

k8s 使用显卡
k8s 使用 nvidia.com/gpu: "1" 方式显卡不能共用,8张显卡只能调度8个pod 使用,docker 是可以共享使用的;
如果想共享使用显卡,需要和docker 使用方式一致,增加env NVIDIA_VISIBLE_DEVICES 即可
环境
-
硬件:Tesla T4 八张显卡
-
系统:Centos7.9 操作系统
-
服务器安装完操作系统,并安装完显卡驱动
请参照:https://www.cnblogs.com/lixinliang/p/14705315.html -
k8s 使用gpu 显卡方式
固定gpu 服务器,需要先给指定的gpu 服务器打上污点
shell>kubectl taint node lgy-dev-gpu-k8s-node7-105 server_type=gpu:NoSchedule
- 准备k8s deployment 配置文件
# cat pengyun-python-test111.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: pengyun-python-test111
name: pengyun-python-test111
namespace: pengyun
spec:
replicas: 1
selector:
matchLabels:
name: pengyun-python-test111
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
name: pengyun-python-test111
spec:
containers:
- image: harbor.k8s.moviebook.cn/pengyun/dev/000003-pengyun/python_dev:20220106140120
imagePullPolicy: IfNotPresent
name: pengyun-python-test111
resources:
limits:
cpu: "1"
nvidia.com/gpu: "1"
requests:
cpu: "1"
memory: 2Gi
nvidia.com/gpu: "1"
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
tolerations: #设置容忍污点
- effect: NoSchedule
key: server_type
operator: Equal
value: gpu
- 创建yaml
