Arch-Pipelining
流水线笔记
这个问题可能需要吸三袋烟的时间才能想明白——《福尔摩斯探案集》
1. 引言
1.1 什么是流水线
它是一种将多条指令重叠执行的实现技术。一般来说,我们按照严格的先后顺序来执行各个指令,那么执行的时间就大约是执行每一条指令的时间之和。而流水线的思想和工业中汽车装配线较为类似,只是装配的是不一样的汽车(不一样的指令)。
我们定义处理器周期为流水线下移一步需要的时间。由于各级同时进行,处理器周期的长度由最缓慢的流水线级来决定。
由此看来,流水线设计者的目标应该是平衡各个流水线的长度。
1.2 RISC指令集的基础知识
首先是RISC指令集的特点:
- 所有数据操作都是基于寄存器的
- 指令一般是定长(可以不是定长,比方说到一个地址较小的地方的指令只有两位)
- 只有两种操作会访问内存
我们一般将其中的指令分为三类:
- ALU指令:算术和逻辑运算,操作寄存器或立即数,可能还会有是否有符号位的区别。
- :它们以一个寄存器源(基址寄存器)和一个立即数(偏移量)来作为操作数,两者的和是有效地址。对于,还有一个寄存器来存放数据。
- 分支和跳转:通常有无条件跳转和有条件跳转(通过比较寄存器之间的关系或寄存器和的关系)。地址的跳转实现一般是通过将符号拓展偏移量加到当前程序计数器中获得的。
1.3 实现RISC指令集的步骤
要想理解如何用流水线来实现指令集,我们就需要理解它是如何实现没有流水线的形式的。在这里,我们把每条指令分成五个部分,这种方法未必是性能最高的,但是能方便我们引向流水线。五个时钟周期分别干的事情如下:
-
指令提取():将程序计数器发送到存储器,从那里提取当前指令,并让计数器(可能会因为指令的存在,可能出现)。
-
指令译码():对指令进行译码,并取出对应的寄存器。注意到,在指令集中,寄存器/立即数的位置都是固定的,所以译码和取寄存器值的过程可以并行。必要的时候,我们可能需要判断是否为分支/是否要进行符号为拓展......以完成分支目标地址的计算。
-
执行/有效周期地址():这里会对上一周期准备的操作数进行操作,根据指令类型执行下面三条指令之一:
- 存储器引用(算出地址)
- 寄存器-寄存器(例如)
- 寄存器-立即数(例如,而这里的立即数可能需要符号拓展)
这里的三条操作可以放进同一时钟机器是用到了"只有两种操作会访问内存"的性质,这保证我们不会从内存中拿出个东西然后对其进行运算。
-
存储器访问():从内存中读取数据/将寄存器中读取的数据写入存储器。
-
写回():将结果写入寄存器堆。
在这种实现中,分支指令需要两个周期,存储指令需要四个周期,所有其他指令需要五个周期。假设分支频率为,存储频率为,那么(每条指令的时钟周期数)。
1.4 经典的五级流水线

这个流水线的设计看起来很简单,但是我们还有很多问题没有想清楚。第一个问题是,我们如何确保在同一时钟周期内,不会堆相同数据路径执行两个不同的操作。幸运的是,指令集比较简单,我们可以保证这件事情。这里给出三条主要的理由:
