


String类源码解析
1. String是使用char[]数组来存储的,并且String值在创建之后就不可以改变了。char[]数组的定义为:
1 2 | /** The value is used for character storage. */private final char value[]; |
char[]数组value使用final修饰,因此赋值之后就不可以改变了。再看一下String的hashCode()方法的实现就更能说明这一点:
1 2 | /** Cache the hash code for the string */private int hash; // Default to 0 |
成员变量hash,用来缓存String对象的hash code。为什么可以缓存?
因为String对象不可以改变,求hash code也不会变,因此有了缓存,不需要每次都求。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | /** * Returns a hash code for this string. The hash code for a * <code>String</code> object is computed as * <blockquote><pre> * s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] * </pre></blockquote> * using <code>int</code> arithmetic, where <code>s[i]</code> is the * <i>i</i>th character of the string, <code>n</code> is the length of * the string, and <code>^</code> indicates exponentiation. * (The hash value of the empty string is zero.) * * @return a hash code value for this object. */public int hashCode() { // hash值为缓存值 int h = hash; // 如果缓存的hash值为0,表示已经求过hash值,所以直接返回该值 // 如果是空字符串,那么hash值为0 if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h;} |
2. String的构造函数有多个,空串的构造函数为:
1 2 3 4 5 6 7 8 | /** * Initializes a newly created {@code String} object so that it represents * an empty character sequence. Note that use of this constructor is * unnecessary since Strings are immutable. */public String() { this.value = new char[0];} |
从代码可以看出,该构造方法生成一个空的char序列,就如注释所说“使用该构造方法是没有任何意义的”。
最常用的构造方法莫过于new String(String original):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | /** * Initializes a newly created {@code String} object so that it represents * the same sequence of characters as the argument; in other words, the * newly created string is a copy of the argument string. Unless an * explicit copy of {@code original} is needed, use of this constructor is * unnecessary since Strings are immutable. * * @param original * A {@code String} */public String(String original) { this.value = original.value; this.hash = original.hash;} |
该构造方法其实copy了original的value值和hash值,他们还是使用的同一串char序列。但是又创建了一个新的String对象,和original是不同的对象了。
3. 接下来通过一个例子来了解String是如何存储的。了解之前先回顾下java内存分配的几个术语:
栈:由JVM分配区域,用于保存线程执行的动作和数据引用。栈是一个运行的单位,Java中一个线程就会相应有一个线程栈与之对应。
堆:由JVM分配的,用于存储对象等数据的区域。
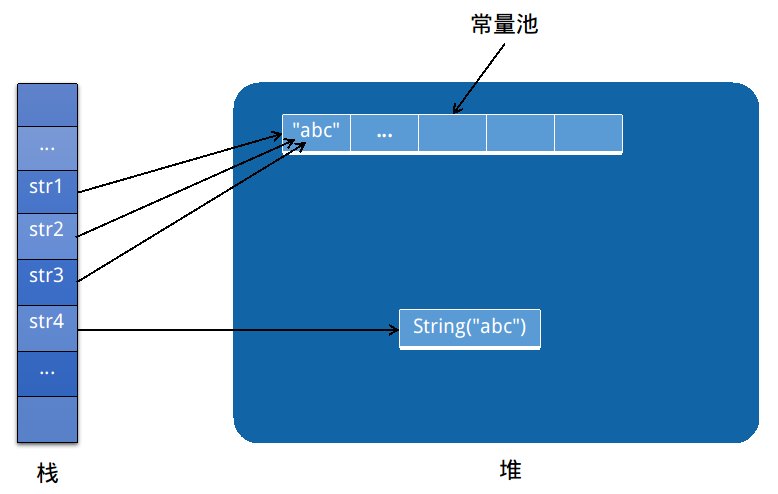
常量池:在编译的阶段,在堆中分配出来的一块存储区域,用于存储显式(不是通过new生成的)的String,float或者integer.例如String str="abc"; abc这个字符串是显式声明,所以存储在常量池。
例子:
1 2 3 4 5 6 7 8 9 10 | String str1 = "abc";String str2 = "abc";String str3 = "ab" + "c";<br>String str4 = new String(str2);<br>//str1和str2引用自常量池里的同一个string对象System.out.println(str1 == str2); // true<br>//str3通过编译优化,与str1引用自同一个对象System.out.println(str1 == str3); // true<br>//str4因为是在堆中重新分配的另一个对象,所以它的引用与str1不同System.out.println(str1 == str4); // false |
- 第一个“str1 == str2”很好理解,因为在编译的时候,"abc"被存储在常量池中,str1和str2的引用都是指向常量池中的"abc"。所以str1和str2引用是相同的。
- 第二个“str1 == str3”是由于编译器做了优化,编译器会先把字符串拼接,再在常量池中查找这个字符串是否存在,如果存在,则让变量直接引用该字符串。所以str1和str3引用也是相同的。
- str4的对象不是显式赋值的,编译器会在堆中重新分配一个区域来存储它的对象数据。所以str1和str4的引用是不一样的。
图形化示例如下图所示:
3. 常用的equals()方法就比较朴实了,就是依次比较字符是否相同,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String) anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false;} |
4. String实现了Comparable接口,自然有其compareTo()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | public int compareTo(String anotherString) { int len1 = value.length; int len2 = anotherString.value.length; // 获取两个String串的最小长度 int lim = Math.min(len1, len2); char v1[] = value; char v2[] = anotherString.value; int k = 0; // 依次比较两个String串最小长度范围内的相同位置的字符是否相同 // 如果不同,则返回Unicode编码的差值 while (k < lim) { char c1 = v1[k]; char c2 = v2[k]; if (c1 != c2) { return c1 - c2; } k++; } // 如果最小长度范围内的字符完全相同,则返回两个String串的长度之差 return len1 - len2;} |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决