回归分析06:回归参数的估计(4)
Chapter 6:回归参数的估计(4)
3.8 岭估计
3.8.1 岭估计的定义和性质
当自变量之间具有多重共线性时,岭估计是一种为了克服最小二乘估计的方差较大的问题而提出的改进的最小二乘估计方法。
岭估计的主要思想为:多重共线性下的设计矩阵 \(X\) 是病态的,即 \(\left|X'X\right|\approx0\) ,从而使得 \(\left(X'X\right)^{-1}\) 接近奇异。为避免这一现象,给 \(X'X\) 加上一个正常数对角矩阵 \(kI\ (k>0)\) ,使得矩阵 \(\left(X'X+kI\right)^{-1}\) 接近奇异的可能性要比 \(\left(X'X\right)^{-1}\) 接近奇异的可能性小得多。因此用
作为未知参数 \(\beta\) 的估计,可以得到比最小二乘估计 \(\hat\beta\) 更加稳定的估计。
岭估计:对给定的 \(k>0\) ,称 \(\hat\beta(k)=\left(X'X+kI\right)^{-1}X'Y\) 为回归系数 \(\beta\) 的岭估计。由岭估计所建立的回归方程称为岭回归方程,称 \(k\) 为岭参数。对于 \(\hat\beta(k)\) 的分量 \(\hat\beta_j(k)\) ,把在平面直角坐标系中 \(\hat\beta_j(k)\) 关于 \(k\) 的变化所表现出来的曲线称为岭迹。
- 岭估计 \(\hat\beta(k)\) 是一个关于 \(k\) 的估计类。当 \(k=0\) 时,\(\hat\beta(k)\) 就是通常的最小二乘估计。
- 在进行岭估计之前,需要消除量纲的影响,故假设自变量与因变量均已标准化,故这里的所讨论的设计矩阵 \(X\) 均是 \(n\times p\) 的矩阵。
性质 1:岭估计 \(\hat\beta(k)\) 是 \(\beta\) 的有偏估计,即对 \(\forall k>0\) ,\({\rm E}\left[\hat\beta(k)\right]\neq\beta\) 。
当自变量之间存在多重共线性时,最小二乘估计虽然保持偏差部分为 \(0\) ,但它的方差部分却很大,最终导致它的均方误差很大。岭估计的引入就是一种牺牲无偏性,换取方差的大幅度减少,从而降低均方误差的方法。
性质 2:岭估计 \(\hat\beta(k)\) 是最小二乘估计 \(\hat\beta\) 的一个线性变换。
只需注意到
\[\begin{aligned} \hat\beta(k)&=\left(X'X+kI\right)^{-1}X'Y \\ \\ &=\left(X'X+kI\right)^{-1}X'X\left(X'X\right)^{-1}XY \\ \\ &=\left(X'X+kI\right)^{-1}X'X\hat\beta \ . \end{aligned} \]
性质 3:对任意的 \(k>0\) ,若 \(\left\|\hat\beta\right\|\neq0\) ,则总有 \(\left\|\hat\beta(k)\right\|<\left\|\hat\beta\right\|\) 。即岭估计是把最小二乘估计 \(\hat\beta\) 向原点作适度的压缩而得到的,岭估计是一个压缩的有偏估计。
考虑多元线性回归模型 \(Y=X\beta+e\) ,令
\[Z=XP \ , \quad \alpha=P'\beta \ , \]其中 \(P\) 为正交矩阵,满足
\[P'X'XP=\Lambda={\rm diag}\left(\lambda_1,\lambda_2,\cdots,\lambda_p\right) \ , \]这里 \(\lambda_1,\lambda_2,\cdots,\lambda_p>0\) 为 \(X'X\) 的特征根。将多元线性回归模型写为
\[Y=Z\alpha+e \ , \quad {\rm E}(e)=0 \ , \quad {\rm Cov}(e)=\sigma^2I_n \ . \]我们将上述模型称为线性回归模型的典则形式,称 \(\alpha\) 为典则回归系数。
注意到 \(Z'Z=P'X'XP=\Lambda\) ,所以
\[\hat\alpha=\left(Z'Z\right)^{-1}Z'Y=\Lambda^{-1}Z'Y \ . \]而又因为
\[\hat\beta=\left(X'X\right)^{-1}X'Y=P\Lambda^{-1}P'X'Y=P\Lambda^{-1}Z'Y=P\hat\alpha \ . \]它们相应的岭估计为
