JavaGuide学习-Zookeeper
背景:记录zk学习过程中的知识点,强化记忆
【面试精选】ZooKeeper 的典型应用场景发布订阅功能有啥用?
【面试精选】ZooKeeper 的典型应用场景发布订阅功能有啥用?
配置中心
我们可以考虑把应用配置放到 ZooKeeper 上去,也就是保存在 Zookeeper 的某个目录节点中,我们对指定的节点设置一个 Watcher 监听 ,这样做的好处就是:一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后可以从 Zookeeper 获取新的配置信息应用到系统中就好。
Dubbo的注册中心
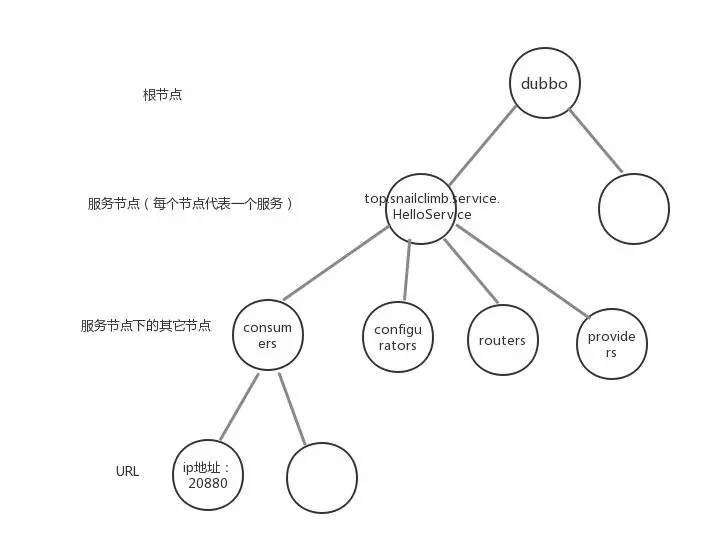
下面我们来看看 Dubbo 基于 ZooKeeper 实现的注册中心的工作流程。
如果服务是第一次启动,那么对于服务提供者会经历下面几步:
-
首先会创建dubbo 根目录;
-
再在dubbo根目录下创建服务节点
top.snailclimb.service.HelloService(代表 Dubbo 的一个服务); -
然后再在服务节点
top.snailclimb.service.HelloService下创建 consumers(代表一个服务的真正消费者)、providers(代表一个服务的真正提供者)、configurators、routers这4个节点,如上图所示; -
最后会在
/dubbo/top.snailclimb.service.HelloService/providers节点下创建一个子节点,并写人自己的URL地址。
如果服务不是第一次启动了,并且没有增加、修改或者减少服务的话,就会直接从上面提到的第 4 步开始。
服务消费者在启动的时候,读取并订阅 ZooKeeper 上 /dubbo/top.snailclimb.service.HelloService /providers 节点下的所有子节点,并解析出其中的 URL 地址作为该服务地址列表,然后程序就可以调用了。同时,服务消费者还会在 /dubbo/top.snailclimb.service.HelloService /consumers节点下
创建一个临时节点,并写人自己的 URL 地址,这就代表了top.snailclimb.service.HelloService 这个服务的一个消费者。
10分钟看懂!基于Zookeeper的分布式锁
ps:文章对zk的知识点进行了详细说明,通俗易懂,值得通读。
在描述算法流程之前,先看下zookeeper中几个关于节点的有趣的性质:
-
有序节点:假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点;zookeeper提供了一个可选的有序特性,例如我们可以创建子节点“/lock/node-”并且指明有序,那么zookeeper在生成子节点时会根据当前的子节点数量自动添加整数序号,也就是说如果是第一个创建的子节点,那么生成的子节点为/lock/node-0000000000,下一个节点则为/lock/node-0000000001,依次类推。
-
临时节点:客户端可以建立一个临时节点,在会话结束或者会话超时后,zookeeper会自动删除该节点。
-
事件监听:在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper有如下四种事件:1)节点创建;2)节点删除;3)节点数据修改;4)子节点变更。
zookeeper学习中
所以调整后的分布式锁算法流程如下:(解决了羊群效应)
-
客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点为/lock/lock-0000000000,第二个为/lock/lock-0000000001,以此类推;
-
客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听刚好在自己之前一位的子节点删除消息,获得子节点变更通知后重复此步骤直至获得锁;
-
执行业务代码;
-
完成业务流程后,删除对应的子节点释放锁。
所有对 ZooKeeper 的读操作,都可附带一个 Watch 。一旦相应的数据有变化,该 Watch 即被触发。
Watch 有如下特点:
-
主动推送:Watch被触发时,由 ZooKeeper 服务器主动将更新推送给客户端,而不需要客户端轮询。
-
一次性:数据变化时,Watch 只会被触发一次。如果客户端想得到后续更新的通知,必须要在 Watch 被触发后重新注册一个 Watch。
-
可见性:如果一个客户端在读请求中附带 Watch,Watch 被触发的同时再次读取数据,客户端在得到 Watch 消息之前肯定不可能看到更新后的数据。换句话说,更新通知先于更新结果。
-
顺序性:如果多个更新触发了多个 Watch ,那 Watch 被触发的顺序与更新顺序一致。
实例详解ZooKeeper ZAB协议、分布式锁与领导选举
ps:详细描述了zk中相关的概念 ZAB协议处理过程,公平锁和非公平锁的两种实现,值得好好读一遍
剖析面试最常见问题之zookeeper
ps:准备这篇就差不多了
ZooKeeper 数据模型介绍
Znode:data和stat
提到 ZooKeeper 数据模型,还有一个不得不得提的东西就是 事务 ID 。事务的ACID(Atomic:原子性;Consistency:一致性;Isolation:隔离性;Durability:持久性)四大特性我在这里就不多说了,相信大家也已经挺腻了。
在Zookeeper中,事务是指能够改变 ZooKeeper 服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新和客户端会话创建与失效等操作。对于每一个事务请求,ZooKeeper 都会为其分配一个全局唯一的事务ID,用 ZXID 来表示,通常是一个64位的数字。每一个ZXID对应一次更新操作,从这些 ZXID 中可以间接地识别出Zookeeper处理这些更新操作请求的全局顺序。
三 ZooKeeper 些重要概念总结
3.1 重要概念总结
- ZooKeeper 本身就是一个分布式程序(只要半数以上节点存活,ZooKeeper 就能正常服务)。(n/2+1存活)
- 为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。
