分布式限流篇
具体内容请看作者:https://mp.weixin.qq.com/s/dfI9h8bdYgZ60UeByphhYQ
在系统设计中,限流是保障系统高可用的一种常规手段,并且还有熔断,服务降级…
对于系统接入大量的业务线,导致流量非常大,一些系统承受不住被搞挂。
Martin有几种方法来进行系统优化。
1、限流:对应用入口流量做控制,瞬时流量向后迁移,对下游请求流量做自适应限流,根据接口响应时间动态调整流量。
2、延迟排队:如果请求量大,按业务线优先级排队,优先保障线上渠道实时的请求。
3、路由:这个是因为业务的特殊性,所有的请求都依赖于下游第三方的服务,可以将多家下游服务供应商做个动态路由表,将请求优先路由给接口成功率高,耗时低的服务供应商。
4、备份:这基本是所有分布式组件都会做的,能做多机的不做单机的,比如说Redis做三主三备(集群)、MySQL分库分表、MQ与Redis互为备份等等。
5、降级:这个是最后的迫不得已的措施,如果遇到全线崩溃,使用降级手段保障系统核心功能可用,或让模块达到最小可用。
6、日志:完整的监控和链路日志,日志的功能很多,一方面是方面排查问题,另一方面可用来做任务重试、任务回滚、数据恢复、状态持久化等。
那怎么去实现限流呢?
一般是单机的话,可以通过Semphore限制统一时间请求接口的量,也可以用Google Guava包提供的限流包。
但是如果是分布式环境的话,也可以使用Redis实现,当然也有阿里的Sentinal或Spring Cloud Gateway都可以实现限流。
现在我们可以用单机模式来测试一下:
1 private static Semphore semphore = new Semphore(3); 2 3 private static String[] userName = {"Krics","Martin","Mark"}; 4 //设置一个随机数 5 private static Random random = new Random(); 6 7 //厕所类 8 public static class Tailet{ 9 10 public void enter(User user){ 11 try{ 12 semphore.acquire(); 13 if(Thread.interrupated()){ 14 return; 15 } 16 System.out.println("时间:"+ DateAndTimeUtil.getFormattedDate() + "" + user.getName() + "上厕所"); 17 Thread.sleep(2000); 18 19 20 }catch(InterrupteException ex){ 21 22 23 24 }Finally{ 25 semphore.release(); 26 } 27 28 } 29 } 30 31 public static void main(String[] args){ 32 33 ExecutorService executorService = Executors.newFixedThreadPool(10); 34 35 Toilet toilet = new Toilet(); 36 37 for(int i = 0; i < 20; i++){ 38 39 executorService.submit(()->{ 40 toilet.enter(new User(userName[random.nextInt(3)])); 41 }); 42 } 43 44 45 46 }
解释:
使用semphore定义,semphore就是一种锁机制,进了厕所,在门上加锁。
也就是每次只有三个人上厕所。
那么分布式环境怎么解决呢?
当然也是控制资源的访问频率,一般主流的设计思想有两种:
1.漏洞算法:把请求比作水,在请求入口和响应请求的服务之间加一个漏桶,桶中的水以恒定的速度流出,这样就保证了服务接收到的流量速度是稳定的。
如果桶里的水是满的状态的话,再进来的水也会直接溢出的(请求直接拒绝)。
2.令牌桶算法:控制发送到网络上的数据的数目,并允许突发数据的发送。(在处理请求的时候,先尝试在桶中获取令牌,如果没有拿到令牌,第一种就是直接返回拒绝请求,第二种就是等待一段时间,再次尝试获取令牌)。
google 的Guava包中的RateLimiter就是令牌桶算法。
其实这两种算法差别不大,一个是在接口处控制恒定的速率,另一种就是以恒定的速率放令牌。但是令牌桶的算法更灵活一些。
为什么这么说呢?