\[\begin{aligned} \hat\alpha(k)&=\left(Z'Z+kI\right)^{-1}Z'Y=\left(\Lambda+kI\right)^{-1}Z'Y \ . \\ \\ \hat\beta(k)&=\left(X'X+kI\right)^{-1}X'Y \\ \\ &=PP'\left(X'X+kI\right)^{-1}PP'X'Y \\ \\ &=P\hat\alpha(k) \ . \end{aligned} \]因此有
\[\left\|\hat\beta(k)\right\|=\left\|\hat\alpha(k)\right\|=\left\|\left(\Lambda+kI\right)^{-1}\Lambda\hat\alpha\right\|<\left\|\hat\alpha\right\|=\left\|\hat\beta\right\| \ . \]容易证明,典则回归系数的最小二乘估计(或岭估计)和原回归系数的最小二乘估计(或岭估计)具有相同的均方误差:
\[{\rm MSE}(\hat\alpha)={\rm MSE}(\hat\beta) \ , \quad {\rm MSE}(\hat\alpha(k))={\rm MSE}(\hat\beta(k)) \ . \]
定理 3.8.1 (岭估计存在定理):存在 \(k>0\) ,使得在均方误差意义下,岭估计优于最小二乘估计,即
由岭估计的性质 3 可知,只需证存在 \(k>0\) ,使得
\[{\rm MSE}(\hat\alpha(k))<{\rm MSE}(\hat\alpha) \ . \]记 \(f(k)={\rm MSE}(\hat\alpha(k)),\,k\geq0\) 。注意 \(f(0)={\rm MSE}(\hat\alpha)\) 。只需证明 \(f(k)\) 在 \([0,\infty)\) 上是连续函数且 \(f'(0)<0\) ,则必存在一个较小的 \(k>0\) 使得上述不等式成立。
注意到
\[\begin{aligned} {\rm E}\left[\hat\alpha(k)\right]&=\left(\Lambda+kI\right)^{-1}Z'{\rm E}(Y) \\ \\ &=\left(\Lambda+kI\right)^{-1}Z'Z\alpha \\ \\ &=\left(\Lambda+kI\right)^{-1}\Lambda\alpha \ , \\ \\ {\rm Cov}\left[\hat\alpha(k)\right]&=\sigma^2\left(\Lambda+kI\right)^{-1}Z'Z\left(\Lambda+kI\right)^{-1} \\ \\ &=\sigma^2\left(\Lambda+kI\right)^{-1}\Lambda\left(\Lambda+kI\right)^{-1} \ . \end{aligned} \]所以
\[\begin{aligned} f(k)&={\rm MSE}(\hat\alpha(k))={\rm tr}\left[{\rm Cov}\left[\hat\alpha(k)\right]\right]+\left\|{\rm E}\left[\hat\alpha(k)\right]-\alpha\right\|^2 \\ \\ &=\sigma^2\sum_{j=1}^p\frac{\lambda_j}{\left(\lambda_j+k\right)^2}+k^2\sum_{j=1}^p\frac{\alpha_j^2}{\left(\lambda_j+k\right)^2} \\ \\ &\xlongequal{def}f_1(k)+f_2(k) \ . \end{aligned} \]显然 \(f(k)\) 是 \([0,\infty)\) 上的连续函数,又因为
\[f_1'(k)=-2\sigma^2\sum_{j=1}^p\frac{\lambda_j}{\left(\lambda_j+k\right)^3} \ , \quad f_1'(0)=-2\sigma^2\sum_{j=1}^p\frac{1}{\lambda_j^2}<0 \ , \]以及
\[f_2'(k)=2k\sum_{j=1}^p\frac{\lambda_j\alpha_j^2}{\left(\lambda_j+k\right)^3} \ , \quad f_2'(0)=0 \ , \]所以
\[f'(0)=f_1'(0)+f_2'(0)=-2\sigma^2\sum_{j=1}^p\frac{1}{\lambda_j^2}<0 \ . \]
岭估计的存在性定理从理论上证明了存在某个岭估计优于最小二乘估计,但要找出这个岭参数 \(k\) 是不容易的。这个解依赖于未知参数 \(\alpha_i,\,i=1,2,\cdots,p\) 和 \(\sigma^2\) ,所以不可能从解方程的角度获得。因此,我们需要提出从其他途径选择岭参数 \(k\) 的方法。
