MySQL基础
SQL分类
- DQL:数据查询语言
- DML:数据操作语言,增删改
- DDL:数据定义语言,表结构操作
- TCL:事务控制语言
- DCL:数据控制语言,授权、撤销
数据查询
MySQL常用命令
-- 进入mysql命令行
mysql -uroot -p123456
-- 显示全部数据库
SHOW DATABASES;
-- 切换数据库
USE miaopasi;
-- 显示数据库的全部表
SHOW TABLES;
-- 查看表结构,DESC是DESCRIBE的缩写
DESC app_user;
DESCRIBE app_user;
-- 查看版本号
SELECT VERSION();
-- sql文件数据导入(仅mysql命令行可用)
source /path/to/xxx.sql
-- 数据导出为sql文件(操作系统命令行下执行)
mysqldump -uroot -p miaopasi > miaopasi.sql
简单查询
- 查询一个字段
SELECT 字段名 FROM 表名;
-- 查询用户名字
SELECT `name` FROM `app_user`;
- 查询多个字段
查询多个字段使用逗号隔开
SELECT 字段1,[字段2,字段3] FROM 表名;
-- 查询用户名字和手机号
SELECT `name`,`phone` FROM `app_user`;
- 查询全部字段
查询全部使用星号代替字段名称。
SELECT * FROM 表名;
-- 查询用户全部信息
SELECT * FROM `app_user`;
- 查询列起别名
在字段后面使用 AS 来起别名,在输出的表头就会显示起的名字,但实际上表结构是不会被修改的。
SELECT 字段 AS 别名 FROM 表名;
-- 起别名
SELECT `name` AS 姓名 FROM `app_user`;
- 字段数据进行数学计算
在字段上使用数学运算即可。
SELECT 字段[+、-、*、/][number] FROM 表名;
mysql> SELECT `name`,`age`,`age`+18 AS 'age18岁' FROM `app_user` LIMIT 0,5;
+------------+-----+---------+
| name | age | age18岁 |
+------------+-----+---------+
| 用户10 | 85 | 103 |
| 用户100 | 96 | 114 |
| 用户1000 | 57 | 75 |
| 用户10000 | 83 | 101 |
| 用户100000 | 95 | 113 |
+------------+-----+---------+
5 rows in set (0.03 sec)
- 条件查询
使用 where 来添加查询的条件,根据条件即可筛选出符合的数据。
-- 查询name字段为'用户1000'的记录的age字段
SELECT `age` FROM `app_user` WHERE `name` = '用户1000';
-- 查询name字段非'用户1000'的记录的age字段
SELECT `age` FROM `app_user` WHERE `name` != '用户1000';
-- 查询年龄小于18
SELECT * FROM `app_user` WHERE `age` < 18;
-- 查询年龄小于等于18
SELECT * FROM `app_user` WHERE `age` <= 18;
-- 查询年龄大于80
SELECT * FROM `app_user` WHERE `age` > 80;
-- 查询年龄大于等于80
SELECT * FROM `app_user` WHERE `age` >= 80;
-- 介于2者之间[18,50]
SELECT * FROM `app_user` WHERE `age` BETWEEN 18 AND 50;
-- 多个条件组合,查询年龄大于18并且性别为0
SELECT * FROM `app_user` WHERE `age` >=18 AND `gender` = 0;
-- 查询 gender字段 值为 NULL 的记录
SELECT * FROM `app_user` WHERE `gender` IS NULL;
-- 查询 gender字段 值非 NULL 的记录
SELECT * FROM `app_user` WHERE `gender` IS NOT NULL;
-- 查询age字段为18、20的记录,即满足其中一个条件即可
SELECT * FROM `app_user` WHERE `age`=18 OR `age`=20;
-- 查询id小于100并且age=18或者20的记录,有优先级问题
SELECT * FROM `app_user` WHERE `id`<100 AND (`age`=18 OR `age`=20);
-- 查询age字段为18、20的记录,即满足其中一个条件即可
-- 这样写太麻烦,可使用 IN 关键字,后面使用小括号写出具体的值
SELECT * FROM `app_user` WHERE `age` IN(18,20);
-- 查询id小于10并且age字段非18、20的记录
SELECT * FROM `app_user` WHERE `id`<10 AND `age` NOT IN(18,20);
-- % 匹配多个字符
-- _ 匹配1个字符,需要匹配几个字符就写几个下划线
-- 注意:% _ 为占位符,如果查询条件中存在特殊的字符,使用\转义一下即可
-- 查询电话号码为189开头的
SELECT * FROM `app_user` WHERE `phone` LIKE '189%';
-- 查询尾号为9468的电话号码
SELECT * FROM `app_user` WHERE `phone` LIKE '%9468';
-- 查询号码中有8844的电话号码
SELECT * FROM `app_user` WHERE `phone` LIKE '%8844%';
-- 查询电话号码倒数第二位为9的用户
SELECT * FROM `app_user` WHERE `phone` LIKE '%9_';
-- 查询电话号码第三位为9的用户
SELECT * FROM `app_user` WHERE `phone` LIKE '__9%';
- 排序
查询后的结果可按照字段的值进行排序。
SELECT 查询字段 FROM 表名 ORDER BY 排序字段 [DESC|ASC];
-- 查询用户信息,按照age字段升序排序
SELECT * FROM `app_user` ORDER BY `age` ASC;