令牌桶相比漏桶来说有一个优势,能够满足突发流量的请求。
比如说:如果线上的环境资源很空闲,因为漏洞水流出的速度恒定,请求因为速度受限不会及时得到相应。在者说,现在漏洞的水速度是3个每秒,现在线上来了5个请求,全部进漏桶,漏桶里面现在也只有5个请求,但是也只能一秒处理3个请求。 但是如果是;令牌桶算法的话,放入令牌的速度是3个每秒,假设令牌桶中已经有两个令牌了,这个时候来了5个请求,都能拿到令牌完成请求,因此令牌桶算法是面向需求的。
讲讲 Google Guava怎么实现令牌桶算法的?
API 很简单,只需要指定限流的速度,例如第一个, 速度是每秒钟2个,如果是分钟级限流,你也可以设置为 0.2,代表1秒钟生成0.2 个令牌,1分钟限流为 12个。第二个例子是每秒钟5000,这个例子演示了如何通过限流器限制网络处理流量为每秒钟 5kb。5000个byte。
Guava 还有很多方法,如下:
返回值和方法修饰符 方法和描述
double acquire()
从RateLimiter获取一个许可,方法会被阻塞直到获取到请求
double acquire(int permits)
从RateLimiter获取指定许可数,方法会被阻塞直到获取到请求
static RateLimiter create(double permitsPerSecond)
根据每秒放到令牌桶数量创建RateLimiter,这里的令牌桶数量是指每秒生成令牌数(通常是指QPS,每秒多少查询)
static RateLimiter create(double permitsPerSecond, long warmupPeriod, TimeUnit unit)
根据每秒放到令牌桶数量和预热期来创建RateLimiter,意思是不会一下生成全部的令牌,把令牌桶塞满,而是会渐进式的增加令牌,这里的每秒放到令牌桶数量是指每秒生成令牌数(通常是指QPS,每秒多少个请求量),在这段预热时间内,RateLimiter每秒分配的许可数会平稳地增长直到预热期结束时达到最大。
double getRate()
返回RateLimiter 配置中的稳定速率,该速率单位是每秒生成多少令牌数
void setRate(double permitsPerSecond)
更新RateLimite的稳定速率,参数permitsPerSecond 由构造RateLimiter的工厂方法提供。
boolean tryAcquire()
从RateLimiter 获取许可,如果该许可可以在无延迟下的情况下立即获取得到的话
boolean tryAcquire(int permits)
从RateLimiter 获取许可数,如果该许可数可以在无延迟下的情况下立即获取得到的话
boolean tryAcquire(int permits, long timeout, TimeUnit unit)
从RateLimiter 获取指定许可数如果该许可数可以在不超过timeout的时间内获取得到的话,或者如果无法在timeout 过期之前获取得到许可数的话,那么立即返回false (无需等待)
分布式限流呢?
分布式就是把本地的令牌桶放到一个所有主机都可以访问的地方。
一般是放到分布式的中间件,例如Redis,分布式缓存,并且生成令牌和获取令牌都可以用redis的指令来实现,速度还快。
怎么实现的呢?
在令牌桶算法中,有一个单独的生产者以恒定的速度向令牌桶中放入令牌,如果通过redis来实现的话,一个生产者线程不断往redis添加令牌,其他的请求线程每次请求读redis获取令牌,这样会有很大的性能消耗,好的解决办法是延迟令牌的操作,获取令牌的时候才放入令牌,将第二个操作合并。
获取令牌的时候怎么计算应该放入桶中多少令牌呢?