- 我们使用了分离的指令存储器和数据存储器,否则你可能在同一个时间去内存里读指令,并读写数据。另一方面,注意到五级中的每一级都需要处理数据,所以存储器系统需要提供倍的带宽(假设流水线处理器的时钟周期等于非流水线版本的时钟周期)。
- 尽管在阶段都会用到寄存器,但是用法是不同的。注意到,每个时钟周期需要执行两次读取和一次写入(取两个运算数),我们希望在时钟周期的前半部分写寄存器,在后半部分读寄存器。
- 我们需要引入程序计数器,且它必须在阶段就递增;此外,必须拥有一个加法器,在阶段就计算潜在的分支目标。另外一个问题是分支在阶段会改变程序计数器,这个问题我们接下来处理。
另外一个问题是,我们如何确保不同流水级中的指令不会相互干扰。这种分离是通过在连续流水级之间引入流水线寄存器来完成的。具体而言,在时钟周期的末尾,我们将一个给定流水级得出的所有结果都存储到寄存器中,在下一个周期用作下一级的输入。(再想想)
1.5 流水线的性能问题
如果流水线中的每条指令独立于所有其他指令,那这种简单的流水线对于整数指令可以正常运行。实际上,流水线中的指令可能是相互依赖的。这便是下一节我们要讨论的事情。
2. 流水化的主要阻碍——流水线冒险
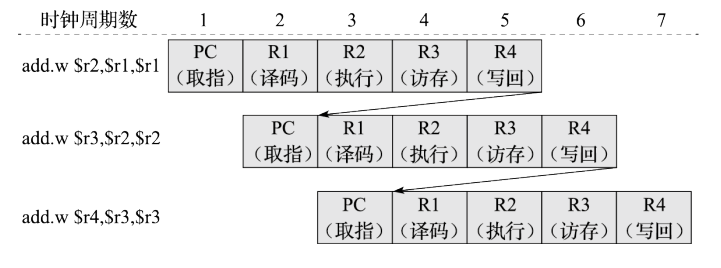
冒险是什么?就是说这条指令的存在会阻止指令流后面的指令在其指定的时钟周期内执行,这降低了流水线的加速比。共有以下三类冒险:
- 结构冒险():硬件无法同时支持指令的所有组合方式(例子:比如两条指令使用同一份硬件资源)。
- 数据冒险():如果一条指令取决于先前指令的结果(那就得等它算完),就可能导致数据冒险。
- 控制冒险():分支指令及其他改变程序计数器的指令会导致控制冒险。
一个直观的解决方法是,如果一条指令会出现冒险,就将其延迟,同时这条指令之后发射的所有指令也被停顿。而在它之前发射的指令必须执行,为了解决冒险。
2.1 带有停顿的流水线效率

2.2 数据冒险及解决方法
数据相关根据冲突访问读写的顺序可以分为三种(read after read当然不会引起冲突):read after write(后面指令要用到前面写的数据,真相关),write after write(两条指令写在同一个单元,输出相关),write after read(后面的指令覆盖前面指令读的单元,反相关)。在五级流水线中,只有会导致流水线冲突,而另外两种在乱序执行流水线中还是有可能导致冲突的。
下面讨论导致的流水线冲突以及对应的解决办法。对于如下的指令序列:
add r2, r1, r1
add r3, r2, r2
lw r4, r3, 0
add r5, r4, r4
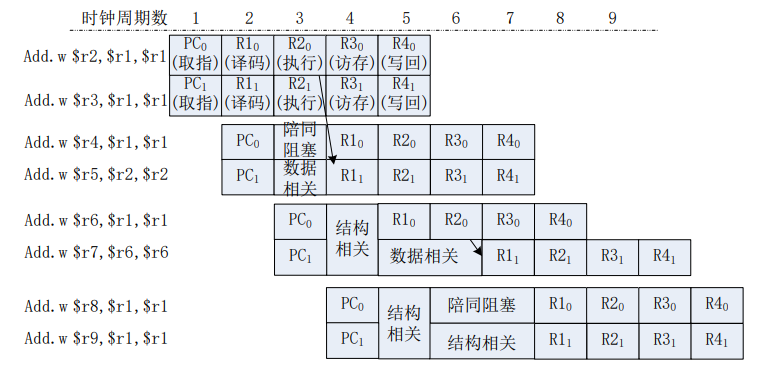
这里的三条线都代表了危险。如果第二条指令需要执行,那么必须等第一条指令写回。为了保证执行正确,一个简单的方法是让第二条指令在译码阶段阻塞,直到第一条指令写回。下面给出了这样操作的图示:
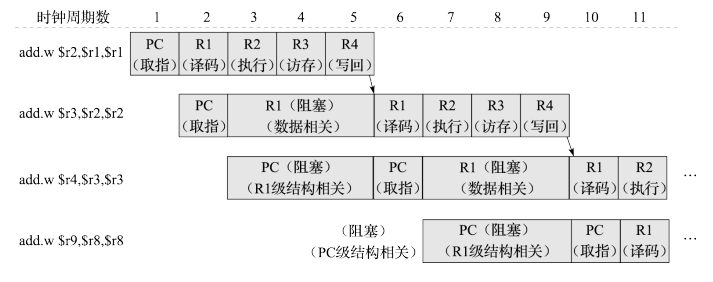
在底层电路中,实现是:被阻塞流水级的寄存器的值保持不变,同时向被阻塞流水级的下一级流水级发送无效信号,用流水线空泡(bubble)填充。