-- 查询用户信息,按照age字段降序排序
SELECT * FROM `app_user` ORDER BY `age` DESC;
-- 查询用户信息,按照age字段降序排序,如果一样,再按照id升序排
SELECT * FROM `app_user` ORDER BY `age` DESC, `id` ASC;
-- 查询用户信息,使用第2列进行排序
SELECT * FROM `app_user` ORDER BY 2;
数据处理函数
- 单行处理函数
处理单条记录的函数。
-- LOWER 转小写
SELECT LOWER(`email`) FROM `app_user` WHERE `id`=100;
-- UPPER 转大写
SELECT UPPER(`email`) FROM `app_user` WHERE `id`=100;
-- SUBSTR(字段,起始下标,截取长度):取子串,下标从1,不是0开始
SELECT SUBSTR(`email`,1,3) FROM `app_user` WHERE `id`<100;
-- LENGTH 字段长度
SELECT LENGTH(`email`) AS 'email_len' FROM `app_user` WHERE `id`<100;
-- CONCAT 字符串拼接
SELECT CONCAT(`name`,' email is ',`email`) AS info FROM `app_user` WHERE `id`<100;
-- TRIM 去除前后空格
SELECT TRIM(' 111@qq.com ') AS email;
-- ROUND 四舍五入
SELECT ROUND(100.09, 1) AS res;
-- RAND 生成随机数
SELECT ROUND(RAND()*100) AS random;
-- IFNULL 如果值为NULL,就设置为100
SELECT IFNULL(NULL,100) AS res;
-- CASE...THEN...ELSE...END 分支判断
SELECT `id`,CASE `gender` WHEN 0 THEN '女' ELSE '男' END AS sex FROM `app_user`;
-- STR_TO_DATE 字符串转date
SELECT STR_TO_DATE('2020-1-1 1:12:22','%Y-%m-%d %H:%i:%s');
-- DATE_FORMAT 日期格式化为字符串
SELECT DATE_FORMAT(NOW(), '%Y-%m-%dT%H:%i:%s');
- 多行处理函数(分组函数)
输入多条数据,输出一个就结果,需要注意分组函数会忽略NULL,如果使用COUNT去统计了带有NULL值的字段,输出的结果就只是 NOT NULL 记录的行数。
分组函数不能用在where条件中,因为 where 在 group by 前解析,这就导致还没分组就执行了分组函数。
-- COUNT 统计 NOT NULL 记录的行数
SELECT COUNT(`id`) FROM `app_user`;
-- MAX 统计最大值
SELECT MAX(`age`) FROM `app_user`;
-- MAX 统计最小值
SELECT MIN(`age`) FROM `app_user`;
-- SUM 求和
SELECT SUM(`age`) FROM `app_user`;
-- AVG 计算平均值
SELECT AVG(`age`) FROM `app_user`;
sql解析顺序
- from
- on
- where
- group by
- having
- select
- distinct
- order by
- limit
去除重复内容
把查询记录去除重复的记录,使用关键字distinct字段即可。
SELECT DISTINCT 字段1,字段2 FROM 表名;
-- DISTINCT age,gender联合去重
SELECT DISTINCT `age`,`gender` FROM `app_user`;
-- 统计年龄的数量
SELECT COUNT(DISTINCT `age`) FROM `app_user`;
分组查询
先根据字段进行分组,然后在使用分组函数统计相关的数据。
在一条分组查询的select后面只能跟分组的字段和分组函数,其他字段不能写。
根据SQL的解析顺序,如果想在分组后进行过滤,可以使用 having 来筛选分组的字段,不能在where中写分组函数。
能用 where 筛选的数据,就尽量不要使用 having 。
-- 按照年龄分组然后计数
SELECT age,COUNT(`age`) FROM `app_user` GROUP BY `age`;
-- 按照年龄+性别分组然后计数
SELECT `gender`,`age`,COUNT(`age`) FROM `app_user` GROUP BY `age`,`gender`;
-- 按照年龄+性别分组然后筛选出18岁以上的数据进行计数
SELECT `gender`,`age`,COUNT(`age`) FROM `app_user` GROUP BY `age`,`gender` HAVING `age`>18;
-- 筛选出18岁以上,平均人数大于10000的女性年龄,按照人数倒序排序,显示前10条记录
SELECT
`age`,
COUNT(`age`) AS count_num
FROM `app_user`
WHERE `age`>18
GROUP BY `age`,`gender`
HAVING COUNT(`age`)>10000 AND `gender`=0
ORDER BY count_num DESC
LIMIT 0,10;
连接查询
从一张表中查询数据,称之为单表查询,如果在多张表中联合起来查询数据,称之为连接查询。
在进行连接时一定要添加条件,防止笛卡尔积现象,输出很多无用的记录。
-- 不设置条件,结果=两张表的记录相乘
SELECT u.*,d.`name` AS dept_name FROM `user` AS u,`dept` AS d;
-- 设置条件,避免了上面的情况,但是匹配次数没有减少
SELECT u.*,d.`name` AS `dept_name`
FROM `user` AS u
INNER JOIN `dept` AS d
ON u.`dept_id` = d.`id`;
- 内连接 - 等值连接
完全匹配条件的内容全部查询出来,内连接使用INNER JOIN ... ON ...来进行查询,等值连接表示使用值相等来进行连接。
-- 查询用户的部门名称,