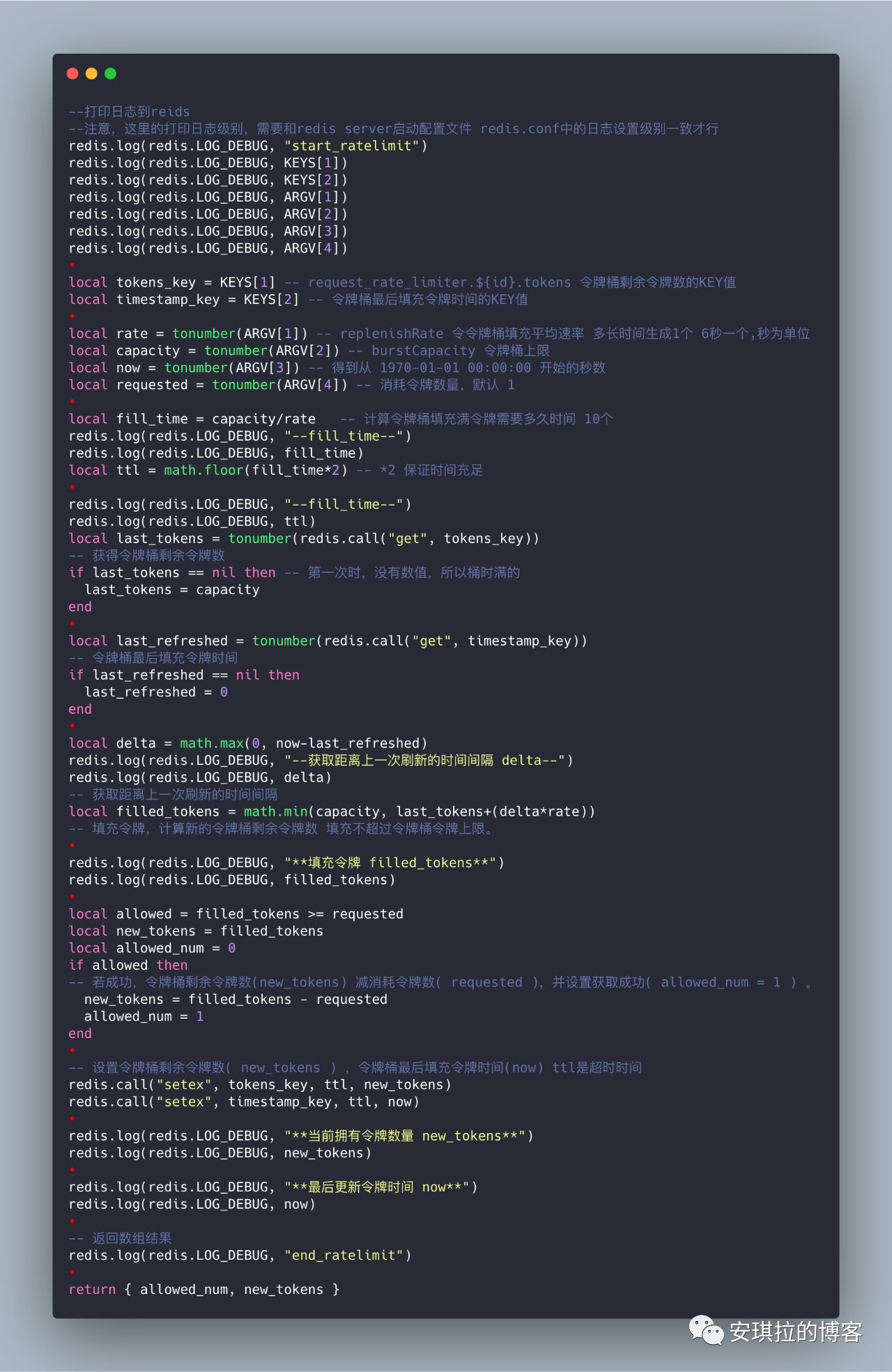
filledTokens为这一次需要放入令牌的数量,计算逻辑为:
filledTonkens = math.min(lastTokens + (delta * rate),capacity)
此刻应填充的令牌数 = min((令牌桶剩余令牌数 + 当前时间与上一次令牌生成时间间隔*令牌生成的速度),令牌总容量)
所以
我们可以写一个分布式限流的Redis脚本,redis提供lua支持
测试:
可以输入help查看完整的命令,常用n和print,分别打印为下一行和打印当前局部变量。
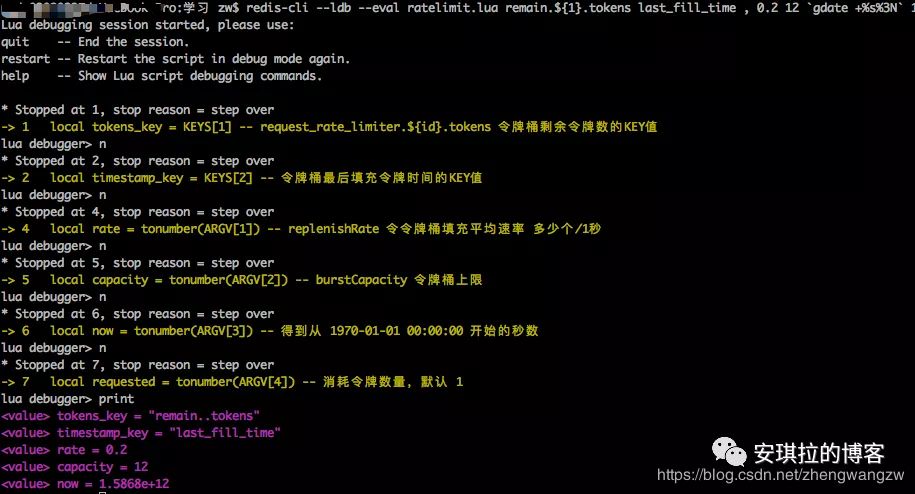
————————————————————————————————————————
lua脚本的执行会不会有性能上的损耗,比较redis是单线程的?
redis使用epoll实现I/O多路服用的事件驱动模型,对于每一个读取和写入操作都尽量要快速,所以我们需要对编写的lua 脚本做个压测,redis提供了压测指令 redis-benchmark,测试10万脚本的执行,命令如下:
redis-benchmark -n 100000 evalsha ebbcd2ed99990afaca6d2ba61a0f2d5bdd907e59 2 remain.${1}.tokens last_fill_time 0.2 12 `gdate +%s%3N` 1
