


HashMap代码解析
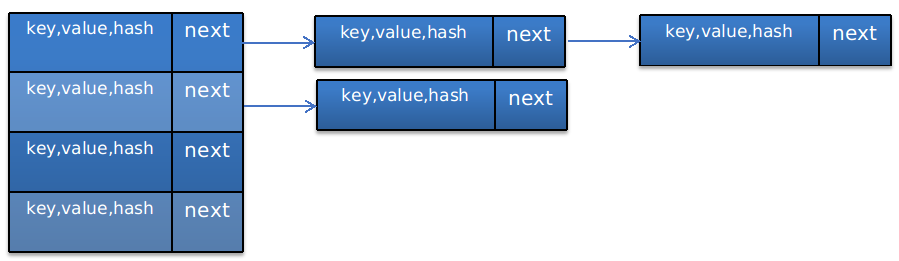
hashmap (jdk 1.7)使用 “数组-链表” 方式进行存储,图形化表示如下:

即,前面是一个数组,后面跟一个链表,那么数据结构这个对应到HashMap的代码里面是什么样子的呢?
在HashMap中定义了一个类型为Entry<K,V>的数组table,上图就是显示了这个table。
1 2 3 4 | /** * The table, resized as necessary. Length MUST Always be a power of two. */transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; |
类型Entry<K,V>的定义如下:
1 2 3 4 5 6 7 | static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; // 省略构造/get/set等函数} |
由Entry<K,V>的定义可知,上图每个节点中其实存了4个变量:
key表示键,即存入map的键值
value表示值,即存入map的值
next表示下一个Entry节点
hash表示key的哈希值。
那么上图准确表示应该是:
对于HashMap,最常用的莫过于直接使用默认构造函数创建一个Map对象了
1 | Map<int, String> map = new HashMap<>(); |
这里HashMap调用了
1 2 3 4 5 6 7 | /** * Constructs an empty <tt>HashMap</tt> with the default initial capacity * (16) and the default load factor (0.75). */public HashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);} |
其中,DEFAULT_INITIAL_CAPACITY是
1 2 3 4 | /** * The default initial capacity - MUST be a power of two. */static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 |
DEFAULT_LOAD_FACTOR是
1 2 3 4 | /** * The load factor used when none specified in constructor. */static final float DEFAULT_LOAD_FACTOR = 0.75f; |
this()调用的是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | /** * Constructs an empty <tt>HashMap</tt> with the specified initial * capacity and load factor. * * @param initialCapacity the initial capacity * @param loadFactor the load factor * @throws IllegalArgumentException if the initial capacity is negative * or the load factor is nonpositive */public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init();} |
了解了基本结构之后,看一下HashMap的put()和get()方法是如何实现的。
首先,看put()方法,再了解put()方法之前,先了解几个put()方法会调用的几个辅助方法:
1. inflateTable(),给表充气 or 让表膨胀?原来table对象是空的,所以需要将table对象初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | /** * Inflates the table. */private void inflateTable(int toSize) { // Find a power of 2 >= toSize // capacity 表示HashpMap的容量,必须是2的倍数 int capacity = roundUpToPowerOf2(toSize); // threshold 表示需要resize的阈值 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); // 初始化大小为capacity的table对象 table = new Entry[capacity]; // 初始化 hashSeed initHashSeedAsNeeded(capacity);} |
2. putForNullKey()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | /** * Offloaded version of put for null keys */private V putForNullKey(V value) { // 遍历table[0],如果已经有key为null的元素,直接返回对应的value for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 如果没有key为null的元素, // 将HashMap的修改次数+1 modCount++; // 将key为null的元素添加到HashMap中 addEntry(0, null, value, 0); return null;} |
疑问:key为null的元素的hash值一定为0吗?
3. hash(),求对象的hash值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | /** * Retrieve object hash code and applies a supplemental hash function to the * result hash, which defends against poor quality hash functions. This is * critical because HashMap uses power-of-two length hash tables, that * otherwise encounter collisions for hashCodes that do not differ * in lower bits. Note: Null keys always map to hash 0, thus index 0. */final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4);} |
4. indexFor(),根据对象的hash值以及HashMap table的长度,寻找该对象的索引位置
1 2 3 4 5 6 7 | /** * Returns index for hash code h. */static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1);} |
这里没有使用hash值h对长度length取余,而是使用的位运算?其实两者结果是一样的,h % length == h & (length -1)
5. addEntry()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | /** * Adds a new entry with the specified key, value and hash code to * the specified bucket. It is the responsibility of this * method to resize the table if appropriate. * * Subclass overrides this to alter the behavior of put method. */ void addEntry(int hash, K key, V value, int bucketIndex) { // size是HashMap中元素的个数 // threshhold = capacity * load factor,表示需要扩容resize的阈值 // 如果size > threshold,并且table在当前索引处有元素,不为null,则需要扩容HashMap,并从新计算索引值 if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } // 将元素加入到HashMap createEntry(hash, key, value, bucketIndex); } |
6. createEntry()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | /** * Like addEntry except that this version is used when creating entries * as part of Map construction or "pseudo-construction" (cloning, * deserialization). This version needn't worry about resizing the table. * * Subclass overrides this to alter the behavior of HashMap(Map), * clone, and readObject. */void createEntry(int hash, K key, V value, int bucketIndex) { // 这里是获取某个链表的第一个节点e, // 因为每次插入都是往链表的头部插入的,因此e就作为了新节点的next值 Entry<K,V> e = table[bucketIndex]; // e作为新节点的next值 table[bucketIndex] = new Entry<>(hash, key, value, e); // HashMap的size加1 size++;} |
