
mysql 索引
一.创建索引
创建表时,同时创建索引
create table stu(
id int primary key auto_increment,
name varchar(32) not null,
age tinyint unsigned not null,
email varchar(32) not null,
intro text,
unique key (name),
index (email),
fulltext index (intro)
)engine myisam charset utf8;
在修改表的时候,添加索引
alter table stu1 add unique key (name), add index (email), add fulltext index (intro);
二.删除索引
主键索引的删除,在删除主键 索引时,要删除到auto_increment属性,
alter table 表名 drop primary key
普通索引的删除:alter table 表名 drop index 索引名称 (如果索引名称没有指定则是索引的字段名称)
删除唯一索引:alter table 表名 drop index 索引名称
三.查询索引
show index form 表名
show indexes from 表名
desc 表名,
show create table 表名
四.索引结构
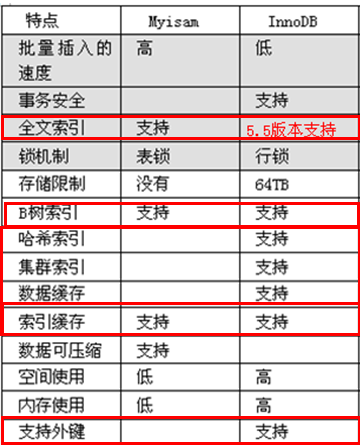
查看索引的类型,是BTREE结构。(类似于二叉树)
myisam引擎的索引的结构
该引擎的表是有三个文件组成的。一个是frm(存储结构)myd(数据) myi(索引)
myi(索引)-->frm(存储结构)-->myd(数据)
Id->btree节点->找到磁盘所在位置->找到相应数据
innodb索引的索引结构,innodb的索引叫聚簇索引。
innodb的主索引文件上 直接存放该行数据,称为聚簇索引,非主索引指向对主键的引用
Innodb的数据在btree 的节点上,id 不用通过磁盘存储位置来找数据,而是id 直接在btree结构上找到数据
注意: innodb来说,
1: 主键索引 既存储索引值,又在叶子中存储行的数据
2: 如果没有主键, 则会Unique key做主键
3: 如果没有unique,则系统生成一个内部的rowid做主键.
4: 像innodb中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为”聚簇索引”
在插入大量的数据的时候,造成频繁的页分裂(即重新组建索引,造成速度变慢).
在插入大量的数据的时候,innodb 的btree改变,而btree 上的索引值和数据也会随之移动,这样会造成移动开销,使速度变慢!
五.索引优化
1.对于创建的多列(复合)索引,只要查询条件使用了最左边的列,索引一般就会被使用。
因为组合索引是需要按顺序执行的,比如c1,c2,c3,c4组合索引,要想在c2上使用索引,必须先在c1上使用索引,要想在c3上使用索引,必须先在c2上使用索引,依此。 (左值匹配)
2.对于使用like的查询,查询如果是”%aaa”,(*歌)不会使用到索引,‘aaa%’(胡*)会使用到索引。
3.如果条件中有or,则要求or的索引字段都必须有索引,否则不能用到索引。
4.如果列类型是字符串,一定要在条件中将数据使用引号引用起来,否则不使用索引
5.索引覆盖是指:如果查询的列恰好是索引的一部分,那么查询只需要在索引文件上进行,不需要回行到磁盘再找数据,这种查询速度非常快,称为“索引覆盖”
6.利用字段数据的前部分作为索引,称为前缀索引。减少索引长度,提高索引效率。
比如:统计密码的前7个字符,作为不相同匹配条件,几乎可以做到1:1
此时,就可以利用前7个字符做索引关键字即可(离散程度高)
alter table 表名 add index (passwd(7)) 指定前7位作为索引关键字。

