据与计算是基础
(算法的改进、数据的积累、数据进行训练需要硬件设备的支持)
(2)找准定位
大部分复杂模型的算法设计都是算法工程师在做,我们需要
- 分析很多的数据
- 分析具体的业务
- 应用常见的算法
- 特征工程、调参数、优化

- 应该怎么做?
- 下面介绍的1.5.1-1.5.3 一步一步来的话比较稳、基础、周期长,不一定能坚持下去。
- 为了快速入门的话,可以学习些视频、看些实战类书籍、
- 机器学习(西瓜书)-周志华(对某一问题产生疑问)、
- 统计学习方法--李航
- 深度学习--“花书”。
- 学会分析问题,使用机器学习算法的目的,想要算法完成何种任务。
- 掌握算法基本思想,学会对问题用相应的算法解决。
- 学会利用库或者框架解决问题。
当前重要的是:掌握一些机器学习算法等技巧,从某个业务领域切入解决问题。
1.5.1 机器学习库与框架

看到这篇博客记录的挺详细 https://blog.csdn.net/u010164190/article/details/79114889
https://blog.csdn.net/u013063153/article/details/54728628
1、scikit-learn
简介: 基于 python 的第三方库,用于数据挖掘与数据分析,简单易用,以统计机器学习为主(深度学习相关框架参考之后的各个框架)。基于 NumPy, SciPy, matplotlib, 免费开源。
开源协议: BSD 2.0
深度学习框架
(1)Google:
2、Tensorflow
(2)FaceBook:
3、Pytorch
4、Caffe2
(3)
theano 可以看做是TensorFlow的前身
Chainer 可以看做是pytorch的前身
1.5.2 书籍资料

1.5.3 提深内功(但不是必须)
2019年2月27日10:01:14
https://www.bilibili.com/video/av39137333?from=search&seid=10652255103060463445
1.1 人工智能概述
达特茅斯会议(1956年8月)-人工智能的起点
在美国汉诺斯小镇 达特茅斯学院
约翰-麦卡锡(John McCarthy)
马文-闵斯基(Marvin Minsky,人工智能与认知学专家)
克劳德-香农(Claude Shannon,信息论的创始人)

