MySQL索引
索引
索引是帮助MySQL快速获取获取排序好的数据结构。
索引的原理
如果我们在根据条件搜索数据时,一种方式是在数据文件中,把数据全部遍历一遍然后取出数据;
还有一种就是使用查询的条件建立目录,在查询数据时先去目录里面搜索一下,看有没有,有的话直接根据目录到数据中去找到对应的数据,就不用去直接遍历数据文件了,一般数据文件肯定是比目录大得多。
假设数据库存储了10GB的数据,如果不加索引,查询时就会遍历全部数据,但是我们单独把其中一个字段拿来建立一个索引目录,假设这是索引目录文件只有10MB,这时查询10MB的索引就明显比直接去遍历10GB的文件速度快的多。
MySQL中索引默认是使用B+Tree存储的,这种数据结构最擅长的就是搜索数据,几千万行的索引数据能很快就搜索到目标数据,这时索引在数据量很大的情况下,索引就相当的重要。
在MySQL中,主键PRIMARY KEY会自动创建索引,唯一约束UNIQUE字段也会自动创建索引。
索引的优缺点
索引的优点
- 索引大大减小了服务器对数据库的扫描量,从而加快数据的检索速度;
- 索引可以帮助服务器避免排序时创建临时表,减少数据的排序次数,降低CPU的消耗;
- 索引可以随机IO读取变成顺序IO读取,顺序IO读取的速度明显提升;
- 对应InnoDB引擎,索引可精确定位范围数据,在查询时可以精确添加行级锁,提高访问的并发;
索引的缺点
- 索引在进行修改添加删除数据时,数据库引擎会进行索引的维护,增加了相关操作的速度;
- 建立索引文件会额外占用物理空间,数据越多创建的索引也会随之增大;
创建索引的标准
应该创建索引的列
- 在需要
经常搜索的列上添加索引,加快搜索速度; - 在主键约束字段,强制唯一和
组织好顺序,如果不是顺序的,会导致添加数据时频繁的进行索引排序,降低数据添加的效率; - 在
经常JOIN连接的列上添加索引,加快连接的速度; - 在需要进行
范围搜索的列上添加索引,因为索引已经排好顺序了,范围搜索使用索引可以快速定位查询范围; - 在经常需要进行
排序的字段上添加索引,利用索引的排序特性,排序时不用再次去进行排序计算;
不该创建索引的列
- 不该在
很少用的字段上创建索引,创建索引会消耗资源,很少用到的字段没有创建价值; - 不该在
重复值过多的列上创建索引,重复值过多,搜索时会遍历所有的重复值,和没有索引一样; - 不该在
大字段的列(text,bit,clob)上创建索引,大字段创建索引,索引会非常大; - 不该在
频繁修改的字段列上添加索引,索引只能加快查询速度,会降低更新速度;
索引结构
索引是在MySQL的存储引擎里面实现的,不同的引擎实现索引的方式也是不一样的,不同的引擎也支持不同的索引,MySQL目前常见的索引有 BTREE 和 HASH:
| 存储引擎 | 支持索引 |
|---|---|
| InnoDB | BTREE |
| MyISAM | BTREE |
| MEMORY | HASH、BTREE |
在MySQL中,一般使用InnoDB和MyISAM引擎,所以基本上最常使用的索引就是BTREE。MySQL的BTREE是使用B+tree多路搜索树,其中集聚索引、复合索引、前缀索引、唯一索引默认都是使用B+tree。
B+Tree 结构
B+Tree底层采用的是树结构,假设我们在一个索引列中添加下列数据:
J、P、B、C、R、Q、L、O、V、H
B+tree索引将数据存储如下结构,只有叶子节点指向数据记录;这里的B+Tree,我们设置MaxDegree=3,表示到3个元素就分裂:
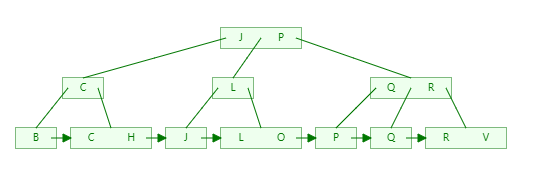
1)插入J、P,2个元素,索引不需要分裂;

2)在插入B时,先排序 B -> J -> P,发现长度等于3,J往上提一层,然后以J作为分界,左右分裂成2块;
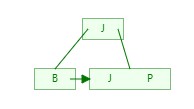
3)在插入C时,跟第一层J对比发现比J小,往左侧移继续对比下一层B,对比后C大于B就排在B的右侧,然后统计这一块的长度小于3,不做任何操作;
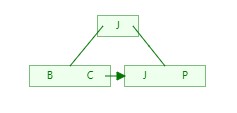
