

kafka基础介绍
一、kafka介绍
1.1主要功能
根据官网的介绍,kafka是一个分布式流媒体的平台,它主要有三大功能:
1.11:It lets you publish and subscribe to streams of records 发布和订阅消息流,类似消息队列的的功能,这也是将其归类为消息队列的原因
1.12:It lets you store streams of records in a fault-tolerant way 以容错的方式记录消息流,kafka以文件的方式来存储消息流
1.13:It lets you process streams of records as they occur. 可以在消息发布的时候进行处理
1.2使用场景
1.21:Building real-time streaming data pipelines that reliably get data between systems or applications.在系统和应用程序之间构建可靠的用于实时传输的管道,消息队列
的功能
1.22:Building real-time streaming applications that transform or react to the streams of data 构建实时的流数据处理程序来变换或者处理数据流,数据处理功能
1.23:日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
1.24:消息系统:解耦和生产者和消费者、缓存消息等。
1.25:用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,
然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
1.26:运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
1.27:流式处理:比如spark streaming和storm
1.3基本机制
kafka目前主要作为一个分布式的发布订阅的消息系统来使用,下面介绍一下kafka的基本机制
1.31消息传输流程
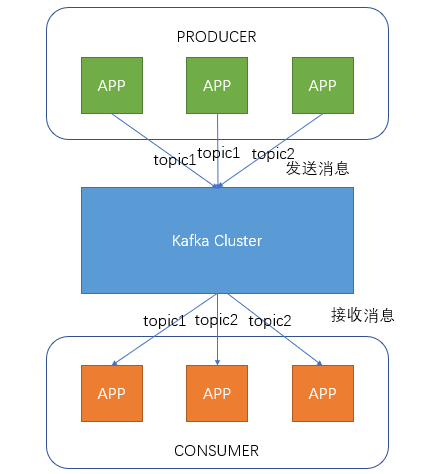
producer即生产者,向kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic,上图展示了两个生产者发送了分类为topic1的消息,另外一个发送了分类
为topic2的消息
topic即主题,通过对消息指定主题可以为消息分类,消费者可以只关注自己需要的topic中的消息
consumer即消费者,消费者通过与kafka集群建立长连接的方式,不断的从kafka集群中拉取消息,然后对这些消息进行处理
从上图可以看出同一个topic下的生产者和消费者数量并不是对应的
1.32kafka服务器消息存储策略
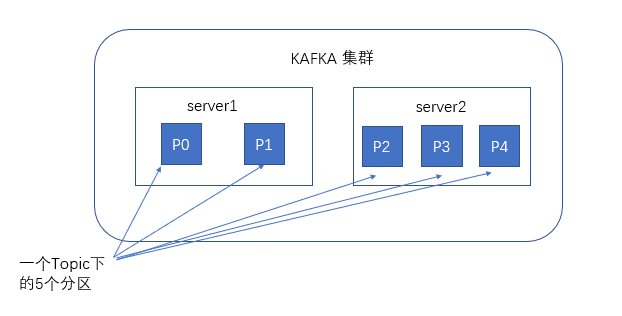
谈到kafka的存储,不得不提到分区,即partitions,创建一个topic的时候,同时可以指定分区的数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会
导致更高的不可用性,kafka在接到生产者发送的消息后,会根据均衡策略将消息存储到不同的分区中
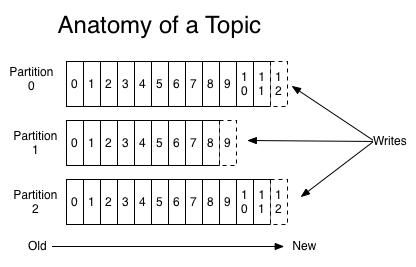
在每个分区中,消息以顺序存储,最晚接收的也最后被消费
1.33与生产者的交互
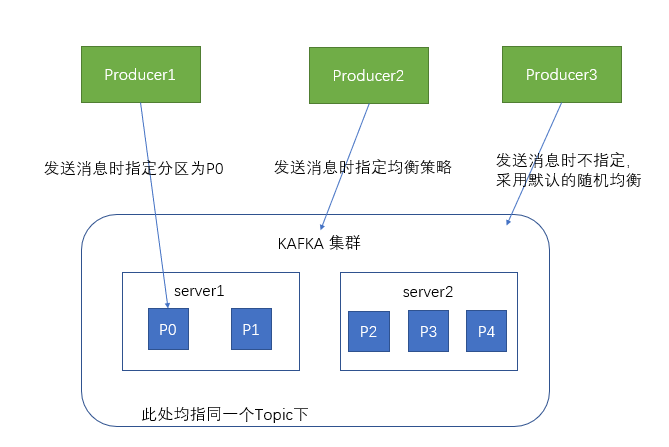
生产者向kafka集群发送消息时可以指定分区,也可以通过均衡策略来将消息发送到不同的分区中,如果不指定,就会采用默认的随机均衡策略,将数据随机的存储到不
同的分区中
1.34与消费者的交互
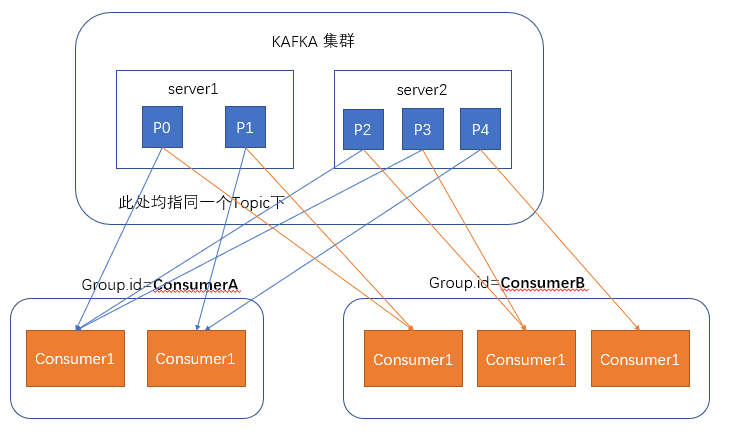
在消费者消费消息时,kafka使用offset来记录当前消费的位置。
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的消费的记录位置offset各不相同,不互相
干扰。
对于一个group而言,消费者的数量不应该多于分区的数量,因为在一个group中,每个分区至多绑定在一个消费者身上,即一个消费者可以消费多个分区,但一个分区只
能给一个消费者消费。若一个group中的消费者数量大于分区数量,多余的消费者将不会收到任何消息