-- 用户表中只有部门ID,部门名称在部门表中
-- 我们这时就需要使用内连接查询,条件时用户的部门ID和部门表的ID相同的记录
SELECT u.*,d.`name` AS `dept_name`
FROM `user` AS u
INNER JOIN `dept` AS d
ON u.`dept_id` = d.`id`;
输出结果
+----+------+-----+--------------------+---------+-----------+
| id | name | age | email | dept_id | dept_name |
+----+------+-----+--------------------+---------+-----------+
| 1 | Jone | 18 | test1@baomidou.com | 1 | 技术部 |
+----+------+-----+--------------------+---------+-----------+
- 内连接 - 非等值连接
如果条件不是一个等量关系,我们称之为非等值连接。
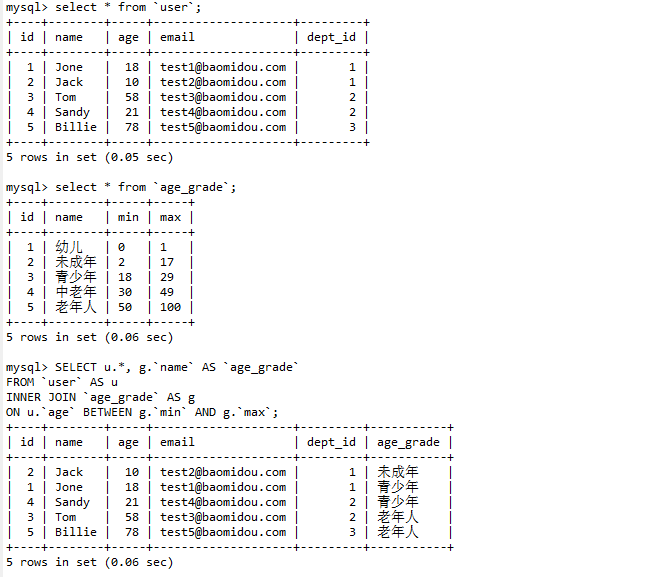
-- 查询用户的年龄等级
SELECT u.*, g.`name` AS `age_grade`
FROM `user` AS u
INNER JOIN `age_grade` AS g
ON u.`age` BETWEEN g.`min` AND g.`max`;
输出结果
- 内连接 - 自连接
自连接把一张表看做2张表,自己和自己连接查询。
例如,如果我们需要查询用户的父级pid的名称,就会出现自己连接自己查询的情况,这时我们可以把一张表看做成2张表,然后进行连接查询。
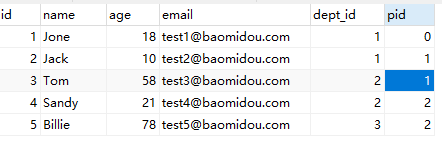
-- 查询自己父级的名称name
SELECT u1.`name`,u2.`name` AS `pname`
FROM `user` AS u1
INNER JOIN `user` AS u2
ON u1.`pid`=u2.`id`;
输出
+--------+-------+
| name | pname |
+--------+-------+
| Jack | Jone |
| Tom | Jone |
| Sandy | Jack |
| Billie | Jack |
+--------+-------+
- 外链接 - 右连接
把join右边的这张表看作是主表,主表全部显示,关联的表只显示符合条件的数据。
mysql> select * from `user`;
+----+--------+-----+--------------------+---------+-----+
| id | name | age | email | dept_id | pid |
+----+--------+-----+--------------------+---------+-----+
| 1 | Jone | 18 | test1@baomidou.com | 1 | 0 |
| 2 | Jack | 10 | test2@baomidou.com | 1 | 1 |
| 3 | Tom | 58 | test3@baomidou.com | 2 | 1 |
| 4 | Sandy | 21 | test4@baomidou.com | NULL | 2 |
| 5 | Billie | 78 | test5@baomidou.com | 3 | 2 |
+----+--------+-----+--------------------+---------+-----+
mysql> select * from dept;
+----+--------+
| id | name |
+----+--------+
| 1 | 技术部 |
| 2 | 财务部 |
| 3 | 董事部 |
| 4 | 客服部 |
+----+--------+
在上面的测试数据中,ID为4的记录,dept_id不存在,如果使用内连接查询,这样会导致该条记录查询不出来。
mysql> SELECT u.*,d.`name` AS `dept_name` FROM `user` AS u INNER JOIN `dept` AS d ON u.`dept_id` = d.`id`;
+----+--------+-----+--------------------+---------+-----+-----------+
| id | name | age | email | dept_id | pid | dept_name |
+----+--------+-----+--------------------+---------+-----+-----------+
| 1 | Jone | 18 | test1@baomidou.com | 1 | 0 | 技术部 |
| 2 | Jack | 10 | test2@baomidou.com | 1 | 1 | 技术部 |
| 3 | Tom | 58 | test3@baomidou.com | 2 | 1 | 财务部 |
| 5 | Billie | 78 | test5@baomidou.com | 3 | 2 | 董事部 |
+----+--------+-----+--------------------+---------+-----+-----------+
4 rows in set (0.05 sec)
这时我们就需要使用外连接的右连接查询,右外链接查询使用关键字 right outer join ... on进行查询。
-- 查询用户的基础信息和部门名称,没有部门的,基础信息也要显示
SELECT d.`name`,u.*
FROM `dept` AS d
RIGHT OUTER JOIN `user` AS u
ON d.`id` = u.`dept_id`;
输出
+--------+----+--------+-----+--------------------+---------+-----+
| name | id | name | age | email | dept_id | pid |
+--------+----+--------+-----+--------------------+---------+-----+
| 技术部 | 1 | Jone | 18 | test1@baomidou.com | 1 | 0 |
| 技术部 | 2 | Jack | 10 | test2@baomidou.com | 1 | 1 |