4)在插入R时,跟第一层J对比发现比J大,往右侧继续对比下一层J、P,对比后R大于P就排在P的右侧,然后统计这一块的长度发现等于3,就把中间的元素P往上提一层,然后以P为分界,左右分裂成2块;
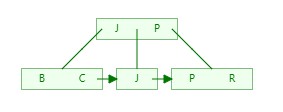
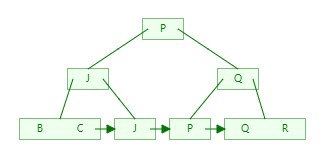
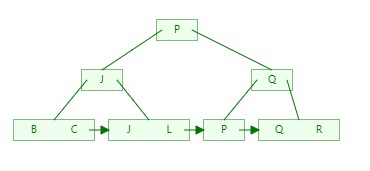
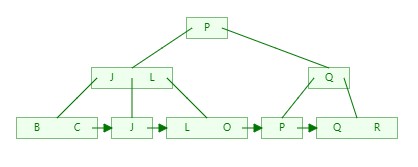
5)依次类推,插入Q、L、O、V、H依次如下:
Q:
L:
O:
V:
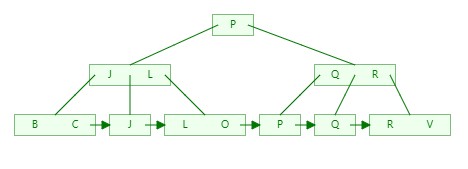
H:
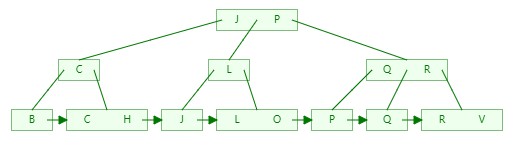
6)构建好B+Tree后,如果我们需要搜索P,此时只需要3次对比即可找到目标数据,搜索其他元素同样也是3次;
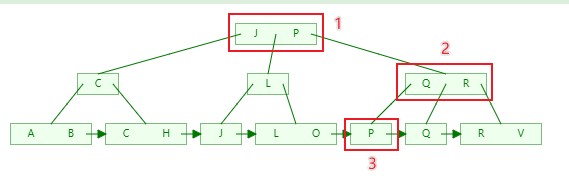
MySQL中的B+Tree
MySQL的B+Tree是经过优化的,在原B+Tree基础上添加了相邻叶子(块)的指针,这样存储数据的块就带有顺序,在查询区间顺序就可以快速定位到数据在哪几块中。
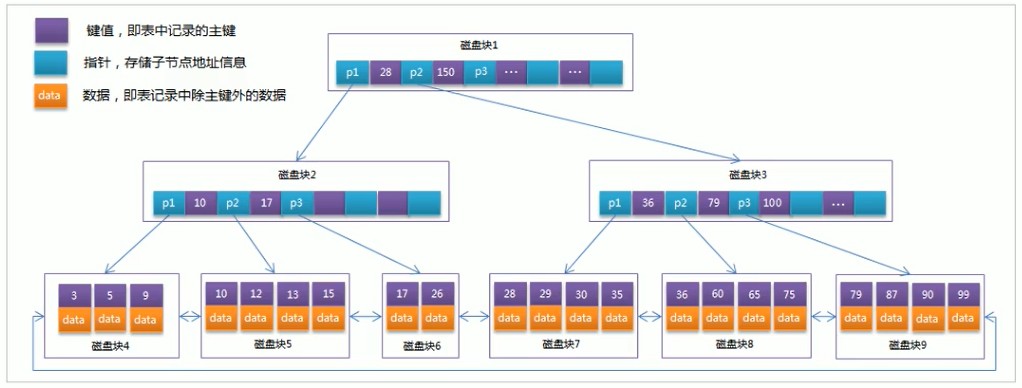
MySQL的磁盘块每块大小为16K,可在配置文件中进行修改,但是一般不要修改。
-- 查看默认块大小,默认16384Byte=16KB
SHOW VARIABLES LIKE 'innodb_page_size';
假设我们索引字段使用bigint类型的数据,那么个索引数据就占用bigint的8字节+相邻节点的指针6字节,这样计算一块16KB的块,就可以存储 16384/(8+6)≈1170 个索引;
以此计算,
假设每条记录1KB,那么最底层的叶子节点就能存储16KB/1KB=16条数据,
2层就B+Tree能存储1170*16=18720条记录,
3层的B+Tree能存储11700*11700*16=21902400条(约2千万)记录,
3层基本上就是一张表的极限了,3层的B+Tree搜索目标内容只需要3次就能找到。
MySQL的InnoDB索引
- 表数据在数据文件为
tableName.ibd的文件里; - 表数据的本身就是按照
B+Tree组织好一个索引结构文件; - 集聚索引-叶节点包含了完整的数据记录;
- 在创建InnoDB的表时,应该设置一个整形自增的主键,便于MySQL构建
.ibd文件;
索引的分类
- 唯一索引(UNIQUE KEY)
- 设置为唯一索引的字段不能重复。
- 常规索引(INDEX)
- 使用index来创建的索引,可根据索引规则来提高查询速度。
- 全文索引(FULLTEXT)
索引的创建
显示表创建的索引
-- 语法
SHOW INDEX FROM `表名`;
-- 示例:显示app_user表的索引信息
SHOW INDEX FROM `app_user`;
创建索引的语法
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX 索引名称
[USING 索引算法]
ON 表名 (key_part,...)
[index_option]
-- 索引算法
index_type: {BTREE | HASH}
-- 索引字段
key_part: col_name [(length)] [ASC | DESC]
-- 索引选项
index_option: {
KEY_BLOCK_SIZE [=] value
| index_type
| WITH PARSER parser_name
| COMMENT 'string'
}
不同类型的索引创建
创建测试表
CREATE TABLE `app_user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`email` varchar(50) NOT NULL,
`phone` varchar(11) NOT NULL,
`gender` tinyint(1) DEFAULT '0',
`password` varchar(100) NOT NULL,
