0.背景
经过前期的视野部分的广播优化工作,单网关单逻辑服的服务器能够承受2100~2500人的同屏移动+释放技能,但是在2100人之后,客户端的ping值就会时而达到100ms以上,主观上感到卡顿.并且到2500人时达到明显的卡顿,游戏无法继续进行.这里显示服务器资源在某个地方遭受到了瓶颈.
1. 查找瓶颈过程
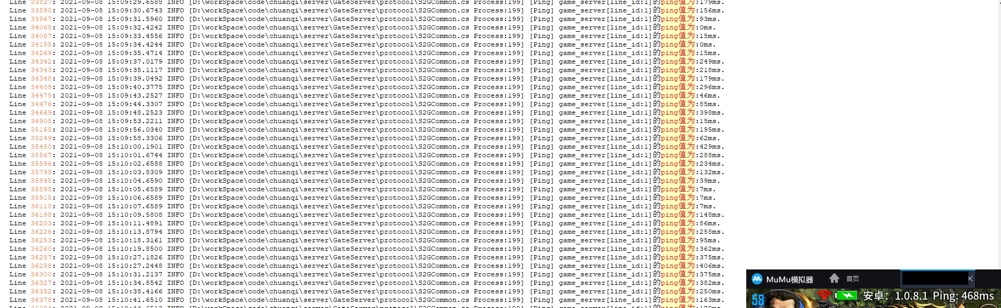
第一个线索是ping值过高.这个ping值计算过程是 "game"->"gate"->"client"->"gate"->"game",取值上再除以2.具体哪一个环节延迟高,需要更多的信息.增加协议:"gate"->"game"->"gate",统计gate到game之间的消息延迟.得到如下结果:
![]()
图1. gate<->game来回延迟数据
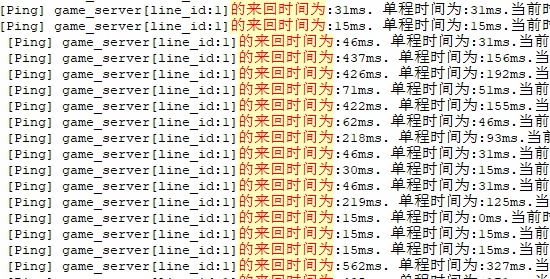
这里的测试结果表明,"gate"<->"game"之间的消息链存在延迟.但不能确认是哪个方向的延迟高.继续增加协议和日志.增加"game"->"gate"的时间戳,得到如下结果:
![]()
图2. 增加game->gate单程延迟数据
从日志中可以看到,两个方向都有延迟,我们取数据量较大的一个方向:game->gate继续分析.这个方向的消息处理流程如下图:
![]()
图3.数据链路示意图,三组测试数据
图3中下面三组数据为测试出的延迟数据分布,其"和"与上面的"单程时间"一致,测试时使用的是本地回环地址,TCP几乎没有消耗时间.可以看出,延迟数据主要集中在gate这边.gate这边的时间统计范围具体为从"字节流中读拆分协议包时发现ping协议"到解析"ping协议"之间.这中间,数据只经过了recvlist.初步怀疑是recvlist数据结构的效率问题,其数据结构是concurrentQueue,是C#里面的线程安全的队列.
这里消息接收队列是单生产者单消费者,消息发送队列是单生产者,多消费者模型,其效率可能是瓶颈.这里将发送队列修改为单生产者单消费者模型,并使用自己写的无锁队列作为数据结构.修改为单生产者单消费者模型后,tcp发送的异步回调函数来调用处理sendlist的发送函数,即发送线程作为一个循环处理sendlist数据.这里引起了一个新的问题,如果发送线程在无数据的时候不调用sleep(1ms)让出cpu时间片,这个线程会持有15%左右的CPU并且不会释放.如果有7个客户端登录,就会占满了CPU.这种方式肯定不可行.如果在sendlist没有数据的时候,调用sleep(1ms)让出cpu,那么再次唤醒就是15.625ms之后了,这样的延迟经过多个server的跳转之后会非常难以忍受.这种单生产者单消费者模型在windows系统上无法实施.需要修改回单生产者多消费者模型.
单生产者多消费者模型面临多消费者竞争的时候需要正确处理,研读concurrentQueue的进出队代码,其在面临线程竞争的处理方法为自旋(spinwait),再看spinwait的代码,超过20次调用spinwait的时候,会调用sleep(1ms).这个函数的实际唤起时间是大于15.625ms,因为windows的时间片为15.625ms.这似乎验证了concurrentQueue的效率问题的猜测.需要重写一个适用于单生产者单消费者的队列,其要求比concurrentQueue降低了一点,即单生产者.期望其效率能比concurrentQueue高一些.在建立测试代码的时候先对concurrentQueue的进出队的性能进行了测试.突然发现其在单生产者多消费者测试条件下的性能完全够用.两个消费者线程,每个消费者线程每秒取用了200多万个数据.远远大于我们目前的需求,寻找瓶颈的过程走了弯路.