3.8.2 岭参数的选择方法
(1) Hoerl-Kennard 公式
Hoerl 和 Kennard 提出的选择岭参数 \(k\) 的公式为
注意到,理论上的最优岭参数是下列方程的解:令 \(f'(k)=0\) ,则有
若 \(k\alpha_i^2-\sigma^2<0\) 对 \(i=1,2,\cdots,p\) 都成立,则 \(f'(k)<0\) ,于是取
当 \(0<k<k^*\) 时,\(f'(k)<0\) 恒成立,因而 \(f(k)\) 在 \((0,k^*)\) 上是单调递减函数。再由 \(f(k)\) 是 \((0,k^*)\) 上的连续函数得到 \(f(k^*)<f(0)\) 。用 \(\hat\alpha_i\) 和 \(\hat\sigma^2\) 代替 \(\alpha_i\) 和 \(\sigma^2\) 即可得到我们需要的岭参数 \(\hat k\) 。
(2) 岭迹法
将 \(\hat\beta_1(k),\hat\beta_2(k),\cdots,\hat\beta_p(k)\) 的岭迹画在一张图上,根据岭迹的变化趋势选择岭参数 \(k\) 。以下是几条选择岭参数 \(k\) 的准则:
- 各回归系数的岭估计大致趋于稳定;
- 用最小二乘估计时符号不合理的回归系数,其岭估计的符号变得合理;
- 残差平方和不要上升太多;
一般情况下,我们选择使得各条岭迹均开始趋于稳定的最小的 \(k\) 值。
3.8.3 岭估计的几何意义
前面已经证明,岭估计 \(\hat\beta(k)\) 是最小二乘估计 \(\hat\beta\) 的一种压缩。如果我们已经有了 \(\hat\beta\) ,希望将它的长度压缩到原来的 \(c\) 倍 \((0<c<1)\) ,并使残差平方和上升尽可能小,可以证明,这样的估计就是岭估计。
设 \(b\) 为 \(\beta\) 的任意估计,对应的残差平方和为
\[\begin{aligned} {\rm RSS}(b)&=\left\|Y-Xb\right\|^2 \\ \\ &=\left\|Y-X\hat\beta+X(\hat\beta-b)\right\|^2 \\ \\ &=\left\|Y-X\hat\beta\right\|^2+(\hat\beta-b)'X'X(\hat\beta-b) \ . \end{aligned} \]所以,将 \(\hat\beta\) 的长度压缩到原来的 \(c\) 倍,且使残差平方和上升最小,等价于求解下列极值问题:
\[\begin{aligned} \min_b \quad &(b-\hat\beta)'X'X(b-\hat\beta) \ , \\ {\rm s.t.}\quad & \|b\|^2=\left\|c\hat\beta\right\|^2 \ . \end{aligned} \]设 \(P\) 为正交矩阵,满足
\[P'X'XP=\Lambda={\rm diag}\left(\lambda_1,\lambda_2,\cdots,\lambda_p\right) \ , \]其中 \(\lambda_1,\lambda_2,\cdots,\lambda_p>0\) 为 \(X'X\) 的特征根。记
\[\alpha=P'\beta \ , \quad d=P'b \ , \quad \hat\alpha=P'\hat\beta \ . \]显然上述极值问题等价于
\[\begin{aligned} \min_d \quad &(d-\hat\alpha)'\Lambda(d-\hat\alpha) \ , \\ {\rm s.t.}\quad & \|d\|^2=\left\|c\hat\alpha\right\|^2 \ . \end{aligned} \]用 Lagrange 乘子法,构造辅助函数
\[F(d,k)=(d-\hat\alpha)'\Lambda(d-\hat\alpha)+k\left(d'd-c^2\left\|\hat\alpha\right\|^2\right) \ , \]其中 \(k\ (k\neq0)\) 为 Lagrange 乘子。对上式关于 \(d\) 求导,并令其等于 \(0\) ,则有
\[\frac{\partial F(d,k)}{\partial d}=2(\Lambda+kI)d-2\Lambda\hat\alpha=0 \ . \]解得
\[d=(\Lambda+kI)^{-1}\Lambda\hat\alpha \ , \quad \Longrightarrow \quad b=\left(X'X+kI\right)^{-1}X'Y \ . \]下面只需证 \(k>0\) 。将 \(d\) 的解析表达式代入目标函数中,记为 \(Q(k)\) ,于是