shell> kubectl apply -f pengyun-python-test111.yaml
- 查看pod 创建情况
确认pod 已调度至指定污点的node 节点
kubectl get pod -n pengyun -o wide |grep test111

- 查看pod gpu显卡
shell>kubectl exec -it -n pengyun pengyun-python-test111-d7d895867-txtxp bash
shell>nvidia-smi
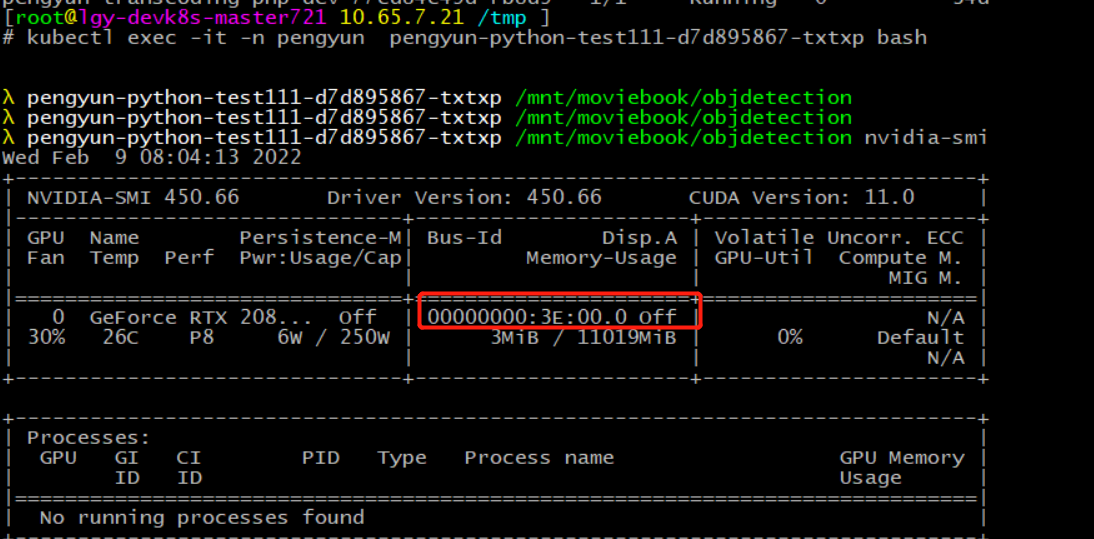
- 查看宿主机显卡
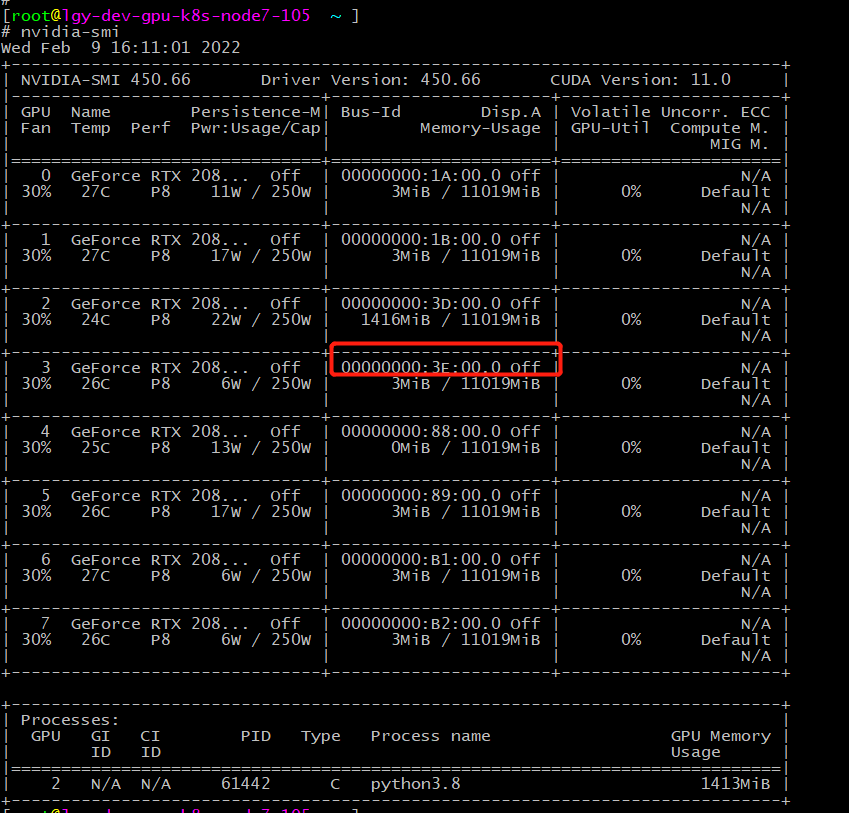
k8s 如果共享使用显卡,需要增加env设置,不需要在limits字段增加 nvidia.com/gpu: "1"
- yaml 文件配置,比如10个pod共享使用 第三张显卡,配置如下
# cat deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ainpack
namespace: kube-system
labels:
app: ainpack
spec:
replicas: 10
selector: # define how the deployment finds the pods it manages
matchLabels:
app: ainpack
template: # define the pods specifications
metadata:
labels:
app: ainpack
spec:
nodeSelector:
gpushare: "true"
containers:
- name: ainpack
image: yz.xxx.com/base/python_dev:20211012102640
imagePullPolicy: IfNotPresent
env:
- name: NVIDIA_VISIBLE_DEVICES
value: "3"
tolerations:
- effect: NoSchedule
key: server_type
operator: Equal
value: gpu-A100
- 查看创建的 gpu pod
# kubectl get pod -n kube-system -o wide |grep ainpack
ainpack-7dcf955d4d-5c7c2 1/1 Running 0 9m16s 172.30.25.18 slave-gpu-109 <none> <none>