| 财务部 | 3 | Tom | 58 | test3@baomidou.com | 2 | 1 |
| 董事部 | 5 | Billie | 78 | test5@baomidou.com | 3 | 2 |
| NULL | 4 | Sandy | 21 | test4@baomidou.com | NULL | 2 |
+--------+----+--------+-----+--------------------+---------+-----+
- 外连接 - 左连接
左外连接把join左边的表看做主表,关联表只查询符合的数据。
基于上面的测试,dept表中的客服部未使用过,如果想要查询出来,我们就可使用左外连接,把左边的表看做主表,这样全部的部门就显示出来,而关联的表只会查询出符合条件的数据。
我们可以使用left outer join ... on来进行左外连接查询。
-- 查询部门信息,和部门下的用户记录
SELECT d.*,u.`name` AS `uname`
FROM `dept` AS d
LEFT OUTER JOIN `user` AS u
ON d.`id` = u.`dept_id`;
输出结果
+----+--------+--------+
| id | name | uname |
+----+--------+--------+
| 1 | 技术部 | Jone |
| 1 | 技术部 | Jack |
| 2 | 财务部 | Tom |
| 3 | 董事部 | Billie |
| 4 | 客服部 | NULL |
+----+--------+--------+
- 多表连接
如果出现2张以上的表进行连接查询,写法和2张表是一样的,只需要写多个 join on即可。
SELECT field1,field2,field3
FROM `table1` AS t1
JOIN `table2` AS t2 ON t2.`field` = t1.`field`
JOIN `table3` AS t3 ON t3.`field` = t1.`field`
JOIN `table4` AS t4 ON t4.`field` = t1.`field`
JOIN `table5` AS t5 ON t5.`field` = t1.`field`
WHERE t1.`field`='value';
子查询
在 select 查询中嵌套 select 查询,嵌套的查询被称之为子查询,子查询使用小括号包裹起来,mysql会先执行子查询。
- where子查询
如果where条件的值,需要使用sql语句进行查询才能得到,我们就可以使用子查询。
比如,我们需要查询用户的年龄大于平均年龄的用户列表:
第一步:查询出用户的平均年龄
SELECT AVG(`age`) FROM `user`;
第二步:把查询的平均年龄作为条件去筛选用户列表
SELECT * FROM `user` WHERE `age` > 37;
第三步:合并为子查询
SELECT * FROM `user` WHERE `age` > (
SELECT AVG(`age`) FROM `user`
);
输出结果
+----+--------+-----+--------------------+---------+-----+
| id | name | age | email | dept_id | pid |
+----+--------+-----+--------------------+---------+-----+
| 3 | Tom | 58 | test3@baomidou.com | 2 | 1 |
| 5 | Billie | 78 | test5@baomidou.com | 3 | 2 |
+----+--------+-----+--------------------+---------+-----+
- from子查询
在from后面使用子查询,把子查询的结果当做临时表。
如果我们需要分组查询出每个部门的平均年龄,然后查询出这些年龄的等级和部门的名称。
这时我们可以先分组查询出部门的平均年龄
SELECT `dept_id`,AVG(`age`) AS `avg_age` FROM `user` GROUP BY `dept_id`;
然后再把平均年龄临时数据作为临时表t,连接年龄等级表查询出对应的等级
SELECT t.*, d.`name`, g.`name` AS `grade`
FROM t
INNER JOIN `age_grade` AS g ON t.`avg_age` BETWEEN g.`min` AND g.`max`;
然后再使用左外连接到部门表,查询出对应的部门名称
SELECT t.*, d.`name`, g.`name` AS `grade`
FROM t
INNER JOIN `age_grade` AS g ON t.`avg_age` BETWEEN g.`min` AND g.`max`
LEFT OUTER JOIN `dept` AS d ON d.`id` = t.`dept_id`;
最后把临时表t替换为子查询
SELECT t.*, d.`name`, g.`name` AS `grade`
FROM (SELECT `dept_id`,AVG(`age`) AS `avg_age` FROM `user` GROUP BY `dept_id`) AS t
INNER JOIN `age_grade` AS g ON t.`avg_age` BETWEEN g.`min` AND g.`max`
LEFT OUTER JOIN `dept` AS d ON d.`id` = t.`dept_id`;
查询结果合并
把查询结果使用union进行合并。
在进行条件查询查询时,我们可以是 or ,或者使用 in ,也可以使用分别查询出来,然后再进行合并。
SELECT * FROM `user` WHERE age = 10 OR age = 18;
SELECT * FROM `user` WHERE age IN(10,18);
-- 使用union合并
SELECT * FROM `user` WHERE age = 10 UNION SELECT * FROM `user` WHERE age = 18;
查询结果分页
使用 limit 来提取查询结果集中指定显示的记录。
比如查询出100w记录,我们不应该把100w数据全部返回,这样花费的时间太长了,我们可以在结果集中取出几条返回出去。
语法 limit startIndex,lenght ,startIndex是从0开始的,lenght表示取出几条,limit写在sql语句的最后。
