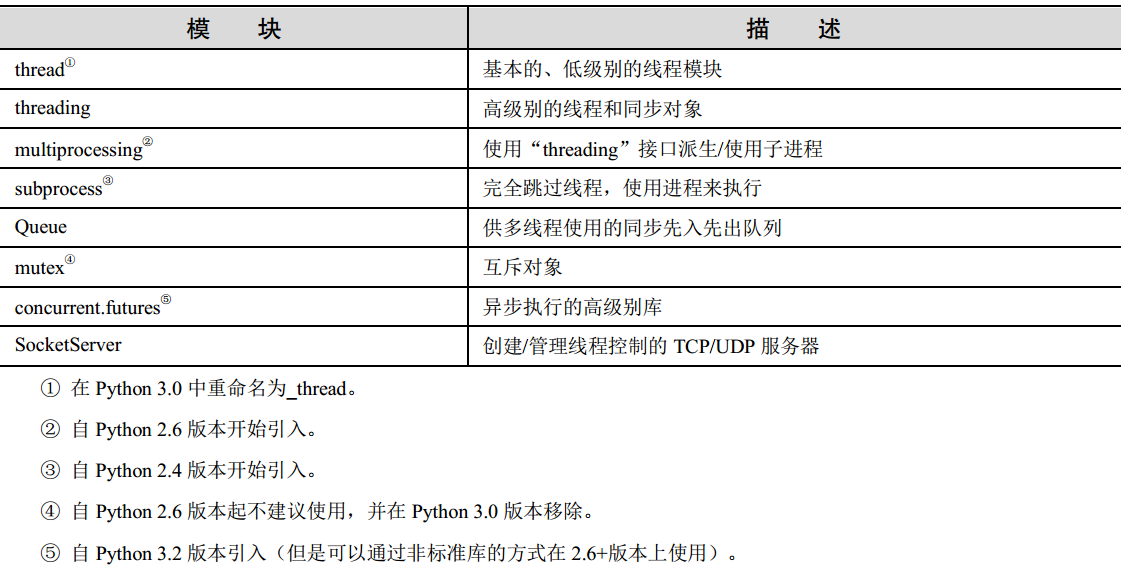
在python中又有多种多线程的方式,但是其中某些由于过于古老以及某些操作不易实现,所以大多已经淘汰(例如thread模块),现在多使用threading模块,其中的Thread类基本完全取代thread模块,而且更方便。
在此,我记录一下我看这个模块时候迷惑的一点
创建多线程有三个方式:
1.创建Thread的实例,传给它一个函数。
2.创建Thread的实例,传给它一个可调用的类实例。
3.创建Thread的子类,并创建子类的实例。
注意:这一点可理解为既然你创建了一个线程,那么必然是用来执行某些东西的,所以你必须制定一个需要执行的代码,比如一个函数,一个可调用的类,当然你也可以创建一些值,那瞬间就完成了,使用额外的线程是为了什么呢?也就是说你肯定需要一个耗费时间的操作才会用多线程。这样就可以理解上述三个方式了。
以第三种方式,贴一段代码来进行具体标记:
1 import threading 2 from time import sleep, ctime 3 4 loops = [4, 2] 5 6 class MyThread(threading.Thread): 7 def __init__(self, func, args, name=''): 8 threading.Thread.__init__(self, name=name) 9 self.func = func 10 self.args = args 11 12 def run(self): 13 self.func(*self.args) 14 15 def loop(nloop, nsec): 16 print 'start loop', nloop, 'at:', ctime() 17 sleep(nsec) 18 print 'loop', nloop, 'done at:', ctime() 19 20 def main(): 21 print 'starting at:', ctime() 22 threads = [] 23 nloops = range(len(loops)) 24 25 for i in nloops: 26 t = MyThread(loop, (i, loops[i]), 27 loop.__name__) 28 threads.append(t) 29 30 for i in nloops: 31 threads[i].start() 32 33 for i in nloops: 34 threads[i].join() 35 36 print 'all DONE at:', ctime() 37 38 if __name__ == '__main__': 39 main()
这里需要特别注意的是第8行:主动调用了基类的初始化函数,不太理解为什么,重写了,应该就直接用自己的就行了。希望大神指教。
还有就是26行,这个子类的实例化,传入的参数,第一个是一个函数,第二个是这个函数的参数,第三个是这个函数的名字。
不过第12行不清楚为什么,也不清楚run这个函数的用途,之后理解了在补充吧。
按照上边的步骤就是多线程的简单运用。
本来我不是很理解join()函数的作用,但是通过输出我发现了一点猫腻。
1 $ mtsleepD.py 2 starting at: Sun Aug 13 18:49:17 2006 3 start loop 0 at: Sun Aug 13 18:49:17 2006 4 start loop 1 at: Sun Aug 13 18:49:17 2006 5 loop 1 done at: Sun Aug 13 18:49:19 2006 6 loop 0 done at: Sun Aug 13 18:49:21 2006 7 all DONE at: Sun Aug 13 18:49:21 2006
根据上边输出可以看出来,按照代码中的执行顺序,loop 0先开始,然后loop 1再开始。
但是第5行可以看出来,是loop 1先执行完毕的。
所以 join的作用是:
A 线程正在运行,当B线程进行Join操作后,A线程会被阻断,进入等待队列。
B线程执行,当B线程执行完毕后,B线程的资源收回,A线程进去执行队列。
A线程继续进行执行
然而对于多线程来说,遇到的最大的问题就是在遇到I\O密集的应用时,怎么在使用多线程的同时避免数据的不同步,此时就需要使用通常意义上的所说的锁了,当然还有信息量。
1 from atexit import register 2 from random import randrange 3 from threading import Thread, Lock, currentThread 4 from time import sleep, ctime 5 6 class CleanOutputSet(set): 7 def __str__(self): 8 return ', '.join(x for x in self) 9 10 lock = Lock() 11 loops = (randrange(2, 5) for x in range(randrange(3, 7))) 12 remaining = CleanOutputSet() 13 14 def loop(nsec): 15 myname = currentThread().name 16 lock.acquire() 17 remaining.add(myname) 18 print('[%s] Started %s' % (ctime(), myname)) #print '[{0}] Started {1}'.format(ctime(), myname) 19 lock.release() 20 sleep(nsec) 21 lock.acquire() 22 remaining.remove(myname) 23 print('[%s] Completed %s (%d secs)' % ( #print '[{0}] Completed {1} ({2} secs)'.format( 24 ctime(), myname, nsec)) 25 print(' (remaining: %s)' % (remaining or 'NONE')) #print ' (remaining: {0})'.format(remaining or 'NONE') 26 lock.release() 27 28 def _main(): 29 for pause in loops: 30 Thread(target=loop, args=(pause,)).start() 31 32 @register 33 def _atexit(): 34 print('all DONE at:', ctime()) 35 36 if __name__ == '__main__': 37 _main()
以上就是一个使用锁的例子,使用acquire来获取锁,使用release释放,
如若使用with会更加简洁,如下。
1 with lock: 2 remaining.add(myname) 3 print '[%s] Started %s' % (ctime(), myname) 4 sleep(nsec)
关于信息量的就不多说了,其实就是请求一个事先设定好大小的资源池,每次需要新的线程就从池子调用,池子空了就无法再调用新的。
接下来是一些多线程的其他模块,需要的话可以详细查询。