模型参数
learning_rate = 0.1
n_hidden1 = 128
n_hidden2 = 64
m_epoch = 20
batch_size = 10
训练结果 - 正确率0.9783
Loading...
Training...
0 0 2.4512374028640203
0 1000 0.3523420662430644
0 2000 0.2951992486559909
0 3000 0.2921797413393495
0 4000 0.2718519581397953
0 5000 0.20941061218754312
1 0 0.19957017176019134
1 1000 0.1701977965699668
1 2000 0.15959998353151617
1 3000 0.16521658617884796
1 4000 0.13251758951489062
1 5000 0.12783543478420317
2 0 0.11807694490728605
2 1000 0.11364847773737928
2 2000 0.09646916985079872
2 3000 0.09829330746266907
2 4000 0.08991702974370368
2 5000 0.09511957104690064
3 0 0.09144713371569846
3 1000 0.07816726513851135
3 2000 0.07279796011456377
3 3000 0.10147599281703368
3 4000 0.08598789688391016
3 5000 0.06259539750678009
4 0 0.0737063287095471
4 1000 0.06877109859880824
4 2000 0.06345762278994854
4 3000 0.06673867742571522
4 4000 0.056332597171151993
4 5000 0.052102161775993396
5 0 0.05241276316658647
5 1000 0.049940757555700224
5 2000 0.04660174203137993
5 3000 0.04600522285923716
5 4000 0.04515805692165451
5 5000 0.043794792861919146
6 0 0.04960128730587637
6 1000 0.041166317121063445
6 2000 0.037670015914850294
6 3000 0.04614758771152878
6 4000 0.03547435967607092
6 5000 0.03665898237042097
7 0 0.03590656211194392
7 1000 0.03167594147419529
7 2000 0.04053674727585003
7 3000 0.03875946815733532
7 4000 0.029905413603525995
7 5000 0.029413784470535158
8 0 0.028722224250346345
8 1000 0.0255732222556901
8 2000 0.024178042055923665
8 3000 0.028281596163049216
8 4000 0.027914037545845843
8 5000 0.02620482743503643
9 0 0.023698146711723565
9 1000 0.02022187928004078
9 2000 0.02191853213819164
9 3000 0.01987554626110066
9 4000 0.020067627133654915
9 5000 0.018546158716080192
10 0 0.018020673914927787
10 1000 0.025930647546901973
10 2000 0.018311323367114295
10 3000 0.019286327233551795
10 4000 0.016017926893763256
10 5000 0.015549588705963695
11 0 0.01597130392279524
11 1000 0.01359353670862956
11 2000 0.013395375304967112
11 3000 0.014414924375070404
11 4000 0.014288767378328595
11 5000 0.012229366028481273
12 0 0.014129329271800458
12 1000 0.010273304609820367
12 2000 0.010349231563611174
12 3000 0.009499036617614389
12 4000 0.016930307516367486
12 5000 0.00974583700802342
13 0 0.010257832675385254
13 1000 0.007572288765073877
13 2000 0.010304323164066306
13 3000 0.007659760423347699
13 4000 0.008679655990689455
13 5000 0.007913942051778021
14 0 0.00629368732297238
14 1000 0.007621704057370862
14 2000 0.00563209083341554
14 3000 0.005780494334621887
14 4000 0.005633900821292181
14 5000 0.006024750531139538
15 0 0.006375587297837822
15 1000 0.0048273790870907995
15 2000 0.008694035821365876
15 3000 0.0048753414814022775
15 4000 0.004879194819355479
15 5000 0.004552447839427736
16 0 0.004061189886835111
16 1000 0.0035647326097741254
16 2000 0.004086689344386508
16 3000 0.004694634683592707
16 4000 0.003287227960025371
16 5000 0.0029598630929137475
17 0 0.004360109718152749
17 1000 0.002524475993802818
17 2000 0.0026327503067552775
17 3000 0.0034415311350398546
17 4000 0.002506391224885838
17 5000 0.002605375321778482
18 0 0.0022980100164080247
18 1000 0.002128729979440177
18 2000 0.0024133806171939562
18 3000 0.0020483187984543516
18 4000 0.0019956668894222165
18 5000 0.0022738639443220508
19 0 0.0019166948196978843
19 1000 0.0018187362640132512
19 2000 0.0017265506052915101
19 3000 0.0016271269341496652
19 4000 0.0016184153738066389
19 5000 0.0018598485830629847
Testing...
rate=9783 / 10000 = 0.9783
Loss下降曲线
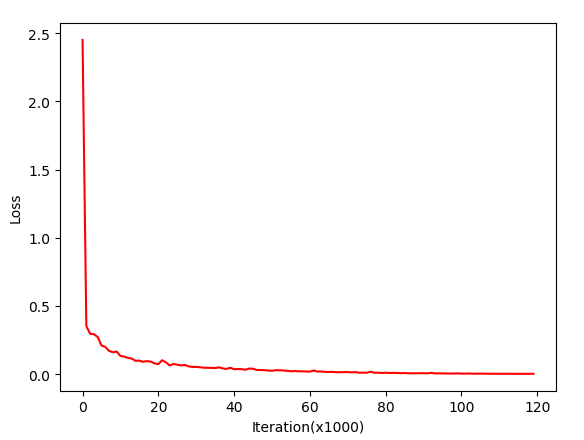
其他思考
调参过程中发现在相同epoch(20)和其他参数均相同的情况下,增加隐藏层结点数正确率略有提高,但结点数足够多后差异不大。
| hidden1 |
hidden2 |
accuracy |
| 128 |
64 |
0.9783 |
| 64 |
32 |
0.9764 |
| 32 |
16 |
0.9694 |
- 说明对此问题64,32的网络表达能力就已较充足,只需要增加epoch、降低learning_rate即可进一步提高正确率
以Hidden1=64,hidden2=32,learning_rate=0.1为例,单独修改epoch,结果如下
| epoch |
accuracy |
| 5 |
0.9726 |
| 10 |
0.9752 |
| 20 |
0.9764 |
| 30 |
0.9777 |
| 40 |
0.9754 |
| 50 |
0.9777 |
- 事实上,epoch足够多后只是training_data拟合程度在提高,测试集正确率并无太大提高
以Hidden1=64,hidden2=32,epoch=20为例,单独修改learning_rate,结果如下
| epoch |
accuracy |
| 0.5 |
0.9669 |
| 0.2 |
0.9751 |
| 0.1 |
0.9764 |
| 0.05 |
0.9751 |
| 0.02 |
0.9737 |
- 正确率出现峰值,与epoch不够多有关(正确率低,收敛得慢),若epoch足够多,正确率越低越靠后的epoch精调能力越强
若在Train中每个epoch减小learning_rate
for epoch in range(max_epoch):
learning_rate = learning_rate * 0.95
- 以Hidden1=64,hidden2=32,epoch=20,初始learning_rate=0.5为例,最终正确率为0.9753,最后一个epoch的learning_rate = 0.17,介于0.2和0.1之间,正确率也介于二者之间
- 以Hidden1=64,hidden2=32,epoch=50,初始learning_rate=0.5为例,最后一个epoch的learning_rate = 0.04,最终正确率为0.9768
- 相比之下,若不改变学习率直接跑50个epoch,最终正确率为0.9724
- 并且loss下降曲线调整learning_rate会全程平滑