如果我们需要查询部门评价年龄top3:
-- 查询部门评价年龄top3
SELECT `dept_id`,AVG(`age`) AS `avg_age`
FROM `user`
GROUP BY `dept_id`
ORDER BY `avg_age` DESC
LIMIT 0,3;
输出结果
+---------+---------+
| dept_id | avg_age |
+---------+---------+
| 3 | 78.0000 |
| 2 | 58.0000 |
| NULL | 21.0000 |
+---------+---------+
通用分页公式:limit (pageNo-1)*pageSize,pageSize,pageNo第几页,pageSize每页显示条数。
表操作
表的创建
在指定的数据库创建一张表,建表语法格式:
CREATE TABLE `表名` (
`字段名1` 数据类型,
`字段名2` 数据类型
);
表名和字段名属于标识符,自行定义,数据类型则为mysql定义的。
数据类型
- varchar:可变长度字符串,根据实际数据动态分配空间
- char:固定长度字符,只能存储指定长度的内容,内容不足就留空,超出直接报错
- int:整型,等同于java中的int
- bigint:长整型等同于java中的long
- tinyint:小整形,有符号范围[-128,127],无符号范围[0,255]
- decimal(p,d):浮点数,p表示精度[1,68],d表示小数位数[0,30]
- date:日期类型
- datetime:日期时间类型
-- 创建电影表
CREATE TABLE `t_movie`(
`id` bigint(16) COMMENT '编号',
`name` varchar(255) COMMENT '名称',
`description` varchar(255) COMMENT '描述',
`type` char(4) COMMENT '类型',
`play_date` date COMMENT '上映时间',
`time` decimal(16,2) COMMENT '时长',
`is_delete` tinyint(1) COMMENT '是否被删除'
);
修改表结构
修改表结构使用 ALTER TABLE 语句,语法格式:
ALTER TABLE `表名` [修改选项]
根据修改选项,可对表的结构进行操作。
-- 添加字段 ADD
ALTER TABLE `t_movie` ADD `region` VARCHAR(128) COMMENT '地区';
-- 修改字段 MODIFY
ALTER TABLE `t_movie` MODIFY `region` VARCHAR(64) COMMENT '地区';
-- 删除字段 DROP
ALTER TABLE `t_movie` DROP `region`;
-- 修改字段名 CHANGE
ALTER TABLE `t_movie` CHANGE `region2` `region` VARCHAR(64);
-- 修改表名 RENAME TO
ALTER TABLE `t_movie` RENAME TO `tbl_movie`;
ALTER TABLE `tbl_movie` RENAME TO `t_movie`;
表的删除
DROP删除会直接删除表结构和数据
DROP TABLE `table_name` IF EXISTS;
如果只是想清空表的数据,或者说是重置表的话可以使用 TRUNCATE
TRUNCATE TABLE `table_name`;
表的复制
快速复制表结构和数据,使用 CREATE TABLE 和 SELECT 语句来实现,语法格式:
CREATE TABLE `复制后的名称` AS SELECT * FROM `复制的表名称`;
例如,复制t_movie表的数据,并命名为 t_movie_bak
CREATE TABLE `t_movie_bak` AS SELECT * FROM `t_movie`;
数据插入
向创建的表中插入数据,语法格式:
INSERT INTO `表名`(`字段1`,`字段2`,`字段3`,...) VALUES('值1','值2','值3',...);
字段和值要一一对应,即数量和数据类型要一一对应。
INSERT INTO `t_movie`(`id`,`name`,`description`,`type`,`play_date`,`time`,`is_delete`)
VALUES(1,'失控玩家','发现自己其实是大型电游的背景人物','科幻','2021-08-13',100.0101,0);
查看插入的数据
mysql> select * from t_movie;
+----+---------+------------------------------+------+------------+--------+-----------+
| id | name | description | type | play_date | time | is_delete |
+----+---------+------------------------------+------+------------+--------+-----------+
| 1 | 失控玩家 | 发现自己其实是大型电游的背景人物 | 科幻 | 2021-08-13 | 100.01 | 0 |
+----+---------+------------------------------+------+------------+--------+-----------+
如果没有给字段指定值,默认为 NULL。
- 插入日期
如果插入的日期格式不是标准的%Y-%m-%d ,可以使用 STR_TO_DATE 把字符串转换为日期格式即可;
比如下面的日期字符串就是 5/7/2019 这种格式的,无法直接插入,就可以使用STR_TO_DATE 来进行格式化。
INSERT INTO `t_movie`(`id`,`name`,`description`,`type`,`play_date`,`time`,`is_delete`)
VALUES (
2,
'陪你很久很久',
'九饼为了守住从小就暗恋着的青梅竹马薄荷',
'爱情片',
STR_TO_DATE('5/7/2019','%d/%m/%Y'),
104,
0
);
如果想插入当前日期,可以使用 NOW() 函数来获取当前日期时间。
- 插入多条记录
向表中一次插入多条记录,语法格式:
INSERT INTO `表名`(`字段1`,`字段2`,`字段3`,...)