\[\begin{aligned} Q(k)&=(d-\hat\alpha)'\Lambda(d-\hat\alpha) \\ \\ &=\hat\alpha'\left[\left((\Lambda+kI)^{-1}\Lambda-I\right)'\Lambda\left((\Lambda+kI)^{-1}\Lambda-I\right)\right]\hat\alpha \\ \\ &=k^2\hat\alpha'{\rm diag}\left(\frac{\lambda_1}{\left(\lambda_1+k\right)^2},\frac{\lambda_2}{\left(\lambda_2+k\right)^2},\cdots,\frac{\lambda_p}{\left(\lambda_p+k\right)^2}\right)\hat\alpha \\ \\ &=k^2\sum_{i=1}^p\frac{\lambda_i\hat\alpha_i^2}{\left(\lambda_i+k\right)^2} \ . \end{aligned} \]由于 \(\lambda_1,\lambda_2,\cdots,\lambda_p>0\) ,所以对 \(k>0\) ,都有 \(\left(\lambda_i+k\right)^2>(\lambda_i-k)^2\) ,所以 \(Q(k)<Q(-k)\) 。这说明 \(Q(k)\) 的极小值不会在 \((-\infty,0)\) 上取到,所以该极值问题取到极值点时,一定有 \(k>0\) 。
从几何上说,约束条件 \(\|b\|^2=\left\|c\hat\beta\right\|^2\xlongequal{def}h^2\) 是一个中心在原点,半径为 \(h\) 的球面。对目标函数作椭球
因为 \(0<c<1\) ,所以 \(\hat\beta\) 在 \(\|b\|^2=\left\|c\hat\beta\right\|^2=h^2\) 的球面之外。故总可以找到 \(\delta>0\) 使得球 \(\|b\|^2=h^2\) 和目标函数的椭球相切于某点 \(\tilde\beta\) 。这个 \(\tilde\beta\) 就是上述极值问题的解,也就是岭估计 \(\hat\beta(k)\) 。
以二维向量为例,该极值问题如下图所示
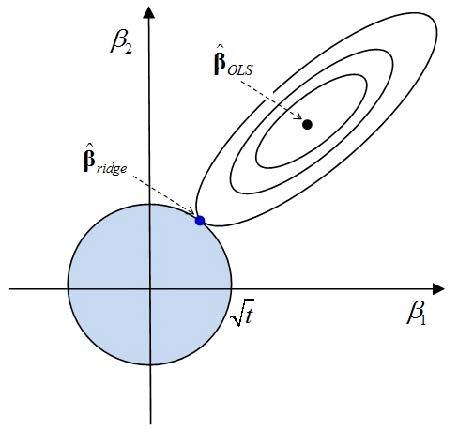
容易看出,该极值问题与如下优化问题等价:
其中 \(\lambda\geq0\) 称为调节参数。在这个优化问题中,\(\|Y-X\beta\|^2\) 称为损失函数,\(\|\beta\|^2\) 称为惩罚函数,参数 \(\lambda\) 用于在损失和惩罚之间控制权衡。
3.9 主成分估计
3.9.1 主成分估计的过程
主成分估计的基本思想:
- 首先借助于正交变换将回归自变量变为对应的主成分,要求主成分的观测向量是正交的,且某些观测向量近似为 \(0\) 向量;
- 从所有的主成分中删去观测向量近似为 \(0\) 的主成分,起到消除多重共线性和降维的双重作用;
- 将保留下来的主成分作为新的回归自变量建立回归模型,用最小二乘估计模型中的回归系数,得到主成分回归方程。
- 基于得到的主成分回归方程,将它们转换为原始变量,即可得到原来的回归方程。
为了消除量纲的影响,假设自变量与因变量均已标准化。考虑回归模型
记 \(\lambda_1\geq\lambda_2\geq\cdots\geq\lambda_p>0\) 为 \(X'X\) 的特征根,\(\phi_1,\phi_2,\cdots,\phi_p\) 为对应的标准正交化特征向量,则有
为 \(p\times p\) 正交矩阵,且有
再记 \(Z=X\Phi,\,\alpha=\Phi'\beta\) ,则线性回归模型可以改写为
主成分的性质:任意两个的主成分的观测向量都是互不相关的,且第 \(j\) 个主成分的偏差平方和
因为 \(Z'Z=\Phi'X'X\Phi=\Lambda={\rm diag}\left(\lambda_1,\lambda_2,\cdots,\lambda_p\right)\) ,所以
\[z_j'z_k=0 \ , \quad \forall j\neq k \ , \]且 \(z_j'z_j=\lambda_j,\,j=1,2,\cdots,p\) 。又因为 \(X\) 是标准化设计矩阵,所以
