

有规模限制的聚类算法
背景介绍:#
机器学习的聚类算法在很多场景中都有应用,比如用户群体的聚类,地址聚类等。但是,在实际问题中,我们的聚类问题常常是有类的规模限制的,比如我们需要创建几个等大的类,或者有最小类大小的限制等。
Github地址:
https://github.com/jingw2/size_constrained_clustering
PyPI地址:
https://pypi.org/project/size-constrained-clustering/
方法介绍#
- Fuzzy C-means Algorithm: 和KMeans类似,不过利用了归属概率(membership probability)进行计算,而不是直接的0或者1
- Same Size Contrained KMeans Heuristics: 利用启发式的方法获取等大聚类结果
- Same Size Contrained KMeans Inspired by Minimum Cost Flow Problem:将聚类转换为分配问题,并用最小费用流的思路进行求解
- Minimum and Maximum Size Constrained KMeans Inspired by Minimum Cost Flow Problem:将聚类转换为分配问题,并用最小费用流的思路进行求解,加入最小和最大聚类规模限制
- Deterministic Annealling Algorithm: 输入目标每类规模比例,获得相应聚类规模的结果。
- Shrinkage Clustering: base algorithm and minimum size constraints:启发式缩减的方式获得聚类结果。
且支持聚类距离函数定义callback。由于现实问题,我们常常涉及的不是欧氏距离,而是经纬度距离等,因此本轮子支持自定义函数输入。
例子展示
初始化
1 2 3 4 | # setupfrom size_constrained_clustering import fcm, equal, minmax, shrinkage# 默认都是欧式距离计算,可接受其它distance函数,比如haversinefrom sklearn.metrics.pairwise import haversine_distances |
Fuzzy C-means
1 2 3 4 5 6 7 8 9 10 11 | n_samples = 2000n_clusters = 4centers = [(-5, -5), (0, 0), (5, 5), (7, 10)]X, _ = make_blobs(n_samples=n_samples, n_features=2, cluster_std=1.0, centers=centers, shuffle=False, random_state=42)model = fcm.FCM(n_clusters)# 如果使用别的distance function,如haversine distance# model = fcm.FCM(n_clusters, distance_func=haversine_distances)model.fit(X)centers = model.cluster_centers_labels = model.labels_ |
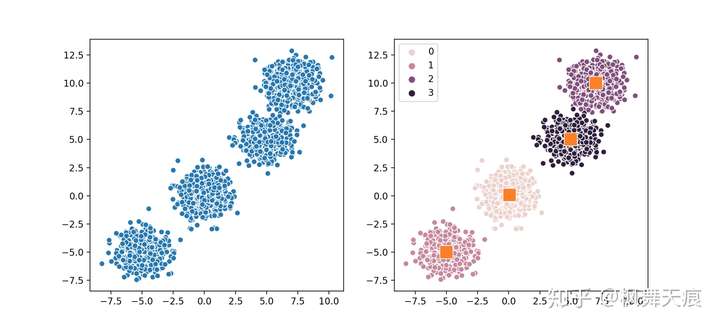
等大聚类
1 2 3 4 5 6 7 8 9 10 | n_samples = 2000n_clusters = 3X = np.random.rand(n_samples, 2)# 使用minmax flow方式求解model = equal.SameSizeKMeansMinCostFlow(n_clusters)# 使用heuristics方法求解model = equal.SameSizeKMeansHeuristics(n_clusters)model.fit(X)centers = model.cluster_centers_labels = model.labels_ |
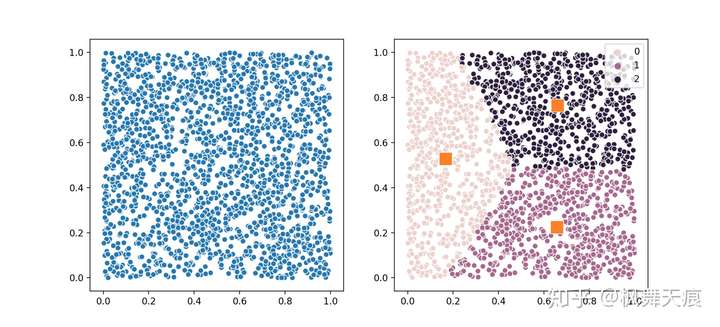
图中共2000个正态分布的点,聚成3类,分别有667,667和666个点。
最小和最大规模限制
1 2 3 4 5 6 7 | n_samples = 2000n_clusters = 3X = np.random.rand(n_samples, 2)model = minmax.MinMaxKMeansMinCostFlow(n_clusters, size_min=400, size_max=800)model.fit(X)centers = model.cluster_centers_labels = model.labels_ |
获取结果聚类size分别为753, 645, 602
Deterministic Annealing
1 2 3 4 5 6 7 8 | n_samples = 2000n_clusters = 3X = np.random.rand(n_samples, 2)# distribution 表明各cluster目标的比例model = da.DeterministicAnnealing(n_clusters, distribution=[0.1, 0.6, 0.3])model.fit(X)centers = model.cluster_centers_labels = model.labels_ |
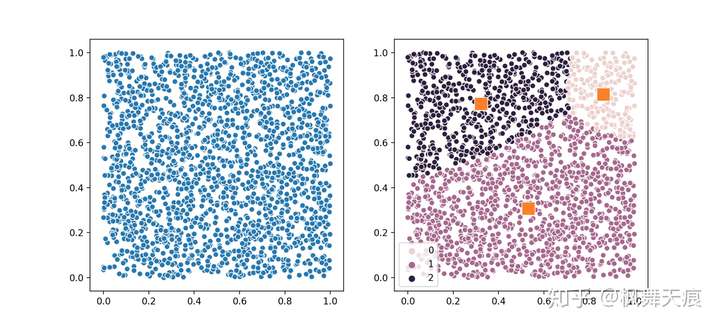
获取的结果cluster size分别为:1200,600和200。对应比例为0.6, 0.3和0.1。
总结:代码可以直接拿过来用,但是由于其中的方法全部分开到其他的地方了,一个方法往往牵连很多个包,所以到现在都没怎么仔细看,其中setup.py是将.pyx文件转换成python解释器可以读取运行的文件,运营到服务器上直接导包,无法将方法带过来,需要在所有的导包之前操作一下
1 2 | import pyximportpyximport.install() |
这个放到代码最上面就ok, 别问我怎么知道的,问就是找了一天的bug, 专业采坑填坑


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端