可以想象,这种操作会让流水线执行效率大大降低,我们需要更为高效的解决方式。那么下一章介绍的前递技术就是一种更好的方案。
2.3 流水线前递技术(Forwarding)
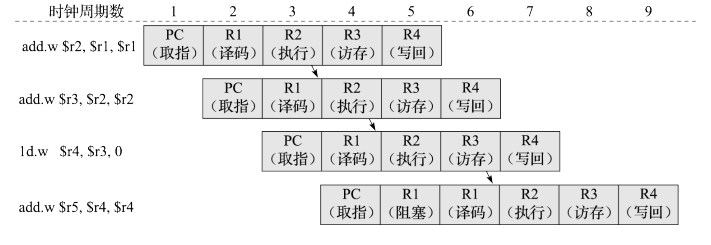
注意到,对于刚才的第二条指令,虽然其所需要的运算数还不在寄存器中,但是它可能已经在执行阶段算出来了。那么,能不能直接在这个值算好了以后拿过来用呢?由此,我们便有了前递技术。
它的具体实现方式是,在流水线中读取指令源操作数的地方通过多路选择器直接把前面指令的运算结果作为后面指令的输出。考虑到执行级能算出一些运算数,将这个结果前递到读寄存器的地方,可以减少bubble的时长。类似地,我们可以设计访存级、写回级、译码级的前递道路。新的流水线时空图如下:
2.4 控制冒险及解决办法
控制冒险本质上是因为对程序计数器的冲突访问引起的。比方说前面有一条指令是jirl r0, r1, 0。如果我们不在下一条指令取指令的时候加入两拍的阻塞,就会取到错误的指令。
但这里我们其实还能做一个优化。如果增加专用的运算资源将转移指令条件判断和计算下一条指令的位置放到译码阶段 ,那么下一条指令只需要等一拍。具体操作如下:
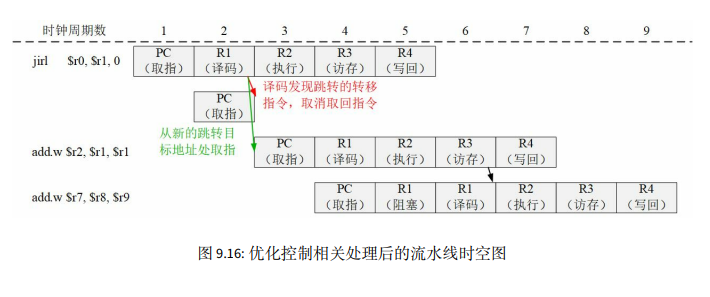
如果我们希望更进一步地减少控制冒险导致的阻塞,可以采用转移指令的延迟槽技术。我们明确,延迟槽内指令的执行不依赖于转移指令的结果,这样一拍也不用等。
2.5 结构冒险
这种问题出现的原因是因为两条指令要同时访问流水线中的同一个功能部件。比方说,流水线中只有一个译码部件,所以某一条指令就需要等一会儿。这种问题比较严重,因为它甚至会阻塞在数据层面没有任何冲突的指令。
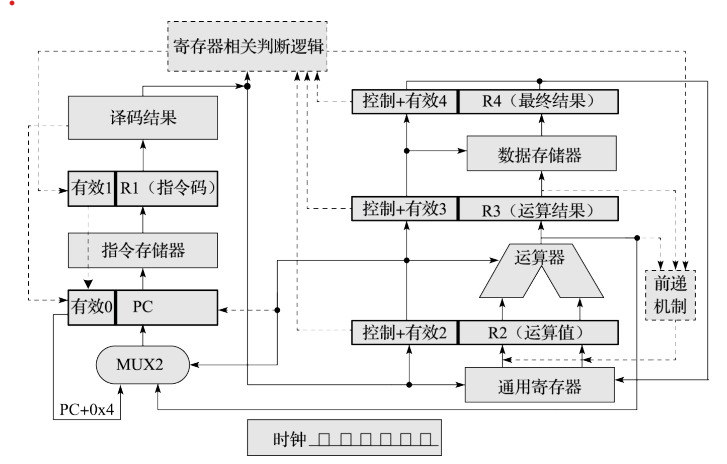
上图画出了新加入的逻辑。为了解决数据相关,加入了寄存器的判断逻辑,考虑执行、访存、写回的最多三条指令的目的寄存器信息,与译码级的源寄存器比较,并通过比较结果来决定是否阻塞译码级。为了解决控制相关,加入了译码级和执行级能够修改 PC 级有效位的通路;为了解决结构相关,加入了译码级到 PC 级的阻塞控制逻辑;为了支持前递,加入了从执行级、访存级到译码级的数据通路,并使用寄存器相关判断逻辑来控制如何前递。 可以看出,大多数机制都加在了前两级流水线上。
3. 流水线与异常处理(待学)
4. 提高流水线效率的技术
回顾之前讨论的计算公式,我们发现,要想提高流水线效率,可以改变理想,或者可以从降低流水线阻塞的角度入手。
这里主要讨论多发射数据通路。它的意思很简单,就是每一拍用从指令存储器中取多条指令,在译码等操作中也进行多条指令的操作。自然地,它需要更多的资源,例如采用支持双端口的存储器,也需要更复杂的阻塞判断逻辑。(即只有同一级流水线的两条指令都不被更早的指令阻塞时,才能让这两条指令一起继续执行)
5. 参考资料
[1] 计算机体系结构:量化研究方法
[2] 计算机体系结构基础


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异