加入更多的时间戳日志,经过对比发现,在原有的方式中,之所以发送之间的时间间隔大,不是sendlist的效率不高,而是主线程调用发送函数的间隔较大.继续增加时间戳日志,对比发现是每帧调用发送函数之前,会先处理recvlist,在同屏人数较大(2000人以上)的情况下,广播量指数增加效应明显,gate处理广播消息非常耗时.导致sendlist和recvlist的消息得不到及时处理,即延迟很高.
具体到广播的效率问题,使用Cpu分析软件和内存分析得知,内存池的数据结构 ConcurrentDictionary
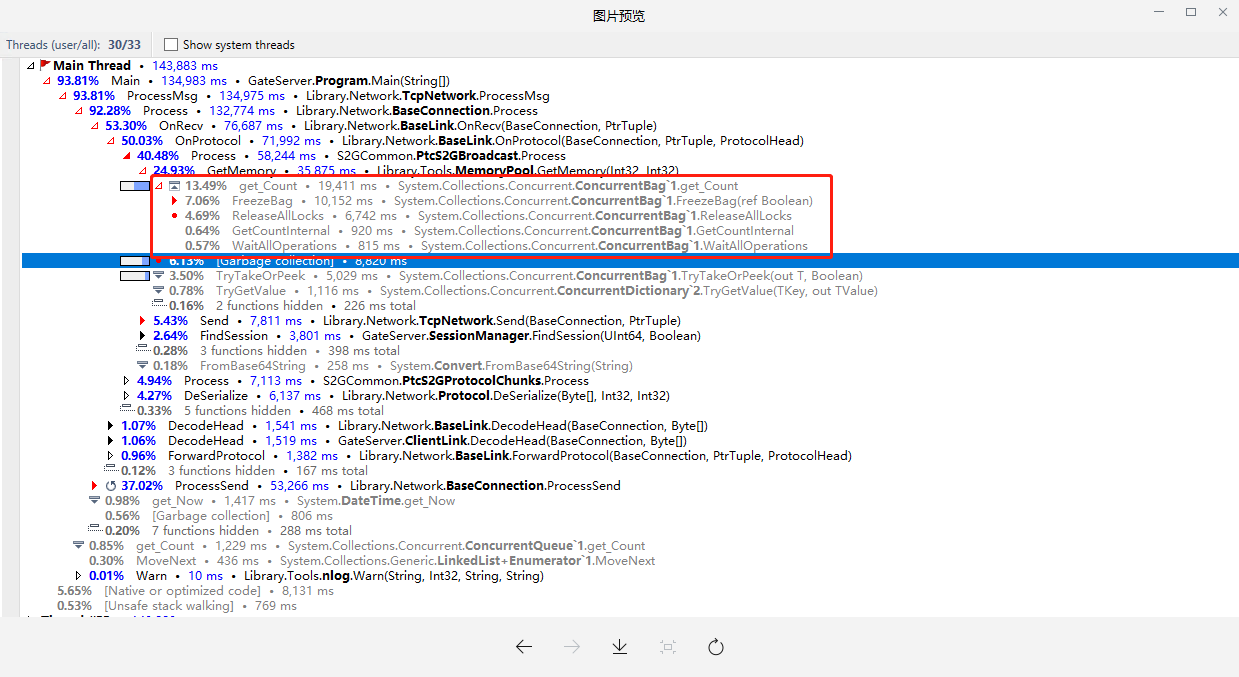
, List>> 中的ConcurrentQueue在频繁操作的时候,会产生大量内存交给GC,这里存在效率问题.尝试去掉ConcurrentQueue并将List修改为线程安全的ConcurrentBag,用dottrace运行结果如图4.
![]()
图4. 使用ConcurrentBag的内存池的测试结果
测试结果为机器人压了1600人,就出现很大的延迟.分析图4可以看到,ConcurrentBag内部的取函数操作存在着"冻结bag"、"锁操作"等,效率较低.放弃这种方式.
2. 总结
经验:寻找这种CPU分析工具无法找到的性能瓶颈,需要用日志步步为营的进行猜测、验证、猜测、验证...的进行寻找,每一步的猜想和验证都要根据现有得到的客观结果为依据,不能乱,否则就容易走弯路.
教训:在已经得到recvlist的延迟数据的情况下,应该继续对recvlist进行分析,不能因为其数据结构跟sendlist同为concurrentQueue,就跳到日志更为详细的的sendlist进行分析,结果走了一段弯路.应该坚持步步为营.面对出现目前状况的各种可能进行"广度优先"去验证,而不是"深度优先"去验证,否则方向就容易拐到错误的道路上去了.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号