设计短链接(short URL)系统
什么是短链接
就是把普通网址,转换成比较短的网址。比如:http://t.cn/RlB2PdD 这种,在微博这些限制字数的应用里。好处不言而喻。短、字符少、美观、便于发布、传播。
百度短网址 http://dwz.cn/
谷歌短网址服务 https://goo.gl/ 号称是最快的
原理解析:浏览器怎么访问短URL?
当我们在浏览器里输入 http://t.cn/RlB2PdD 时
- DNS首先解析获得 http://t.cn 的
IP地址 - 当
DNS获得IP地址以后(比如:74.125.225.72),会向这个地址发送HTTPGET请求,查询短码RlB2PdD - http://t.cn 服务器会通过短码
RlB2PdD获取对应的长 URL - 请求通过
HTTP301转到对应的长 URL https://m.helijia.com 。
这里有个小的知识点,为什么要用 301 跳转而不是 302 呐?
301 是永久重定向,302 是临时重定向。短地址一经生成就不会变化,所以用 301 是符合http语义的。同时对服务器压力也会有一定减少。
但是如果使用了301,我们就无法统计到短地址被点击的次数了。而这个点击次数是一个非常有意思的大数据分析数据源。能够分析出的东西非常非常多。所以选择302虽然会增加服务器压力,但是我想是一个更好的选择。
来自知乎 iammutex 的答案
第一步:需求与目标
功能需求
- 给定网址,系统应将其转换为短链接,这个链接应该是唯一且不冲突的。
- 用户访问短链接的时候,应将其导向原始链接。
- 用户应可以在短连接中自由选择一个作为长网址的替代。
- 短连接经过一段时间之后会失效,用户应可以指定有效时间。
非功能需求
- 服务应具有高可用性(high availability)。
- 网址跳转(URL redirecting)应该具有低延迟(low latency)
- 短网址不应该被看出与原网址的关系(not guessable/predictable)
额外需求
- 一些分析,例如:一分钟会有多少次跳转链接访问?
- 此服务应该可以被其他服务通过API访问。
第二步:容量估计与约束
此服务应该是频繁读操作。相比起加入新的URL而言,访问已有URL的短链接将会频繁很多。
我们可以假设读写操作的数量比为100:1。
流量估计
- 每月生成500M个新的短URL,每秒~200
- 读写操作数量比100:1
- 每月重定向(读)为500Mx100=50B, 每秒~20K
存储估计
- 假设每个短URL以及原始链接会被保存5年,5年内生成的短URL总量为500Mx5x12=30B
- 假设每个URL需要500B,总共需要的存储空间为500Bx30B=15TB
带宽估计
- 每秒会有~200写操作(新URL),所以总共上传数据带宽为100KB/s
- 对于读操作,~20K/s,下载带宽为~10MB/s
内存估计
我们打算对一些高访问的热门URL做cache操作,这些URL会存在于内存里面,而不是硬盘上,便于快速访问。
假设URL也遵从80-20 Rule,那么20%的URL产生了80%的流量,我们将对top20%的URL做cache。
每个月生成的新URL为500M,top20%~100M, 总共需要100Mx500B=500MB。
如果我们想cache更长时段的URL,则需要更大的空间。
第三步:系统API
我们可以以如下API生成/删除短URL:
createURL(api_dev_key, original_url, custom_alias=None, user_name=None, expire_date=None)
deleteURL(api_dev_key, url_key)Parameters:
api_dev_key (string): The API developer key of a registered account. This will be used to, among other things, throttle users based on their allocated quota.
original_url (string): Original URL to be shortened.
custom_alias (string): Optional custom key for the URL.
user_name (string): Optional user name to be used in the encoding.
expire_date (string): Optional expiration date for the shortened URL.
Returns: (string)
A successful insertion returns the shortened URL; otherwise, it returns an error code.
第四步:数据库设计
需要存储的数据的性质:
- 会有30B条记录
- 每条记录所占空间很小
- 记录与记录之间没有关系(relation)
- 服务是频繁读
数据库架构
我们需要两个表:

- URL mapping表
- 用户信息表
数据库选择
既然我们需要存储三百亿条记录,而且记录与记录之间又没有关系,NoSQL的数据库是我们的最佳选择:DynamoDB, Cassandra 或者 Riak
第五步:算法
这一部分我们解决如何把一个长链接映射成短链接的算法问题。
一般来说生成的短链接有如下格式:http://tinyurl.com/jlg8zpc
最后斜杠后面的那几位随机乱码是我们这一步要生成的对象。
Hash编码
利用Hash编码软件,例如MD5或者SHA256,对原始长链接进行编码。
一个必须考虑的问题是,生成多长的Hash码,才能满足我们系统的需求?