\[\bar{z}_j=\frac1n\sum_{i=1}^nz_{ij}=\frac1n\sum_{i=1}^n\sum_{k=1}^p\phi_{kj}x_{ik}=\frac{1}{n}\sum_{k=1}^p\phi_{kj}\sum_{i=1}^nx_{ik}=0 \ . \]因此有
\[\sum_{i=1}^n\left(z_{ij}-\bar{z}_j\right)^2=\sum_{i=1}^nz_{ij}^2=z_j'z_j=\lambda_j \ , \quad j=1,2,\cdots,p \ . \]由此可知 \(\lambda_j\) 度量了第 \(j\) 个主成分 \(z_j\) 取值变动的大小。因为 \(\lambda_1\geq\lambda_2\geq\cdots\geq\lambda_p>0\) ,所以我们称 \(z_1\) 为第一主成分,称 \(z_2\) 为第二主成分,以此类推。这 \(p\) 个主成分的观测向量是正交的。
由主成分的性质可知,\(z_1\) 对因变量的解释能力最强,\(z_2\) 次之,\(z_p\) 最弱。若设计矩阵 \(X\) 是病态矩阵,则存在一些 \(X'X\) 的特征根接近于 \(0\) 。
不妨设 \(\lambda_{r+1},\lambda_{r+2},\cdots,\lambda_p\approx0\) ,此时后面的 \(p-r\) 个主成分的取值变动就很小,且均在 \(0\) 附近取值,所以这 \(p-r\) 个主成分对因变量的影响可以忽略,可将它们从回归模型中剔除。
剩下的主成分 \(z_1,z_2,\cdots,z_r\) 就不存在多重共线性问题,用最小二乘法对剩下的 \(r\) 个主成分做回归即可。
我们用分块的方式建立回归方程:对 \(\Lambda,\alpha,Z,\Phi\) 进行分块
其中 \(\Lambda_1\) 为 \(r\times r\) 矩阵,\(\alpha_1\) 为 \(r\times1\) 向量,\(Z_1\) 为 \(n\times r\) 矩阵,\(\Phi_1\) 为 \(p\times r\) 矩阵。因为 \(Z_2\) 近似是 \(0\) 矩阵,所以剔除 \(Z_2\alpha_2\) ,模型可以写为
这里 \(Z_1\) 不是病态矩阵,因为 \(Z_1'Z_1\) 的特征根为 \(\lambda_1,\lambda_2,\cdots,\lambda_r\) 均远离 \(0\) ,所以可直接利用最小二乘法求得 \(\alpha_1\) 的最小二乘估计
前面我们从模型中剔除了后面的 \(p-r\) 个主成分,这相当于我们用 \(\hat\alpha_2=0\) 来估计 \(\alpha_2\) ,利用 \(\beta=\Phi\alpha\) 可以得到 \(\beta\) 的主成分估计为
相应的主成分回归方程为 \(\hat{Y}=X\tilde{\beta}\) 。
3.9.2 主成分估计的性质
上述主成分估计的过程可以概括为以下三步:
- 做正交变换 \(Z=X\Phi\) ,获得新的自变量,称为主成分;
- 做回归自变量选择,提出特征根比较小的主成分;
- 用标准化后的 \(y\) 对剩余的主成分做回归,得到最小二乘估计和主成分回归方程,再将这个回归方程转换为关于原始变量的回归方程。
经过上述过程得到的估计量 \(\tilde\beta\) 称为 \(\beta\) 的主成分估计,下面我们来研究 \(\tilde\beta\) 的统计性质。
性质 1:主成分估计 \(\tilde\beta=\Phi_1\Phi_1'\hat\beta\) 是最小二乘估计的一个线性变换。
根据下列关系
\[\Phi_1'\Phi_1=I_r \ , \quad \Phi_1'\Phi_2=0 \ , \quad X'X=\Phi\Lambda\Phi'=\Phi_1\Lambda_1\Phi_1'+\Phi_2\Lambda_2\Phi_2' \ , \]可以得到
\[\begin{aligned} \tilde\beta&=\Phi_1\Lambda_1^{-1}\Phi_1'X'Y \\ \\ &=\Phi_1\Lambda_1^{-1}\Phi_1'X'X\hat\beta \\ \\ &=\Phi_1\Lambda_1^{-1}\Phi_1'\Phi_1\Lambda_1\Phi_1'\hat\beta+\Phi_1\Lambda_1^{-1}\Phi_1'\Phi_2\Lambda_2\Phi_2'\hat\beta \\ \\ &=\Phi_1\Phi_1'\hat\beta \ . \end{aligned} \]
性质 2:\({\rm E}(\tilde{\beta})=\Phi_1\Phi_1'\beta\) ,即只要 \(r<p\) ,主成分估计就是有偏估计。
