

随机森林和AdaBoost的区别
一、随机森林#
1.概念:随机森林利用随机的方式将许多决策树组合成一个森林,每个决策树在分类的时候决定测试样本的最终类别
是在Bagging策略的基础上进行修改后的一种算法(Bagging核心思想:采用有放回的采样规则,从m个样本点中抽取n个数据构建一个新的训练数据集,用这个数据集来训练模型,重复上述过程B次,得到B个模型。采用投票或取平均值方式进行预测)
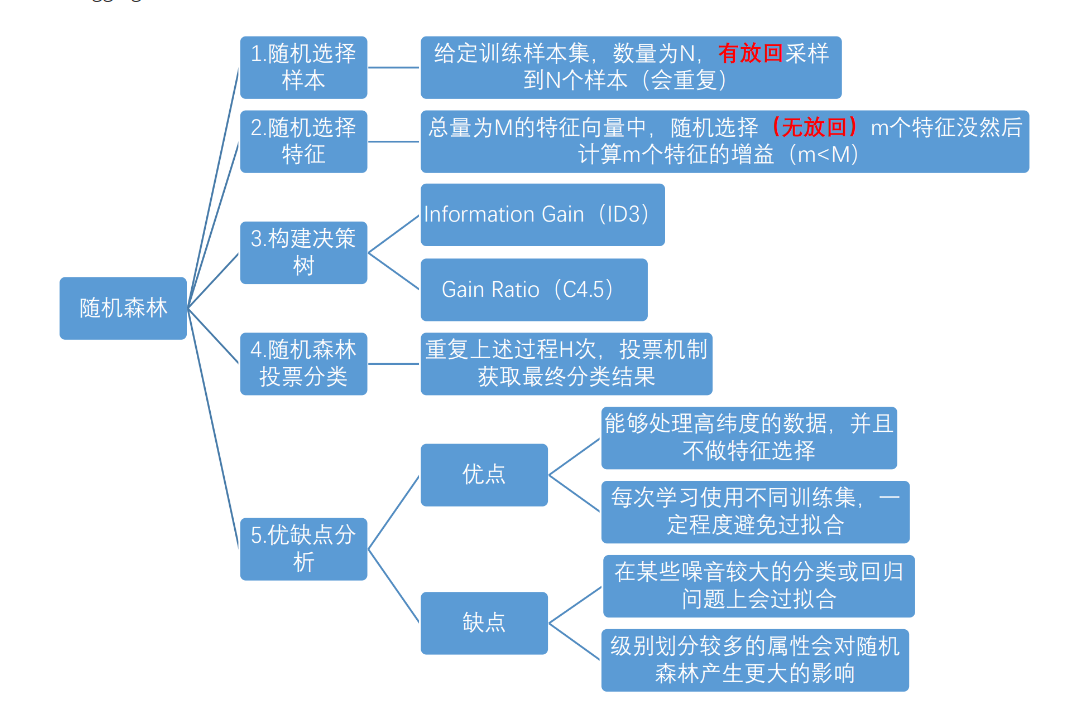
从所有属性中随机选择K个属性,选择出最佳分割属性作为节点创建决策树;
重复以上两步m次,即建立m棵决策树;这m个决策树形成随机森林,通过投票表决结果决定数据属于那一类
RF算法在实际应用中具有比较好的特性,应用也比较广泛,主要应用在:分类、回归、特征转换、异常点检测等。
常见的RF变种算法如下:
Extra Tree
Totally Random Trees Embedding(TRTE)
Isolation Forest
-
训练可以并行化,对于大规模样本的训练具有速度的优势;
-
由于进行随机选择决策树划分特征列表,这样在样本维度比较高的时候,仍然具有比较高的训练性能;
-
给以给出各个特征的重要性列表;
-
由于存在随机抽样,训练出来的模型方差小,泛化能力强;
-
RF实现简单;
-
对于部分特征的缺失不敏感。
RF的主要缺点:
-
在某些噪音比较大的特征上,RF模型容易陷入过拟合;
-
取值比较多的划分特征对RF的决策会产生更大的影响,从而有可能影响模型的效果
二、AdaBoost算法#
提升方法:通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的精度。
#
“关注”被错分的样本,“器重”性能好的弱分类器实现:
-
不同的训练集:调整样本权重
-
“关注”:增加错分样本权重
-
“器重”:好的分类器权重大
-
样本权重间接影响分类器权重:样本权重-分类器-性能(错误率)-分类器的权重
2.两个基本问题:#
1)每一轮如何改变训练样本的权重
2)如何将弱分类器组合成一个强分类器
Adaboost的做法:
1)提高那些被前一轮弱分类错误分类样本的权值,而降低那些被正确分类样本的权值
2)加权多数表决,加大分类误差小的弱分类器权重,减小分类误差大的弱分类器权重
#
-
假设训练数据集
-
初始化训练数据权重分布
-
使用具有权值分布Dm的训练数据集学习,得到基本分类器
-
计算Gm(x)在训练集上的分类误差
-
计算Gm(x)模型的权重系数αm
-
权重训练数据集的权值分布
-
权重归一化
-
构建基本分类器的线性组合
#
Adaboost 算法优缺点
优点:
1)Adaboost 是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,Adaboost 算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的,而弱分类器构造极其简单
4)简单,不用做特征筛选
5)可以处理连续值和离散值
6)解释强,结构简单
缺点:
对异常样本敏感,异常样本可能会在迭代过程中获得较高的权重值,最终影响模型效果。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端