7. resize()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | /** * Rehashes the contents of this map into a new array with a * larger capacity. This method is called automatically when the * number of keys in this map reaches its threshold. * * If current capacity is MAXIMUM_CAPACITY, this method does not * resize the map, but sets threshold to Integer.MAX_VALUE. * This has the effect of preventing future calls. * * @param newCapacity the new capacity, MUST be a power of two; * must be greater than current capacity unless current * capacity is MAXIMUM_CAPACITY (in which case value * is irrelevant). */void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; // 如果HashMap中table的长度(这里是指table数组的长度,不是链表的长度) // 已经达到了MAXIMUN_CAPACITY = 1 << 30,直接将阈值threshold设置为Integer的最大值。 // 不在扩容HashMap if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } // newCapacity是原table数组长度的2倍 Entry[] newTable = new Entry[newCapacity]; // 将原table中的值迁移到扩容后的newTable中 transfer(newTable, initHashSeedAsNeeded(newCapacity)); // 更新table和阈值threshold table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);} |
8. transfer(), 将原HashMap中的元素迁移到扩容后的HashMap中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | /** * Transfers all entries from current table to newTable. */void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; // 遍历table数组 for (Entry<K,V> e : table) { // 这里e是table数组某个链表的第一个元素,后面e会依次指向链表中所有的元素 // 如果table数组的元素不为null while(null != e) { Entry<K,V> next = e.next; if (rehash) { // 如果e.key是null,hash值是0 e.hash = null == e.key ? 0 : hash(e.key); } // 获取元素e在新table中的索引值 int i = indexFor(e.hash, newCapacity); // 将e的next指向新table的第一个元素(这里还是要记住,插入链表是从头部插入的) // newTable[i]是链表的第一个元素 e.next = newTable[i]; // 将e赋值给链表的第一个元素newTable[i],这样e就取代了链表原来的第一个元素,作为链表新的第一个元素,引领链表! newTable[i] = e; e = next; } }} |
了解了上述n个方法之后,是时候看一下HashMap的put()方法的真面目了!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | /** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */public V put(K key, V value) { // 如果table是空的,需要初始化table if (table == EMPTY_TABLE) { inflateTable(threshold); } // 如果key是null,调用putForNullKey方法插入元素 if (key == null) return putForNullKey(value); // 求key的hash值 int hash = hash(key); // 根据key的hash值和table的长度求元素在table中的索引 int i = indexFor(hash, table.length); // 遍历table[i]引领的链表 // 如果已经存在了相同的key,则更新value并返回old value,否则插入新元素 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; // key已经存在,更新value,返回old value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // HashMap的修改次数加1,modCount是modified times modCount++; // 插入新元素 addEntry(hash, key, value, i); // 如果key没有重复,返回值是null return null;} |
其次,看一下get()方法,再了解get()方法之前,同样先了解几个get()方法会调用的几个辅助方法:
1. getForNullKey()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | /** * Offloaded version of get() to look up null keys. Null keys map * to index 0. This null case is split out into separate methods * for the sake of performance in the two most commonly used * operations (get and put), but incorporated with conditionals in * others. */private V getForNullKey() { if (size == 0) { return null; } for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null;} |
2. getEntry()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | /** * Returns the entry associated with the specified key in the * HashMap. Returns null if the HashMap contains no mapping * for the key. */final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null;} |
了解了上述2个方法之后,get()方法就比较简单了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | /** * Returns the value to which the specified key is mapped, * or {@code null} if this map contains no mapping for the key. * * <p>More formally, if this map contains a mapping from a key * {@code k} to a value {@code v} such that {@code (key==null ? k==null : * key.equals(k))}, then this method returns {@code v}; otherwise * it returns {@code null}. (There can be at most one such mapping.) * * <p>A return value of {@code null} does not <i>necessarily</i> * indicate that the map contains no mapping for the key; it's also * possible that the map explicitly maps the key to {@code null}. * The {@link #containsKey containsKey} operation may be used to * distinguish these two cases. * * @see #put(Object, Object) */public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue();} |
最后,再学习一下remove()方法的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | /** * Removes the mapping for the specified key from this map if present. * * @param key key whose mapping is to be removed from the map * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */public V remove(Object key) { Entry<K,V> e = removeEntryForKey(key); return (e == null ? null : e.value);}/** * Removes and returns the entry associated with the specified key * in the HashMap. Returns null if the HashMap contains no mapping * for this key. */final Entry<K,V> removeEntryForKey(Object key) { if (size == 0) { return null; } // 找到hash值 int hash = (key == null) ? 0 : hash(key); // 求索引位置 int i = indexFor(hash, table.length); Entry<K,V> prev = table[i]; Entry<K,V> e = prev; while (e != null) { Entry<K,V> next = e.next; Object k; // 寻找到key的位置,是当前的e if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { // HashMap的修改次数加1 modCount++; // HashMap的size减1 size--; // 如果是链表的第一个元素,next是null,直接将table[i]设置为null if (prev == e) table[i] = next; else // prev的next是e,next是e.next,即[prev]-> [e] -> [next] // prev.next = next,即[prev] -> [next],直接将元素e移除掉了 prev.next = next; e.recordRemoval(this); return e; } prev = e; e = next; } return e;} |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决