`age` tinyint(4) NOT NULL DEFAULT '0',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
单值索引
- 为单个字段创建索引
-- 为email字段创建单值索引
CREATE INDEX `idx_email` ON `app_user`(`email`) USING BTREE COMMENT 'email索引';
-- 索引生效
EXPLAIN SELECT * FROM app_user WHERE email = '100@qq.com';
EXPLAIN SELECT * FROM app_user WHERE email LIKE '100@%';
EXPLAIN SELECT * FROM app_user WHERE email = '100@qq.com' OR email = '700@qq.com';
EXPLAIN SELECT * FROM app_user WHERE email IN('100@qq.com','10@qq.com');
唯一索引
- 唯一索引列的所有值必须是不同的,但可以是有多个NULL;
- 唯一索引和普通索引基本一致,只是唯一索引不能添加重复值,如果字段需要唯一就可以使用;
- 应该尽量使用唯一索引,唯一索引区分度较高,搜索效率高;
-- 为email字段创建唯一索引
CREATE UNIQUE INDEX `dex_u_email` ON `app_user`(`email`) USING BTREE COMMENT 'email索引';
-- 索引生效
EXPLAIN SELECT * FROM app_user WHERE email = '100@qq.com';
EXPLAIN SELECT * FROM app_user WHERE email LIKE '100@%';
EXPLAIN SELECT * FROM app_user WHERE email = '100@qq.com' OR email = '700@qq.com';
EXPLAIN SELECT * FROM app_user WHERE email IN('100@qq.com','10@qq.com');
复合索引
索引最左前缀在排序时会按照左边字段依次排序;- 在查询时按照索引字段依次筛选,快速查询出数据,如果不按照顺序就无法使用联合索引;
-- 创建联合索引
CREATE INDEX `idx_name_phone_age` ON `app_user`(`name`,`phone`,`age`) USING BTREE COMMENT '姓名-电话-年龄 联合索引';
-- 走索引,type=ref
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户14';
-- 走索引,type=ref
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户14' AND `age`=68;
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户14' AND `age`>18;
-- 走索引,type=range
EXPLAIN SELECT * FROM `app_user` WHERE `name` LIKE '14%';
-- 不走索引,type=all
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户14' OR `age`=68;
EXPLAIN SELECT * FROM `app_user` WHERE `name` LIKE '%用户14';
EXPLAIN SELECT * FROM `app_user` WHERE `phone`='18620769501' AND `age`=68;
EXPLAIN SELECT * FROM `app_user` WHERE `phone`='18620769501';
索引的删除
删除索引的语法
DROP INDEX 索引名称 ON 表名;
-- 示例:删除idx_email索引
DROP INDEX idx_email ON `app_user`;
丢弃主键索引
DROP INDEX PRIMARY ON 表名;
-- 示例:取消`app_user`主键
DROP INDEX PRIMARY ON `app_user`;
索引失效
- 如果在索引字段上使用模糊查询,并且使用
左模糊查询,索引将不能生效。
-- 右模糊,走索引,type=range
SELECT * FROM `app_user` WHERE `name` LIKE '14%';
-- 左模糊,不走索引,type=all
SELECT * FROM `app_user` WHERE `name` LIKE '%14';
- 在条件中使用了OR,但是OR的条件字段没有全部添加索引,会导致整体索引失效。
-- 如果给name字段添加了索引phone字段没有索引
-- name字段字段的索引也会失效
-- 可以单独查询name字段,然后再查询phone字段,最后使用union连接起来,优化查询速度
SELECT * FROM `app_user` WHERE `name`='用户14' OR `phone`='18620769501';
- 联合索引不按照索引的顺序查询,导致索引失效,详情查看联合索引案例。
- 索引列参加了运算或者使用了函数,也会导致索引失效。
-- 索引字段ID参与了计算,这会导致id字段的索引失效
EXPLAIN SELECT * FROM `app_user` WHERE `id`+1 = 2;
-- 索引字段name被函数SUBSTR处理了,这会导致name字段的索引失效
EXPLAIN SELECT * FROM `app_user` WHERE SUBSTR(`name`,1,2) = '用户';
- 尽量使用覆盖索引,避免使用select *。索引查询时,如果直接查询参加索引的字段信息,mysql会直接从索引树中读取信息,但是如果获取了没有参与索引的字段,mysql就会进行回表查询。
-- 走了索引,但数据是回表查询到的
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户14';
-- 走了索引,数据直接从索引树中获取,没有进行回表查询,查询速度比回表查询快
EXPLAIN SELECT `name`,`phone`,`age` FROM `app_user` WHERE `name`='用户14';
-
如果MySQL评估使用索引比全表扫描慢,就会放弃使用索引。
-
如果索引字段基本上都是非NULL的,这时使用
IS NULL走索引,IS NOT NULL不走索引。
-- gender 字段基本不为NULL,走索引
EXPLAIN SELECT * FROM `app_user` WHERE `gender` IS NULL;
-- gender 字段基本不为NULL,IS NOT NULL不走索引
EXPLAIN SELECT * FROM `app_user` WHERE `gender` IS NOT NULL;
- 尽量使用复合索引,少使用单列索引,复合索引会根据索引字段进行一层一层的筛选,而单列索引只会选择最优的一个索引,并不会同时使用多个索引。
索引统计
使用下列语句查看索引的使用情况:
SHOW GLOBAL STATUS LIKE 'Handler_read%';

- Handler_read_first:索引中第一条被读的次数,如果值较高,表示正在进行大量的全表扫描;
- Handler_read_key:索引第一行数据被读取的次数,值越高表示经常使用索引;
- Handler_read_last:读取索引中最后一个键的请求数,使用ORDER BY ... DESC时该值增加;
- Handler_read_next:索引按照键顺序读取下一条数据,在使用范围或者遍历索引树该值增加;
- Handler_read_prev:索引按照键顺序读取上一条数据,在使用排序时该值增加;
- Handler_read_rnd:查询直接操作数据文件请求数,在没有使用索引或者使用文件排序时增加;
- Handler_read_rnd_next:在数据文件中读取下一行,通常是因为没有使用索引,导致全表扫描;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号