用机器来模仿人类学习以及其他方面的智能。
1956年,也就成为了人工智能元年。

机器学习和人工智能、深度学习的关系:
- 机器学习是人工智能的一个实现途径
- 深度学习是机器学习的一个方法发展而来
1.2 机器学习、深度学习能做些什么
机器学习的应用场景非常多,渗透到了各个行业领域中,医疗、航空、教育、物流、电商等领域的各种场景。
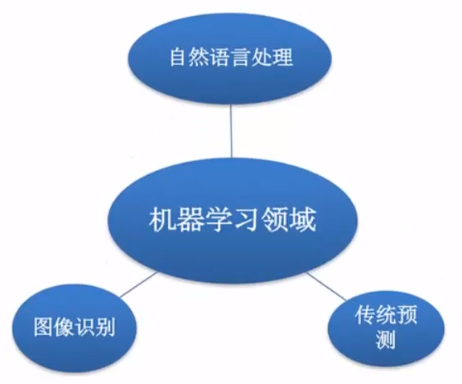
- 挖掘、预测领域:
- 应用场景:店铺销量预测、量化投资、广告推荐、企业客户分类、SQL语句安全检测分类...
- 图像识别
- 应用场景:街道交通标志检测、人脸识别...
- 自然语言处理
- 应用场景:文本分类、情感分析、自动聊天、文本检测等
- 南方都市报的“小南”,广州日报的“阿同”机器人
当前重要的是掌握一些机器学习算法等技巧,从某个业务领域切入解决问题。
1.1.3 人工智能阶段课程安排
1.2 什么是机器学习
1.2.1 定义
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
1.2.2 解释
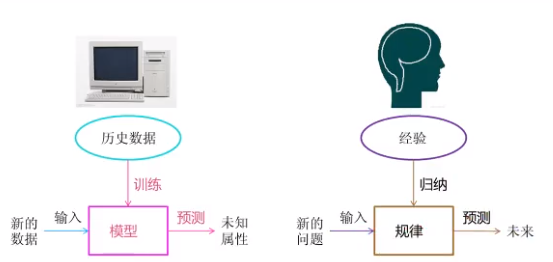
机器识别猫和狗。从数据(大量的猫和狗的图片)中自动分析获得模型(辨别猫和狗的规律),
从而使机器拥有识别猫和狗的能力。
预测房屋价格。从(房屋的各种信息)中自动分析获得模型(判断房屋价格的规律),从而使机器拥有预测房屋价格的能力。
从历史数据当中获得规律? 这些历史数据是怎样的格式?
1.2.3 数据集构成
通常把机器学习的数据叫做:数据集。
- 结构:特征值+目标值
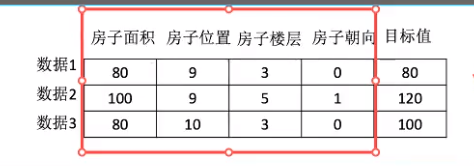
- 注:
- 每一行数据我们可以称之为样本。
- 有些数据集可以没有目标值。
1.3 机器学习算法分类
学习目标
- 机器学习算法:监督学习与无监督学习
- 监督学习的分类、回归特点。
(1)目标值:类别- 分类问题。
猫和狗的区别。就属于分类问题。
(2)目标值:连续型的数据-回归问题。
房屋价格。连续型数据。
(3)当没有目标值时,=无监督学习。
人物的各个属性信息。
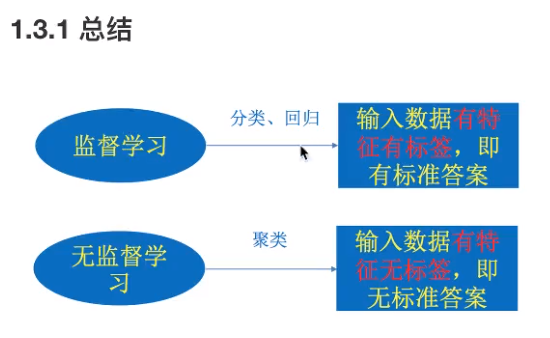

1.3.3 机器学习算法分类
- 监督学习(supervised learning)(预测)
- 分类:k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归
- 回归: 线性回归、岭回归
- 无监督学习(unsupervised learning)
- 聚类 k-means
1.4 机器学习开发流程
2019-01-22 19:47
该笔记摘自:慕课网-深度学习的某一篇课程。
深度学习是以神经网络为基础的。
讲述神经网络学习入门。
神经网络是机器学习的一种算法。
机器学习是将无序数据转换为价值的方法。从数据中抽取规律,并预测未来。
机器学习应用案例
-
分类问题:
- 图像识别、垃圾邮件识别。回归问题:房价预测、股价预测。
-
排序问题:
- 点击率预估、推荐。
-
生成问题:
- 图像生成、图像风格转换、图像文字描述生成(世界杯:通常是一些有经验的人来讲述,点评。现在根据图片就可以生成图片的描述,进而取代这类行业)。
机器学习应用流程
训练数据,定义目标函数(找到要优化的方面),选择相应的机器学习算法,训练得到模型,并应用到线上服务。最后形成循环。
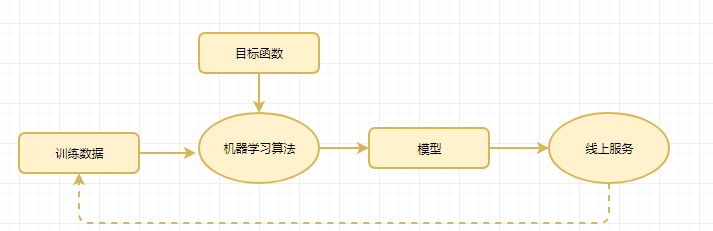
机器学习岗位职责
数据处理(采集+去噪)
模型训练(特征+模型)
模型评估与优化(MSE、F1-score、AUC+调参)
模型应用(A/B测试)
深度学习简介

深度学习与机器学习
- 机器学习是实现人工智能的方法
- 深度学习是实现机器学习算法的技术