VALUES
('值1-1','值1-2','值1-3',...),
('值2-1','值2-2','值2-3',...),
...;
-- t_movie 表中一次添加2条记录
INSERT INTO `t_movie`(`id`,`name`,`description`,`type`,`play_date`,`time`,`is_delete`)
VALUES
(3,'失控玩家2','发现自己其实是大型电游的背景人物','科幻','2021-08-13',100.0101,0),
(4,'失控玩家3','发现自己其实是大型电游的背景人物','科幻','2021-08-13',100.0101,0);
数据修改
修改表中的数据,语法格式:
UPDATE `表名` SET `字段名1`=值1,`字段名2`=值2 WHERE `字段`=值;
需要注意的是,如果不写条件会导致表的全部数据被修改,非常危险。
-- 修改t_movie表id为2的记录,把name改为‘陪你很久很久1’,description改为‘九饼’
UPDATE `t_movie` SET `name`='陪你很久很久1',`description`='九饼' WHERE `id`=2;
数据删除
删除表中的记录,语法格式:
DELETE FROM `表名` WHERE `字段`=值;
删除表数据和修改一样,要加条件,不然会删除全部数据。
-- 删除t_movie表id为2的记录
DELETE FROM `t_movie` WHERE `id`=2;
如果只是想清空表的数据,或者说是重置表的话可以使用 TRUNCATE
TRUNCATE TABLE `table_name`;
约束
在创建表时我们可以在表中的字段加上一些约束,包装这个字段的数据的完整性和有效性。
- 主键约束:PRIMARY KEY
字段约束为主键,主键值不能为NULL,不能重复。
只需要在主键字段类型后面加上 PRIMARY KEY ,就表示字段为主键,会自动校验主键的约束。
主键约束只能有一个,不能在多个字段上添加主键约束。
在mysql中,可以使用 AUTO_INCREMENT 来设置字段为自动增长,可以联合主键约束,实现自动维护主键,在插入数据时,我们就可以不指定主键的值,mysql会自动给数据的主键添加一个增长的值。
-- 创建表t_movie,把id字段设置为主键
-- 在插入数据时,id就必须写,并且还不能重复
CREATE TABLE `t_movie`(
`id` bigint(16) PRIMARY KEY AUTO_INCREMENT COMMENT '编号',
`name` varchar(255) NOT NULL COMMENT '名称',
`description` varchar(255) NULL COMMENT '描述',
`type` char(4) NULL COMMENT '类型',
`play_date` date NULL COMMENT '上映时间',
`time` decimal(16,2) NULL COMMENT '时长',
`is_delete` tinyint(1) NULL COMMENT '是否被删除'
) COMMENT '电影表';
- 非空约束:NOT NULL
约束字段不能为NULL,如果为NULL会报错,我们只需要在约束的字段类型后面加上 NOT NULL 即可,如果可以为NULL,可以写 NULL ,也可以不写。
-- 常见表t_movie,id和name字段不能为NULL,其他字段可以为NULL
-- 在插入数据时,id和name字段就必须写,不然就会报错
CREATE TABLE `t_movie`(
`id` bigint(16) PRIMARY KEY AUTO_INC REMENT COMMENT '编号',
`name` varchar(255) NOT NULL COMMENT '名称',
`description` varchar(255) NULL COMMENT '描述',
`type` char(4) NULL COMMENT '类型',
`play_date` date NULL COMMENT '上映时间',
`time` decimal(16,2) NULL COMMENT '时长',
`is_delete` tinyint(1) NULL COMMENT '是否被删除'
) COMMENT '电影表';
- 唯一约束:UNIQUE
约束字段不能重复,可以为NULL,我们可以直接在字段类型后面追加UNIQUE,即可限制字段内容不能重复。
-- 再限制name字段内容不能重复
CREATE TABLE `t_movie`(
`id` bigint(16) PRIMARY KEY AUTO_INCREMENT COMMENT '编号',
`name` varchar(255) NOT NULL UNIQUE COMMENT '名称',
`description` varchar(255) NULL COMMENT '描述',
`type` char(4) NULL COMMENT '类型',
`play_date` date NULL COMMENT '上映时间',
`time` decimal(16,2) NULL COMMENT '时长',
`is_delete` tinyint(1) NULL COMMENT '是否被删除'
) COMMENT '电影表';
- 默认约束:DEFAULT
当插入一个新行到表中时,没有给该列明确赋值,如果定义了列的默认值,将自动得到默认值,如果没有,则为(NULL)。
我们可以在字段类型后面使用 DEFAULT 默认值 来设置约束。
-- 设置is_delete字段的默认值为0
-- 这样在插入数据时,如果不传入is_delete字段的值,就会默认设置为0
CREATE TABLE `t_movie`(
`id` bigint(16) PRIMARY KEY AUTO_INCREMENT COMMENT '编号',
`name` varchar(255) NOT NULL UNIQUE COMMENT '名称',
`description` varchar(255) NULL COMMENT '描述',
`type` char(4) NULL COMMENT '类型',
`play_date` date NULL COMMENT '上映时间',
`time` decimal(16,2) NULL COMMENT '时长',
`is_delete` tinyint(1) NULL DEFAULT 0 COMMENT '是否被删除'
) COMMENT '电影表';
- 外键约束:FOREIGN KEY
指定该列记录属于主表中的一条记录,参照另一条数据。
在字段的最后使用表级别约束设置,语法格式:
FOREIGN KEY (`约束字段`) REFERENCES `参考表`(`参考字段`)
如果我们不设置外键约束,容易会产生无效的数据,设置了约束后,字段就只能添加主表存在的记录。
-- 用户主表
CREATE TABLE `login_user`(
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`loginName` VARCHAR(18) NOT NULL,
`loginPwd` VARCHAR(11),
PRIMARY KEY (`id`)
) ENGINE=INNODB CHARSET=utf8 COLLATE=utf8_general_ci;
-- 信息附表,userId使用的是login_user表的id字段
-- 所以我们可以给userId添加外键约束
CREATE TABLE `user_info`(
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`userId` INT(11) UNSIGNED NOT NULL,
`mobile` VARCHAR(11),
PRIMARY KEY (`id`),
FOREIGN KEY (`userId`) REFERENCES `login_user`(`id`)
) ENGINE=INNODB CHARSET=utf8 COLLATE=utf8_general_ci;
-- 插入主表记录
INSERT INTO `login_user`(`loginName`,`loginPwd`) VALUES('abcde','qwert');
INSERT INTO `login_user`(`loginName`,`loginPwd`) VALUES('grhd','sdfrw');
-- 插入子表外键约束数据
INSERT INTO `user_info`(`userId`,`mobile`) VALUES(1,'13800000001');
INSERT INTO `user_info`(`userId`,`mobile`) VALUES(2,'13800000002');
-- 主表记录中不存在3记录,子表使用了会报错
INSERT INTO `user_info`(`userId`,`mobile`) VALUES(3,'13800000003');
存储引擎
存储引擎是表用来存储、组织数据的方式,不同的存储引擎,表存储的方式不同。
我们在创建表时可以在字段括号后面使用 ENGINE=存储引擎名称 的方式来指定存储引擎,
使用 AUTO_INCREMENT=默认自增起始值 指定自动增长的起始值,
使用DEFAULT CHARSET=字符集来指定字符集,
使用 COLLATE=排序规则 指定表的排序规则,
使用 COMMENT=注释 来设置表的注释。
完整的创建表的语法格式为
CREATE TABLE `表名` (
字段 数据类型
)
ENGINE=存储引擎
AUTO_INCREMENT=自增起始值
DEFAULT CHARSET=默认字符集 COLLATE=排序规则
COMMENT='注释';
MySQL支持九大存储引擎,但是我们一般使用默认的INNODB引擎,常见引擎有
-
MyISAM:表的定义、数据的存储、索引文件是分别存储
-
InnoDB:数据和索引是存储在一起的,支持事务、行级锁,支持崩溃后自动恢复
-
MEMORY:数据存储在内存中的,断电后数据消失
完整实例代码
DROP TABLE IF EXISTS `t_movie`;
CREATE TABLE `t_movie`(
`id` bigint(16) PRIMARY KEY AUTO_INCREMENT COMMENT '编号',
`name` varchar(255) NOT NULL UNIQUE COMMENT '名称',
`description` varchar(255) NULL COMMENT '描述',
`type` char(4) NULL COMMENT '类型',
`play_date` date NULL COMMENT '上映时间',
`time` decimal(16,2) NULL COMMENT '时长',
`is_delete` tinyint(1) NULL DEFAULT 0 COMMENT '是否被删除'
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci COMMENT '电影表';
事务
事务概述
-
在 MySQL 中只有使用了
Innodb引擎的数据库或表才支持事务; -
一个事务就是一个完整的业务逻辑,是一个最小的工作单元,不可再分;
-
事务内的操作要么全部成功,要么全部失败,不允许只成功一部分;
-
事务只存在于数据的增删改操作,一旦涉及数据增删改操作,就要考虑数据的安全问题,事务就是用来解决这个问题的;
事务的使用
-- 开启事务
BEGIN;
-- 提交事务
COMMIT;
-- 回滚事务
ROLLBACK;
例子:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS `test` DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
USE `test`;
-- 创建账户表
CREATE TABLE IF NOT EXISTS `account` (
`id` BIGINT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) NOT NULL,
`money` BIGINT(11) NOT NULL,
PRIMARY KEY(`id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 插入基础数据
INSERT INTO `account`(`name`,`money`)
VALUES ('李华',100000),('李梅',100000);
-- 模拟转账:提交修改
BEGIN;
UPDATE `account` SET `money` = `money` - 1000 WHERE id=1;
UPDATE `account` SET `money` = `money` + 1000 WHERE id=2;
COMMIT;
-- 模拟转账:回滚修改
BEGIN;
UPDATE `account` SET `money` = `money` - 1000 WHERE id=1;
UPDATE `account` SET `money` = `money` + 1000 WHERE id=2;
ROLLBACK;
事务的特性
事务的特性ACID
- 原子性A:事务中的所有操作,一起成功、一起失败;
- 一致性C:处理后的值符合预期的;
- 隔离性I:多个事务不相互影响;
- 持久性D:事务提交后修改是永久的;
事务隔离级别
- 读未提交(脏读):READ UNCOMMITTED,事务A可以读取到事务B未提交的数据;
- 读已提交(不可重复读):READ COMMITTED,事务A只可以读取到事务B已提交的数据,每次都能读到真实的数据,这回导致在事务A中多次读取的数据不一致;
- 可重复读(幻读):REPEATABLE READ,事务A读取到数据后,只要事务还不结束,每次读取都是一样;这样如果事务B提交了数据,事务A也读取不到,容易产生幻读;
- 序列化:SERIALIZABLE,事务A执行过程中,事务B被阻塞。
查看事务隔离级别,MySQL默认隔离级别为 REPEATABLE READ
SELECT @@GLOBAL.tx_isolation;
设置事务隔离级别
-- 设置全局事务隔离级别为:读未提交
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- 设置全局事务隔离级别为:读已提交
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 设置全局事务隔离级别为:可重复读
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 设置全局事务隔离级别为:系列化
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
测试事务隔离级别 READ UNCOMMITTED :
-- 第一步:打开cmd窗口1,开启事务
BEGIN;
-- 第二步:窗口1查询输出2条数据
SELECT * FROM `login_user`;
-- 第五步:窗口1查询到了2未提交的数据,产生了脏读
SELECT * FROM `login_user`;
-- 第三步:打开cmd窗口2,开启事务
BEGIN;
-- 第四步:插入数据,但是不提交
INSERT INTO `login_user`(`loginName`,`loginPwd`) VALUES('guest','guest147258');
索引
索引是帮助MySQL快速获取获取排序好的数据结构。
索引原理
如果我们在根据条件搜索数据时,一种方式是在数据文件中,把数据全部遍历一遍然后取出数据;
还有一种就是使用查询的条件建立目录,在查询数据时先去目录里面搜索一下,看有没有,有的话直接根据目录到数据中去找到对应的数据,就不用去直接遍历数据文件了,一般数据文件肯定是比目录大得多。
假设数据库存储了10GB的数据,如果不加索引,查询时就会遍历全部数据,但是我们单独把其中一个字段拿来建立一个索引目录,假设这是索引目录文件只有10MB,这时查询10MB的索引就明显比直接去遍历10GB的文件速度快的多。
MySQL中索引是使用B+Tree存储的,这种数据结构最擅长的就是搜索数据,几千万行的索引数据能很快就搜索到目标数据,这时索引在数据量很大的情况下,索引就相当的重要。
在MySQL中,主键PRIMARY KEY会自动创建索引,唯一约束UNIQUE字段也会自动创建索引。
索引的分类
- 主键索引(PRIMARY KEY)
- 标记有
PRIMARY KEY的字段,主键索引不能重复。
- 标记有
- 唯一索引(UNIQUE KEY)
- 设置为唯一索引的字段不能重复。
- 常规索引(INDEX)
- 使用index来创建的索引,可根据索引规则来提高查询速度。
- 全文索引(FULLTEXT)
索引的应用
- 索引的创建
-- 显示 app_user 表的索引信息
SHOW INDEX FROM `app_user`;
-- 创建常规索引
-- 格式 CREATE INDEX 索引名称 ON 表名(索引字段名);
CREATE INDEX index_name ON `app_user`(`name`);
- 删除索引
-- 删除语法
-- DROP INDEX 索引名称 ON `表名`;
DROP INDEX index_name ON `app_user`;
联合索引
索引最左前缀在排序时会按照左边字段依次排序;- 在查询时按照索引字段依次筛选,快速查询出数据,如果不按照顺序就无法使用联合索引;
-- 创建联合索引
CREATE UNIQUE INDEX `idx_name_phone_age` ON `app_user`(`name`,`phone`,`age`) USING BTREE COMMENT '姓名-电话-年龄 联合索引';
-- 走索引,type=ref
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户14';
-- 走索引,type=ref
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户14' AND `age`=68;
-- 走索引,type=range
EXPLAIN SELECT * FROM `app_user` WHERE `name` LIKE '14%';
-- 不走索引,type=all
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户14' OR `age`=68;
EXPLAIN SELECT * FROM `app_user` WHERE `name` LIKE '%用户14';
EXPLAIN SELECT * FROM `app_user` WHERE `phone`='18620769501' AND `age`=68;
EXPLAIN SELECT * FROM `app_user` WHERE `phone`='18620769501';
索引失效
- 如果在索引字段上使用模糊查询,并且使用
左模糊查询,索引将不能生效。
-- 右模糊,走索引,type=range
SELECT * FROM `app_user` WHERE `name` LIKE '14%';
-- 左模糊,不走索引,type=all
SELECT * FROM `app_user` WHERE `name` LIKE '%14';
- 在条件中使用了OR,但是OR的条件字段没有全部添加索引,会导致整体索引失效。
-- 如果给name字段添加了索引phone字段没有索引
-- name字段字段的索引也会失效
-- 可以单独查询name字段,然后再查询phone字段,最后使用union连接起来,优化查询速度
SELECT * FROM `app_user` WHERE `name`='用户14' OR `phone`='18620769501';
- 联合索引不按照索引的顺序查询,导致索引失效,详情查看联合索引案例。
- 索引列参加了运算或者使用了函数,也会导致索引失效。
-- 索引字段ID参与了计算,这会导致id字段的索引失效
EXPLAIN SELECT * FROM `app_user` WHERE `id`+1 = 2;
-- 索引字段name被函数SUBSTR处理了,这会导致name字段的索引失效
EXPLAIN SELECT * FROM `app_user` WHERE SUBSTR(`name`,1,2) = '用户';
- 尽量使用覆盖索引,避免使用select *。索引查询时,如果直接查询参加索引的字段信息,mysql会直接从索引树中读取信息,但是如果获取了没有参与索引的字段,mysql就会进行回表查询。
-- 走了索引,但数据是回表查询到的
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户14';
-- 走了索引,数据直接从索引树中获取,没有进行回表查询,查询速度比回表查询快
EXPLAIN SELECT `name`,`phone`,`age` FROM `app_user` WHERE `name`='用户14';
-
如果MySQL评估使用索引比全表扫描慢,就会放弃使用索引。
-
如果索引字段基本上都是非NULL的,这时使用
IS NULL走索引,IS NOT NULL不走索引。
-- gender 字段基本不为NULL,走索引
EXPLAIN SELECT * FROM `app_user` WHERE `gender` IS NULL;
-- gender 字段基本不为NULL,IS NOT NULL不走索引
EXPLAIN SELECT * FROM `app_user` WHERE `gender` IS NOT NULL;
数据库三范式
- 范式一:表必须拥有主键,每个字段是原子的不可再分。
- 范式二:非主键字段完全依赖主键,不要产生部分依赖。
- 范式三:非主键字段直接依赖主键,不要产生传递依赖。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号