ainpack-7dcf955d4d-9njb8 1/1 Running 0 9m14s 172.30.25.20 slave-gpu-109 <none> <none>
ainpack-7dcf955d4d-hc8j4 1/1 Running 0 9m14s 172.30.25.19 slave-gpu-109 <none> <none>
ainpack-7dcf955d4d-hrfq2 1/1 Running 0 9m16s 172.30.25.17 slave-gpu-109 <none> <none>
ainpack-7dcf955d4d-jjd22 1/1 Running 0 9m12s 172.30.25.23 slave-gpu-109 <none> <none>
ainpack-7dcf955d4d-jzzrd 1/1 Running 0 9m12s 172.30.25.22 slave-gpu-109 <none> <none>
ainpack-7dcf955d4d-rvv97 1/1 Running 0 9m16s 172.30.25.14 slave-gpu-109 <none> <none>
ainpack-7dcf955d4d-sk8xc 1/1 Running 0 9m16s 172.30.25.15 slave-gpu-109 <none> <none>
ainpack-7dcf955d4d-vxg2b 1/1 Running 0 9m13s 172.30.25.21 slave-gpu-109 <none> <none>
ainpack-7dcf955d4d-wl47s 1/1 Running 0 9m16s 172.30.25.16 slave-gpu-109 <none> <none>\
- 查看pod 使用的显卡
# kubectl exec -it -n kube-system ainpack-7dcf955d4d-sk8xc bash
#nvidia-smi
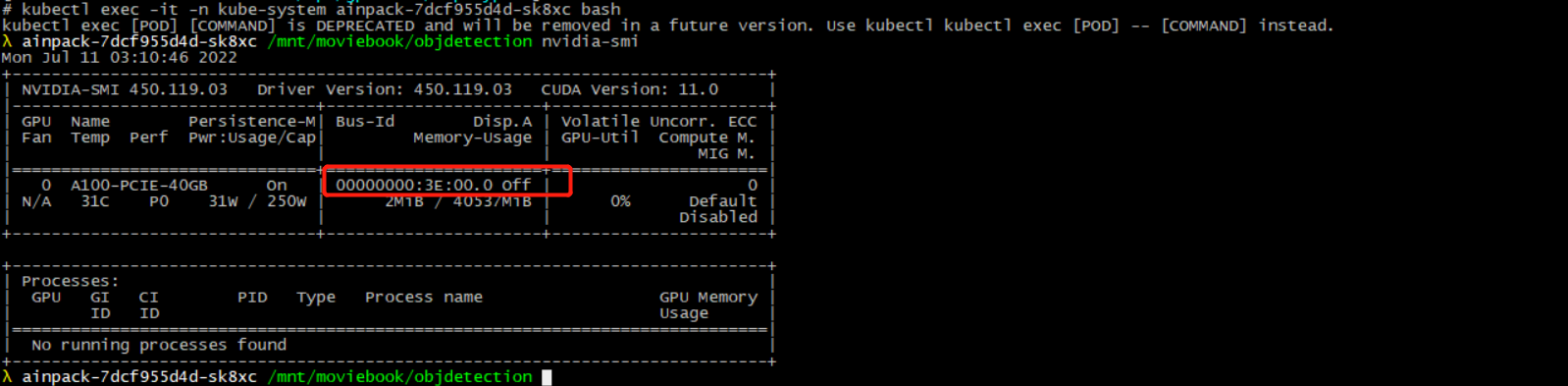
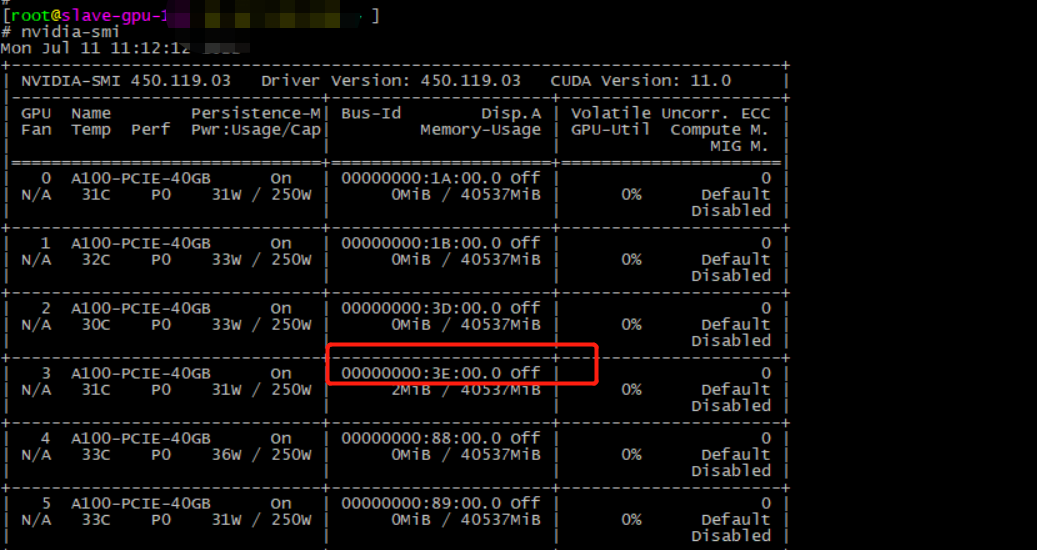
- 登录GPU 宿主机查看 第三张显卡编号,发现一致,证明可以共享
# nvidia-smi


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2018-02-09 linux 普通用户下使用 jdk 、Tomcat