
hive10
第 6 章 查询
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
查询语句语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
6.1 基本查询(Select…From)
6.1.1 全表和特定列查询
0)数据准备
(0)原始数据
dept:
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
emp:
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
(1)创建部门表
create table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';
(2)创建员工表
create table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
(3)导入数据
load data local inpath '/opt/module/datas/dept.txt' into table
dept;
load data local inpath '/opt/module/datas/emp.txt' into table emp;
1)全表查询
hive (default)> select * from emp;
hive (default)> select empno,ename,job,mgr,hiredate,sal,comm,deptno from
emp ;
2)选择特定列查询
hive (default)> select empno, ename from emp;
注意:
(1)SQL 语言大小写不敏感。
(2)SQL 可以写在一行或者多行
(3)关键字不能被缩写也不能分行
(4)各子句一般要分行写。
(5)使用缩进提高语句的可读性。
6.1.2 列别名
1)重命名一个列
2)便于计算
3)紧跟列名,也可以在列名和别名之间加入关键字‘AS’
4)案例实操
查询名称和部门
hive (default)> select ename AS name, deptno dn from emp;
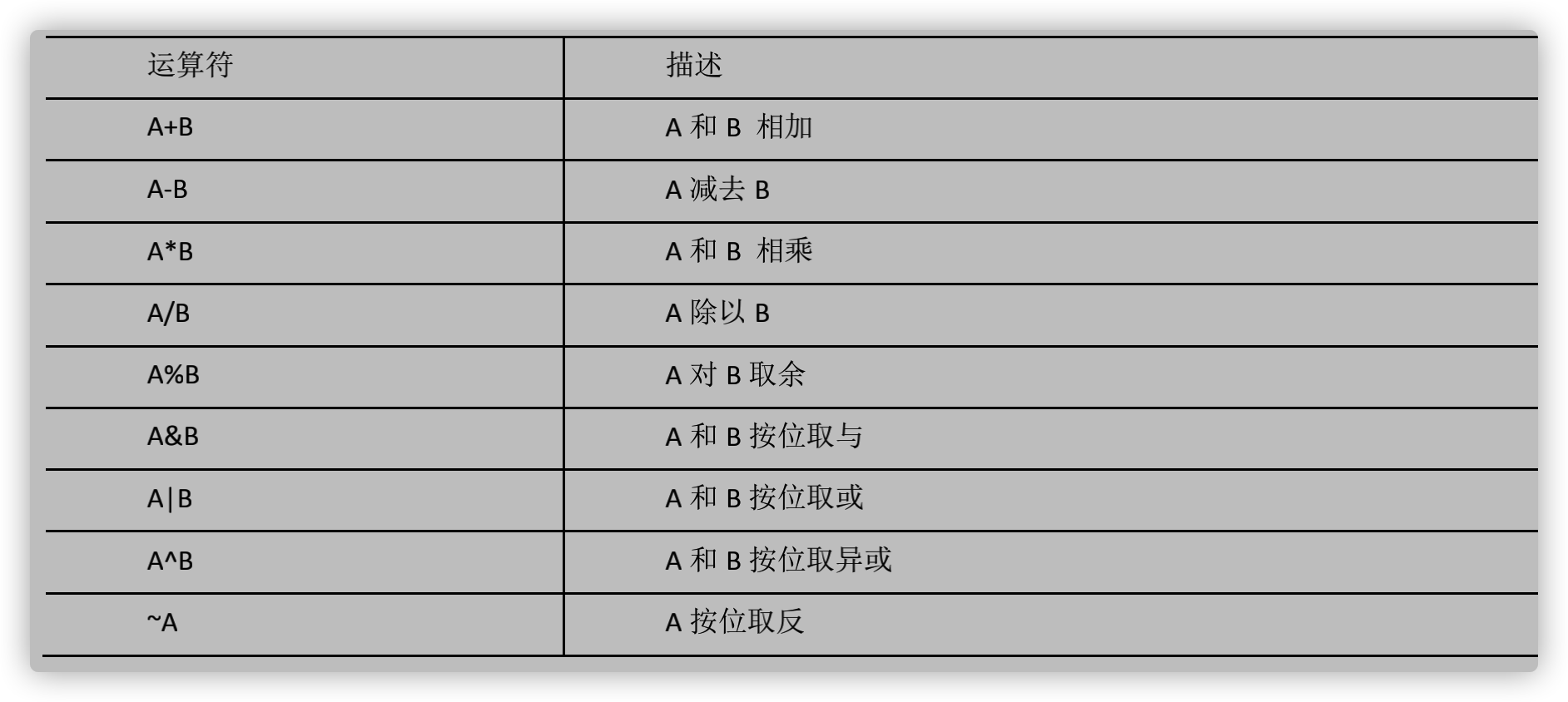
6.1.3 算术运算符
6.1.4 常用函数
1)求总行数(count)
hive (default)> select count(*) cnt from emp;
2)求工资的最大值(max)
hive (default)> select max(sal) max_sal from emp;
3)求工资的最小值(min)
hive (default)> select min(sal) min_sal from emp;
4)求工资的总和(sum)
hive (default)> select sum(sal) sum_sal from emp;
5)求工资的平均值(avg)
hive (default)> select avg(sal) avg_sal from emp;
6.1.5 Limit 语句
典型的查询会返回多行数据。LIMIT 子句用于限制返回的行数。
hive (default)> select * from emp limit 5;尚硅谷大数据技术之 Hive
hive (default)> select * from emp limit 2;
6.1.6 Where 语句
1)使用 WHERE 子句,将不满足条件的行过滤掉
2)WHERE 子句紧随 FROM 子句
3)案例实操
查询出薪水大于 1000 的所有员工
hive (default)> select * from emp where sal >1000;
注意:where 子句中不能使用字段别名。