- ZooKeeper 将数据保存在内存中,这也就保证了 高吞吐量和低延迟(但是内存限制了能够存储的容量不太大,此限制也是保持znode中存储的数据量较小的进一步原因)。
- ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
- ZooKeeper有临时节点的概念。 当创建临时节点的客户端会话一直保持活动,瞬时节点就一直存在。而当会话终结时,瞬时节点被删除。持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。
- ZooKeeper 底层其实只提供了两个功能:①管理(存储、读取)用户程序提交的数据;②为用户程序提供数据节点监听服务。
四 ZooKeeper 特点
- 顺序一致性: 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
- 原子性: 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
- 单一系统映像 : 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
- 可靠性: 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
五 ZooKeeper 设计目标
5.1 简单的数据模型
5.2 可构建集群
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么zookeeper本身仍然是可用的。
5.3 顺序访问
对于来自客户端的每个更新请求,ZooKeeper 都会分配一个全局唯一的递增编号,这个编号反应了所有事务操作的先后顺序,应用程序可以使用 ZooKeeper 这个特性来实现更高层次的同步原语。 这个编号也叫做时间戳——zxid(Zookeeper Transaction Id)
5.4 高性能
ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
六 ZooKeeper 集群角色介绍
最典型集群模式: Master/Slave 模式(主备模式)。在这种模式中,通常 Master服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
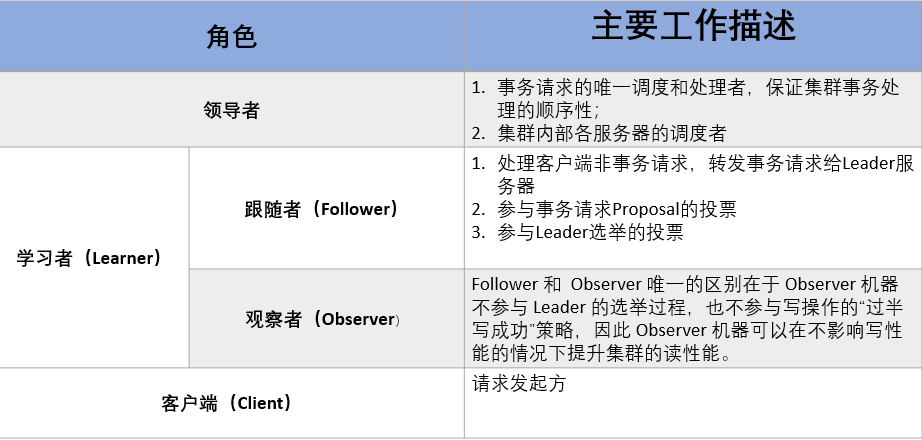
但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色。如下图所示

ZooKeeper 集群中的所有机器通过一个 Leader 选举过程来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人恢复模式并选举产生新的Leader服务器。这个过程大致是这样的:
- Leader election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
- Discovery(发现阶段):在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
- Synchronization(同步阶段):同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后
准 leader 才会成为真正的 leader。 - Broadcast(广播阶段)
到了这个阶段,Zookeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
七 ZAB 协议&Paxos算法
7.1 ZAB 协议&Paxos算法
Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在ZooKeeper的官方文档中也指出,ZAB协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为Zookeeper设计的崩溃可恢复的原子消息广播算法。
7.2 ZAB 协议介绍
ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
7.3 ZAB 协议两种基本的模式:崩溃恢复和消息广播
ZAB协议包括两种基本的模式,分别是 崩溃恢复和消息广播。当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人恢复模式并选举产生新的Leader服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该Leader服务器完成了状态同步之后,ZAB协议就会退出恢复模式。其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和Leader服务器的数据状态保持一致。
当集群中已经有过半的Follower服务器完成了和Leader服务器的状态同步,那么整个服务框架就可以进人消息广播模式了。 当一台同样遵守ZAB协议的服务器启动后加人到集群中时,如果此时集群中已经存在一个Leader服务器在负责进行消息广播,那么新加人的服务器就会自觉地进人数据恢复模式:找到Leader所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。正如上文介绍中所说的,ZooKeeper设计成只允许唯一的一个Leader服务器来进行事务请求的处理。Leader服务器在接收到客户端的事务请求后,会生成对应的事务提案并发起一轮广播协议;而如果集群中的其他机器接收到客户端的事务请求,那么这些非Leader服务器会首先将这个事务请求转发给Leader服务器。
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,让更多的人能够享受到获取知识的快乐!因为本人初入职场,鉴于自身阅历有限,所以本博客内容大部分来源于网络中已有知识的汇总,欢迎各位转载,评论,大家一起学习进步!如有侵权,请及时和我联系,切实维护您的权益!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程
2018-11-11 C++ 容器操作
2018-11-11 C/C++ 动态存储分配 malloc calloc realloc函数的用法与区别