性质 3:\(\left\|\tilde\beta\right\|\leq\left\|\hat\beta\right\|\) ,即主成分估计是压缩估计。
构造 \(p\times p\) 矩阵 \(\tilde I={\rm diag}\left(I_r,0\right)\) ,则由 \(\Phi\) 的定义可知
\[\Phi_1\Phi_1'=\Phi\tilde{I}\Phi' \ . \]从而有
\[\left\|\tilde\beta\right\|=\left\|\Phi\tilde{I}\Phi'\hat\beta\right\|=\left\|\Phi\right\|\left\|\tilde{I}\Phi'\hat\beta\right\|=1\times \left\|\tilde{I}\Phi'\hat\beta\right\|\leq \left\|\Phi'\hat\beta\right\|=\left\|\hat\beta\right\| \ . \]
定理 3.9.1:当原始自变量存在足够严重的多重共线性时,适当选择保留的主成分个数可使主成分估计比最小二乘估计拥有较小的均方误差,即
假设 \(X'X\) 的后 \(p-r\) 个特征根 \(\lambda_{r+1},\cdots,\lambda_p\) 很接近于 \(0\) ,不难看出
\[\begin{aligned} {\rm MSE}(\tilde\beta)&={\rm MSE}\begin{pmatrix} \hat\alpha_1 \\ 0 \end{pmatrix} \\ \\ &={\rm tr}\left[{\rm Cov}\begin{pmatrix} \hat\alpha_1 \\ 0 \end{pmatrix} \right]+\left\|{\rm E}\begin{pmatrix} \hat\alpha_1 \\ 0 \end{pmatrix} -\alpha\right\|^2 \\ \\ &=\sigma^2{\rm tr}\left(\Lambda_1^{-1}\right)+\left\|\alpha_2\right\|^2 \ . \end{aligned} \]因为
\[{\rm MSE}(\hat\beta)=\sigma^2{\rm tr}\left(\Lambda^{-1}\right)=\sigma^2{\rm tr}\left(\Lambda_1^{-1}\right)+\sigma^2{\rm tr}\left(\Lambda_2^{-1}\right) \ , \]所以
\[{\rm MSE}(\tilde\beta)={\rm MSE}(\hat\beta)+\left(\left\|\alpha_2\right\|^2-\sigma^2{\rm tr}\left(\Lambda_2^{-1}\right)\right) \ . \]于是
\[{\rm MSE}(\tilde\beta)<{\rm MSE}(\hat\beta) \quad \iff \quad \left\|\alpha_2\right\|^2<\sigma^2{\rm tr}\left(\Lambda_2^{-1}\right)=\sigma^2\sum_{i=r+1}^p\frac{1}{\lambda_i} \ . \]当多重共线性足够严重的时候,\(\lambda_{r+1},\cdots,\lambda_{p}\) 中的某一个可以充分接近于 \(0\) ,因此上式右端可以足够大使得该不等式成立。
因为 \(\alpha_2=\Phi_2'\beta\) ,我们可以将上述不等式写为
这就是说,当 \(\beta\) 和 \(\sigma\) 满足该不等式时,主成分估计才比最小二乘估计拥有较小的均方误差。如果将 \(\beta/\sigma\) 视为参数空间中的一个参数,则上述不等式表示一个中心在原点的椭球,有以下两个结论:
- 对给定的参数 \(\beta\) 和 \(\sigma^2\) ,当 \(X'X\) 的后 \(p-r\) 个特征根比较小时,主成分估计比最小二乘估计拥有较小的均方误差;
- 对给定的\(X'X\) ,即固定的 \(\Lambda_2\) ,对绝对值相对较小的 \(\beta/\sigma\) ,主成分估计比最小二乘估计拥有较小的均方误差。
最后我们给出两条主成分个数 \(r\) 的选取准则:
- 略去特征根接近于 \(0\) 的主成分;
- 选择 \(r\) 使得累计贡献率(前 \(r\) 个特征根之和在 \(p\) 个特征根之和中所占的比例)达到预想给定的值。
根据经验,在实际操作中,我们一般选择最小的 \(r\) 使得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号