
大数据开发相关技术汇总

Hadoop
Yarn(分布式资源管理器)
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的
Hbase
HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
Kaflka
一种分布式的,基于发布 / 订阅的消息系统。[详细介绍](https://zhuanlan.zhihu.com/p/74063251)
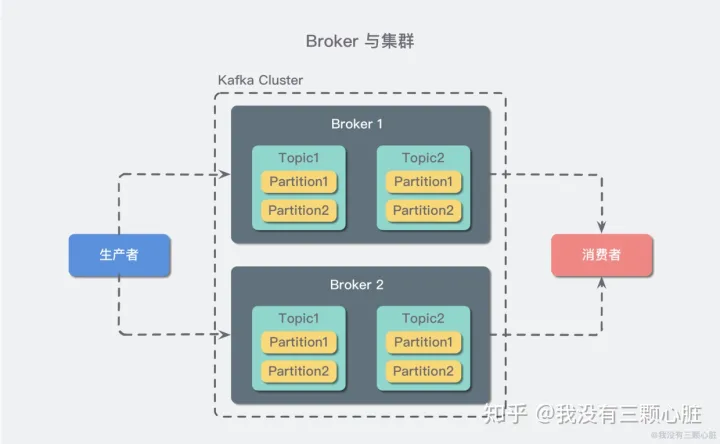
- 设计目标:
- 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条以上消息的传输。
- 支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
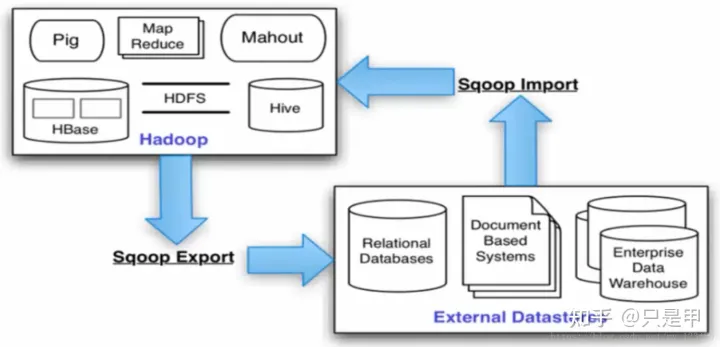
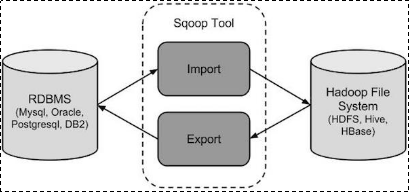
Sqoop
Hadoop数据导入,导出工具。自动生成mapreduce。详细介绍
- 导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
- 导出数据:从Hadoop的文件系统中导出数据到关系数据库;
- 特点:
- 可以将关系型数据库中的数据导入hdfs、hive或者hbase等hadoop组件中,也可将hadoop组件中的数据导入到关系型数据库中;
- sqoop在导入导出数据时,充分采用了map-reduce计算框架,根据输入条件生成一个map-reduce作业,在hadoop集群中运行。采用map-reduce框架同时在多个节点进行import或者export操作,速度比单节点运行多个并行导入导出效率高,同时提供了良好的并发性和容错性;
- 支持insert、update模式,可以选择参数,若内容存在就更新,若不存在就插入;
- 对国外的主流关系型数据库支持性更好。
spark
Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算
Flink
flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力
Dysnc
Mahout
Flink
为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架
ZooKeeper
Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户
每天成就一小步,积累下来就是一大步。
转发本文请注明出处,谢谢您的阅读与分享!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号