实际效果: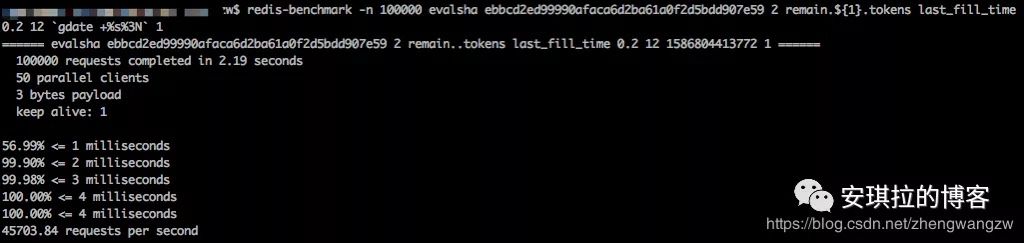
99.9%都在2ms内完成,损耗可以接受。
********怎么把分布式限流lua放到springboot工程中呢?
首先
1.手写一个lua脚本(上面的可以直接拷贝),在spring工程目录中放好,
2.程序启动时加载lua脚本,根据脚本lua的SHA1值判断脚本是否已经加载到redis(redis不能存太多的script),程序如下:
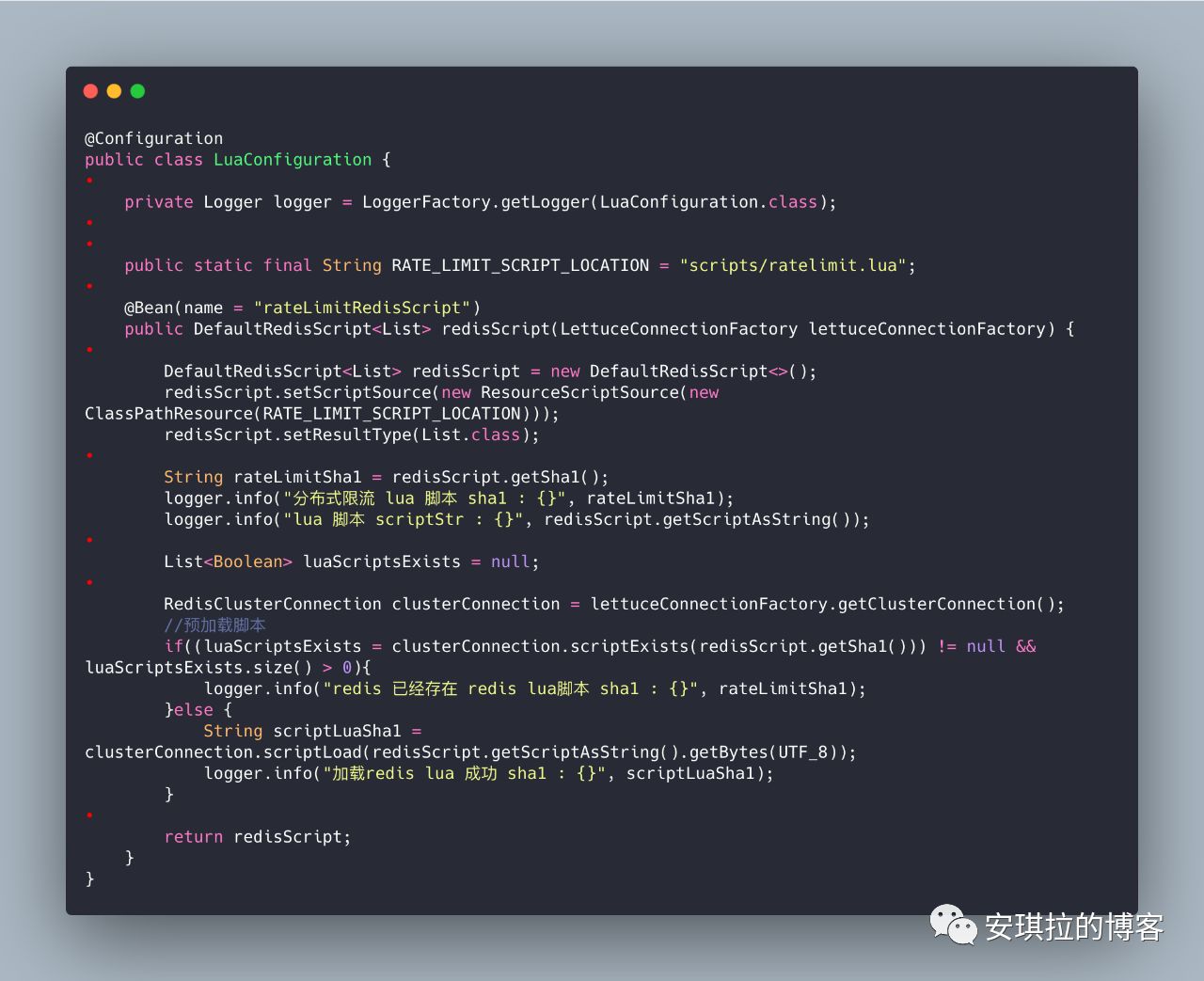