编码的base可以是base36 ([a-z ,0-9])或者base62 ([A-Z, a-z, 0-9]),如果再加上+和/,我们可以使用base64的编码。
- 使用base64的编码, 6字母编码有 64^6 = ~68.7 billion 不同的字符串。
- 使用base64的编码, 8字母编码有 64^8 = ~281 billion 不同的字符串。
因为我们的系统只需要存储30B条记录,6字母编码就足够了。
采取此算法应注意Hash collision问题。
离线生成键
我们也可以使用独立的键生成服务(Key Generation Service)。它提前生成随机的6位字符串,然后存储在键数据库里,需要产生短链接的时候,就从里面拿一个来用。这会使得整个事情变得非常简单便捷:我们不仅不需要为长链接编码,而且也不需要担心重复或者Hash collision这样的事情。
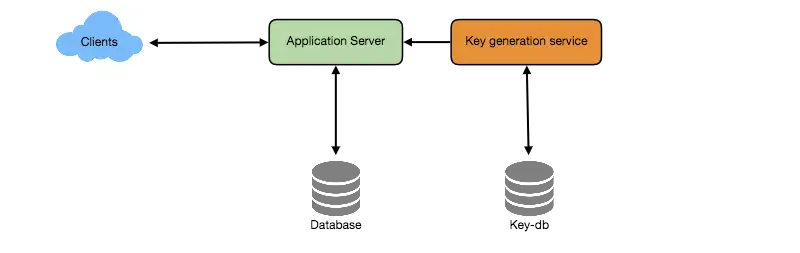
并发问题
一个键被使用之后,数据库应该把它标记为已经被使用。但是,如果有多个服务器同时试图读写数据库里的键,并发问题就产生了。
一种解决办法是用唯一的KGS,而且KGS保证不会将同一个key分配给不同的服务器请求,这需要KGS有某种lock。
额外估计
- KGS大小 :6 x 68.7B = 412 GB
- KGS Failure: 备份KGS服务器,当主服务器failure的时候,上线备份服务器。
- 每个服务器都可以cache一些key以加快访问速度
第六步:数据分区和副本
为了适用于大规模场景,我们可能需要将数据库进行分区或者增加副本。
根据首字母分区
根据Hash key的首字母对数据库进行分区。更进一步,我们可以把更少访问的首字母分到一个区,更频繁访问的字母分成单独的区,以此来平衡分区大小。
美中不足的是无法严格控制分区大小,比如以e开头的字母会很多,远超过其他字母。
根据Hash分区
根据Hash编码来分区,这样分区大小是可预计且可控的,会更加均衡一些。
第七步:缓存
应该对经常被访问到的链接进行cache,可以提高访问速度。
缓存大小 和前面估计的一样,我们会cache top20%的链接。这部分估计很小,很容易放进内存里。
什么时候清理缓存? 当cache满了之后,我们要删除一些链接并放入新的,怎么选择呢?可以使用LRU。
更新副本缓存
第八步:负载均衡器
我们可以在系统的三个地方添加负载均衡器(load balancer):
- 在用户层与代理层之间
- 在应用服务器与数据库之间
- 在应用服务器与缓存之间
一开始,我们可以使用最简单的round-robin方式,将访问请求平均分配到各个服务器上面。这个方法的优点是没有overhead,而且容易实现。如果一个服务器坏了,就把它从负载均衡器里面拿掉。
这个方法的缺点是没有考虑到每个服务器的负载问题。
第九步:清理数据库
数据库累积太多数据的时候就应该被清理一下以腾出空间。当链接失效或者过时了,我们也应该清理掉相关数据。
我们应该做lazy cleanup来缓解数据库压力, 具体表现为:
- 当用户试图访问过时链接的时候,清理掉它并给用户返回错误信息。
- 建立一个单独的清理服务。这个服务定时周期运行,而且应该非常轻量。
- 我们可以给每个链接设置失效时限,过时自动清理。
- 清理掉的链接使用的key可以放回备用key库里面。
- 我们也可以清理长期没人访问的链接。
第十步:遥测系统
利用遥测系统可以获得更多数据并作出分析,以提高系统性能,比如:
- 用户地理位置分布?用户国别?用户访问时间?浏览器?平台?
- 什么是流行的URL?如果忽然获得大量访问,数据库能不能支持?
第十一步:安全与权限
我们可以创立私密链接,或者只给一部分用户访问的链接吗?
为了达到此需求,我们需要给链接加上额外的permission级别。我们也可以创建单独的表存储允许被访问的用户信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号