

JAVA实训一——词频统计
实验小组:领航员:16012012张志贤 组员:16012014李鑫
码云地址:https://gitee.com/lixin-123/practical_training
实验背景:
本次实验,是由小组内两人完成。按照要求,和一个伙伴坐在一起,并肩作战,面对着同一台显示器,使用着同一键盘,同一个鼠标,一起思考,一起分析,一起编程,一起做博客园,写结束语,并肩地、平等地、互补地完成作业。
试验功能:
1. 文件输入,从控制台由用户输入到文件中,再对文件进行统计;
2.支持命令行输入英文作品;
3.支持命令行输入存储有英文作品文件的目录名,批量统计;
4.从控制台读入英文单篇作品,重定向输入流。
实现现象:
1.判断输入方式,如果从命令行传递参数(精美英语短文)则直接对文件进行统计;如果未传递参数,则支持传入文件路径,并且对其目录中的文件进行统计。
2.修改,使其能够按词频降序排列的同时,对同频率的单词进行降序排列。
3. 解决了报错的问题,由于操作的一些小失误,我们决定在总体思路决定后,在进一步纠错,加以改正,最后整理一下输出页面,保证看上去简洁大方。
代码片段:
import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; import java.util.Map; import java.util.Map.Entry; import java.util.TreeMap; import java.util.Scanner; /** * * @author cute * * * 实现从文件中读入英文文章,统计单词个数,并按值从大到小输出 */ public class wf { public static void main(String[] args) { //主程序逻辑入口 while (true) { System.out.println("本程序有三种模式:1.单行语言处理;2.单个文件处理;3.批量处理;0.退出程序\n请键入1 2 3选择您需要的模式,模式2指定具体路径为d盘根目录"); Scanner readerScanner = new Scanner(System.in); int flag = readerScanner.nextInt(); if (flag == 0) { break; } else if (flag == 1) { try { System.out.println("当前为当行语言处理模式,请输入您要评测的语句"); BufferedReader bf =new BufferedReader(new InputStreamReader(System.in)); //读取命令行中一行 String s=bf.readLine(); LineCode(s); } catch (IOException ex) { System.out.println("请按单行输入句子"); } } else if (flag == 2) { System.out.println("当前为单个文件处理模式,请输入您要输入的文件名,格式:aaa.txt"); String s = readerScanner.next(); try { TxtCode(s); } catch (Exception ex) { System.out.println("请输入正确的文件名称,确定后文件存在以及文件是否放在d:根目录下"); } } else if(flag==3){ System.out.println("当前为批量文件处理模式,请输入文件具体路径,格式:d:/ljr"); String path=readerScanner.next(); File file =new File(path); if (file.isDirectory()) { File[] filelist =file.listFiles(); for(File file1:filelist){ try { String s=file1.getPath();//地址回溯 System.out.println(s); FileCode(s); } catch (Exception ex) { System.out.println("请输入正确的路径,若程序无法结束请重新运行程序"); } } } } } System.out.println("程序结束"); } //统计单个文件 public static void TxtCode(String txtname) throws Exception { BufferedReader br = new BufferedReader(new FileReader("F:/LIXIN/duanluo.txt" )); List<String> lists = new ArrayList<String>(); //存储过滤后单词的列表 String readLine = null; while ((readLine = br.readLine()) != null) { String[] wordsArr1 = readLine.split("[^a-zA-Z]"); //过滤出只含有字母的 for (String word : wordsArr1) { if (word.length() != 0) { //去除长度为0的行 lists.add(word); } } } br.close(); StatisticalCode(lists); } //统计单行 public static void LineCode(String args) { List<String> lists = new ArrayList<String>(); //存储过滤后单词的列表 String[] wordsArr1 = args.split("[^a-zA-Z]"); //过滤出只含有字母的 for (String word : wordsArr1) { if (word.length() != 0) { //去除长度为0的行 lists.add(word); } } StatisticalCode(lists); } public static void FileCode(String args) throws FileNotFoundException, IOException { BufferedReader br = new BufferedReader(new FileReader(args)); List<String> lists = new ArrayList<String>(); //存储过滤后单词的列表 String readLine = null; while ((readLine = br.readLine()) != null) { String[] wordsArr1 = readLine.split("[^a-zA-Z]"); //过滤出只含有字母的 for (String word : wordsArr1) { if (word.length() != 0) { //去除长度为0的行 lists.add(word); } } } br.close(); StatisticalCode(lists); } public static void StatisticalCode(List<String> lists) { //统计排序 Map<String, Integer> wordsCount = new TreeMap<String, Integer>(); //存储单词计数信息,key值为单词,value为单词数 //单词的词频统计 for (String li : lists) { if (wordsCount.get(li) != null) { wordsCount.put(li, wordsCount.get(li) + 1); } else { wordsCount.put(li, 1); } } // System.out.println("wordcount.Wordcount.main()"); SortMap(wordsCount); //按值进行排序 } //按value的大小进行排序 public static void SortMap(Map<String, Integer> oldmap) { ArrayList<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(oldmap.entrySet()); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { return o2.getValue() - o1.getValue(); //降序 } }); for (int i = 0; i < list.size(); i++) { System.out.println("文中的单词:"+list.get(i).getKey()+"出现次数:" +list.get(i).getValue()); } } }
功能1:
运行结果: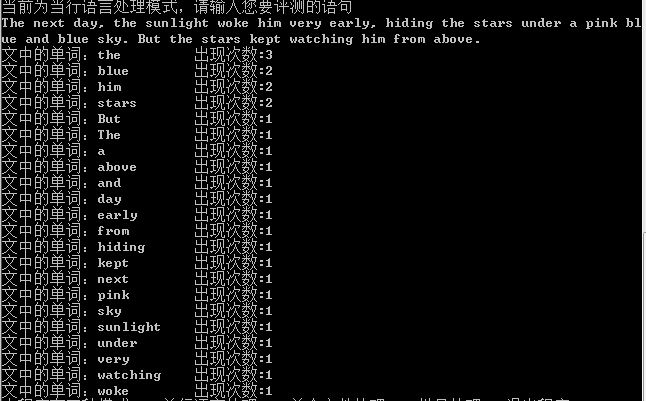
功能2: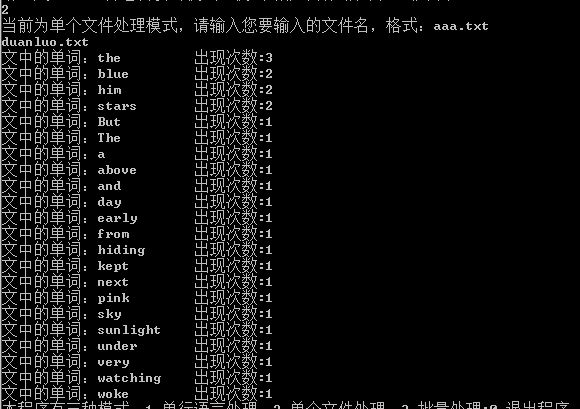
实验心得:对于这次结对编程,收获很多,实验一的开始到结束都是由我们两个共同完成,一起思考解决问题的方法,分享自己对问题的看法以及解题的思路,不仅如此结对编程的过程也是一个互相督促的过程。由于两个人的这种合作,使得我们更认真地工作,频繁地交流,提高自己的能力。第一次面对这种模式的考核,刚开始有些手足无措,不过慢慢磨合下来,我发现优点要大于缺点。一个简单的例子,我们的代码准确率明显提高,现在,一个人在敲代码的时候,另一个人就是她的督导,错误可以及时被发现,避免许多复查的可能性,其次,我们可以互相敲代码,提倡“间歇式”敲代码,大大的提高了效率,达到了1+1>2的效果。
实验过程图片:
汉堡包:优点:我的小伙伴做事认真负责,她作为这次实验的领航员,指引我,能及时发现实验过程中发现的错误,及时帮助改正,使我们的效率大大的提高,也会分享给我她的想法,思路很 用心
缺点:压力过大,耐心不足
希望改正:希望学会调节自己的压力并且还希望能多多培养自己的耐心。