这个程序启动,加载脚本,检查脚本在redis中是否存在,脚本如果没有重新编辑更新,sha1是一只的,不会重复加载,另外注意到一点,如果是集群模式,jedis 3.*版本以前是不支持lua脚本的,建议使用Lettuce
1. 关于Lettuce和jedis客户端的对比,大家可以在网上看一下,Spring Boot客户端已经改成Lettuce了
2.配置限流器
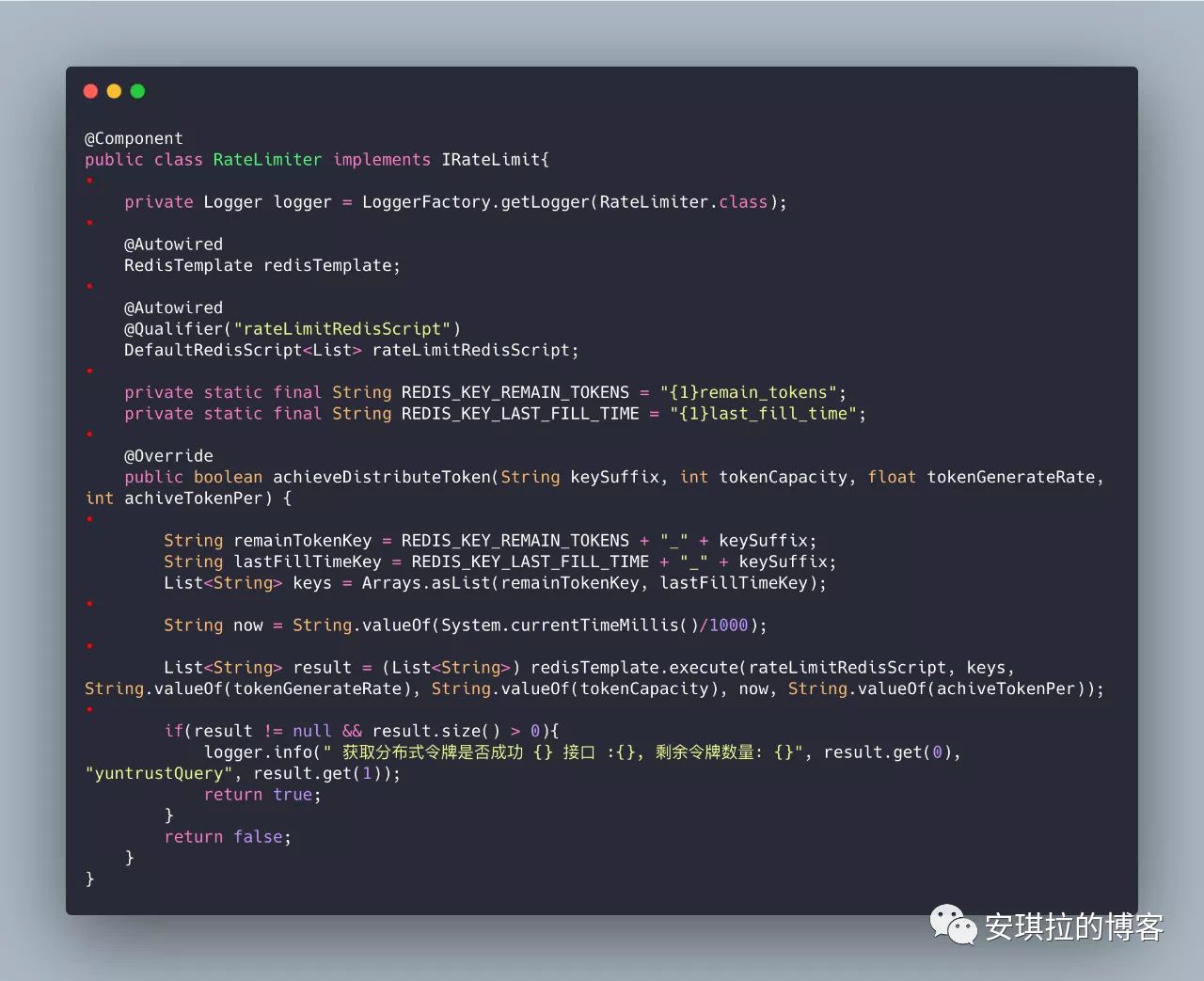
这里有一点注意一下,key都带了{1}的前缀,这个用于所有的key在集群模式都hash命中同一个shot(槽),因为lua脚本不能在跨集群节点执行。
效果:
