计量经济学导论04:多重共线性
Chapter 4:多重共线性
通过前面的三篇笔记,我们基本上搭建了一个计量经济学的分析框架,即模型设定、基本假定、参数估计、统计性质、假设检验。其中,基本假定的满足是保证一切计量分析合理性的前提条件。在这一系列的笔记中,我们都主要参考伍德里奇关于基本假定的表述,可以参考笔记《计量经济学导论02:多元回归模型》中的 MLR.1 至 MLR.6 。从本节开始,我们开始讨论违背基本假定的问题,即如果我们的样本数据没有我们认为的那么理想,我们又该作何处理。
一、多重共线性的含义
我们在经典假定 MLR.3 中曾提出,多元回归模型应满足不存在完全共线性的假设。在实际应用中,共线性问题是多元回归模型可能存在的一类现象,分为完全共线性和多重共线性两种。完全共线性指的指多元回归模型中的一些或全部解释变量之间存在一种确定的线性关系,而多重共线性指的是一些或全部解释变量之间存在一种不完全但高度相关的线性关系。
注意一点,如果模型中出现了完全共线性,则违背了 MLR.3 的假定;如果模型中出现了多重共线性,则不违背任何一条经典假定,只是估计效果没有那么好而已。认清这一点非常重要,对我们分析多重共线性下参数估计的统计性质有很大的帮助。下面我们给出严格的定义。
完全共线性
对于解释变量 \(X_1,X_2,\cdots,X_k\) ,如果存在不全为 \(0\) 的常数 \(\lambda_1,\lambda_2,\cdots,\lambda_k\),使得
在矩阵形式中,有 \({\rm r}(\boldsymbol{X})<k+1\) ,这表明数据矩阵 \(\boldsymbol{X}\) 中至少有一个列向量可以用其余的列向量线性表示,此时解释变量 \(X_1,X_2,\cdots,X_k\) 中存在完全共线性。
多重共线性
对于解释变量 \(X_1,X_2,\cdots,X_k\) ,如果存在不全为 \(0\) 的常数 \(\lambda_1,\lambda_2,\cdots,\lambda_k\),使得
其中,\(v_i\) 是随机误差项,这表明中解释变量 \(X_1,X_2,\cdots,X_k\) 只存在一种近似的线性关系,称为多重共线性。
我们可以用下面的数据举个例子:
| \(X_1\) | \(X_2\) | \(X_3\) |
|---|---|---|
| \(10\) | \(50\) | \(52\) |
| \(15\) | \(75\) | \(75\) |
| \(18\) | \(90\) | \(97\) |
| \(24\) | \(120\) | \(129\) |
| \(30\) | \(150\) | \(152\) |
| \(38\) | \(190\) | \(187\) |
- \(X_2\) 与 \(X_1\) 之间是完全线性关系:\(X_2=5X_1\) ;
- \(X_3\) 与 \(X_1\) 之间是不完全线性关系:\(X_3=5X_1+v\) ,其中 \(v=2,0,7,9,2,-3\) 。
二、多重共线性的产生原因
一般地,产生多重共线性的主要原因有以下几个方面:
-
模型设定错误:这个不需要解释,模型设定错误的时候什么情况都有可能发生,一定要克服。
-
数据采集方法不当:如果在总体中的一个较小的范围内抽样,\(X\) 没有显著的波动会导致 \(X\) 和截距项之间产生多重共线性的现象。
-
经济变量之间具有共同变化趋势:如时间序列数据中,GDP、就业人口、消费等数据的变化常常会具有相同的时间趋势。
-
模型中包含滞后变量:在经济计量模型中,往往需要引入滞后经济变量来反映真实的经济关系。例如,消费 \(=\) \(f(\)当期收入\(,\) 前期收入\()\) ,显然,这两期收入间有较强的线性相关性。
-
多项式的引入:如模型中包括 \(X,\,X^2,\,X^3\) 作为解释变量,当 \(X\) 变化不大时会呈现出严重的多重共线性。
我们可以做一个实验看看 \(X^2,\,X^3\) 和 \(X\) 之间可以带来什么程度的线性相关性。注意,这里的线性相关指的是统计意义上,可以利用协方差和相关系数衡量的相关性,而非线性代数中涉及的线性相关和线性无关的概念。如果利用后者的概念来理解,\(X^2,\,X^3\) 和 \(X\) 之间确实是线性无关的。
我们知道一元回归模型中,可决系数 \(R^2\) 和样本相关系数的平方 \(r^2\) 相等,因此我们利用 Stata 软件分别做 \(X^2,\,X^3\) 对 \(X\) 的简单回归,通过 \(R^2\) 的值来检验其相关性。
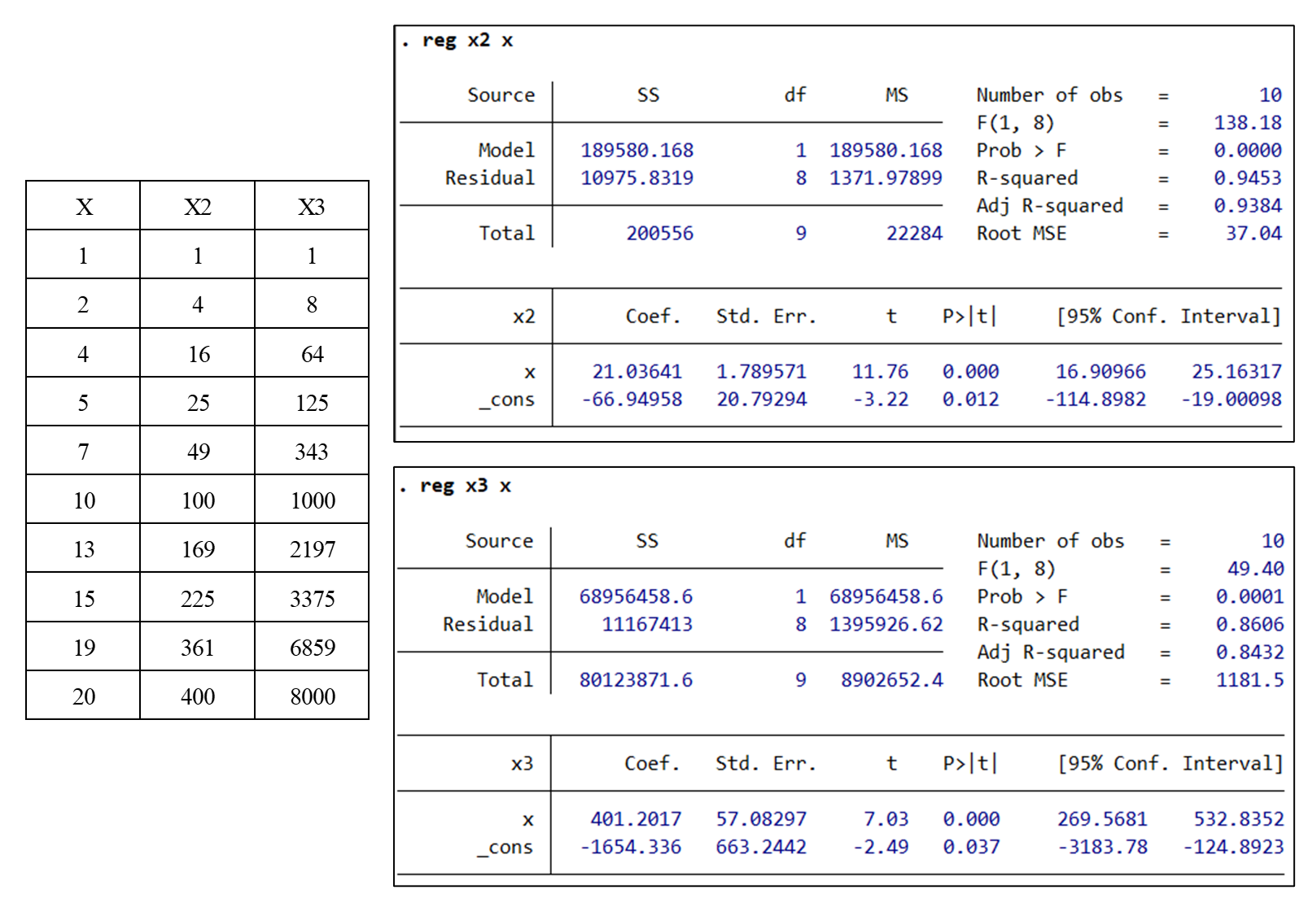
在 Stata 中输入以上数据,并利用 reg 命令进行回归。可以看出 \(X^2\) 和 \(X\) 之间的 \(R^2\) 高达 \(0.9453\) ,\(X^3\) 和 \(X\) 之间的 \(R^2\) 也有 \(0.8606\) ,在统计意义上体现出很强的相关性。
三、多重共线性的后果
在这里我们先回顾两个公式:
当模型中出现完全共线性时, \({\rm r}(\boldsymbol{X})<k+1\) ,因此 \({\rm det}(\boldsymbol{X}^{\rm T}\boldsymbol{X})=0\) ,即矩阵 \(\boldsymbol{X}^{\rm T}\boldsymbol{X}\) 是奇异矩阵,此时不存在矩阵的逆 \(\left(\boldsymbol{X}^{\rm T}\boldsymbol{X}\right)^{-1}\) ,因此不存在唯一确定的解 \(\hat{\boldsymbol{\beta}}\) 。另一方面,假设 \(X_j\) 可以被其他的解释变量线性表示,此时基于排除其他变量影响的方法,用 \(X_j\) 对其他解释变量做回归得到的 \(R_j^2=1\) ,导致 \(X_j\) 的参数估计值的方差 \({\rm Var}(\hat\beta_j)=\infty\) 。
概括起来,完全共线性的后果主要有两个方面:
- 参数估计值不唯一;
- 参数估计值的方差无限大。
当模型中出现多重共线性时,OLS 估计可以正常计算。而且由于多重共线性并没有违背任何一条经典假设,特别是高斯-马尔科夫假设,根据高斯-马尔科夫定理,多重共线性下的 OLS 估计仍然是最佳线性无偏估计量 BLUE 。但是多重共线性会造成估计的结果不够精确。仍然以 \(X_j\) 为例,当出现多重共线性时,\(R_j^2\) 会显著增大,导致参数估计的方差增大。我们可以引入方差膨胀因子 \({\rm VIF}\) 来衡量多重共线性导致的方差膨胀的倍数:
在这种情况下,多重共线性的后果主要有以下几个方面:
- 参数的估计值可计算,但不稳定;
- 参数估计量的方差增大;
- 对参数区间估计时,置信区间趋于变大,假设检验容易接受参数为 \(0\) 的假设;
- 可能造成 \(R^2\) 较高,但对各个参数单独的 \(t\) 检验却可能不显著,甚至可能使估计的回归系数符号相反,得出完全错误的结论。
四、多重共线性的检验方法
经验观察法
直观来看,出现多重共线性时常常伴随着较大的 \(R^2\) 和 \(F\) 值,但只有几个参数的 \(t\) 检验显著。
简单相关系数法
简单相关系数检验法是利用解释变量之间的线性相关程度去判断是否存在严重多重共线性的一种简便方法。一般而言,如果每两个解释变量的简单相关系数比较高,例如 \(|r|>0.8\) ,则可认为存在着较严重的多重共线性。
但我们需要注意的是,较高的简单相关系数只是多重共线性存在的充分条件,而不是必要条件。特别是在多于两个解释变量的回归模型中,有时较低的相关系数也可能存在多重共线性。因此并不能简单地依据相关系数进行多重共线性的准确判断。
辅助回归法
以某一解释变量 \(X_j\) 为被解释变量,以其余解释变量作为新的解释变量,进行一个新的回归分析。
得出回归的拟合优度 \(R^2_j\) (称为判定系数)和总显著性检验的 \(F\) 统计量 \(F_j\) 的值。
若 \(F\) 检验显著,\(F_j\) 较大,可以认为存在明显的多重共线性问题。
若对于所有的 \(j\) 都有 \(R^2_j>R^2\),可以认为存在明显的多重共线性问题。
方差膨胀因子法
方差膨胀因子的定义同上,
方差膨胀因子越大,表明解释变量之间的多重共性越严重。反过来,方差膨胀因子越接近于 \(1\) ,多重共线性越弱。若 \({\rm VIF}_j>10\) 且辅助回归 \(R^2_j>0.9\),可以认为存在明显的多重共线性问题,且这种多重共线性可能会过度地影响最小二乘估计。
五、多重共线性的修正措施
Part 1:常用修正措施
处理多重共线性的常用措施如下:
- 利用非样本的外部或先验信息作为约束条件:通过经济理论分析得到某些参数之间的关系,将这种关系作为约束条件,将此约束条件和样本信息结合起来进行受约束的最小二乘估计。
- 横截面与时间序列数据并用。
- 剔除高度共线性的变量(如逐步回归法),但可能引起模型的设定误差。
- 数据转换:
- 时间序列:做一阶差分;
- 计算相对指标;
- 将名义数据转换为实际数据;
- 将小类指标合并成大类指标。
- 选择有偏估计量(如岭回归,Lasso回归)。
- 不做任何处理,因为多重共线性下的 OLS 估计量仍然满足 BLUE 性质。
Part 2:逐步回归法和岭回归法
我们主要对逐步回归法和岭回归法做详细解释。
逐步回归法(Stepwise)
逐步回归法的步骤如下:
- 用被解释变量对每一个所考虑的解释变量做简单回归。
- 以对被解释变量贡献最大的解释变量所对应的回归方程为基础,按对被解释变量贡献大小的顺序逐个引入其余的解释变量。
逐步回归法中解释变量取舍的检验判断方式:
- 若新变量的引入改进了 \(R^2\) 和 \(F\) 检验,且回归参数的 \(t\) 检验在统计上也是显著的,则在模型中保留该变量。
- 若新变量的引入未能改进 \(R^2\) 和 \(F\) 检验,且对其他回归参数估计值的 \(t\) 检验也没有带来什么影响,则认为该变量是多余变量。
- 若新变量的引入未能改进 \(R^2\) 和 \(F\) 检验,且显著地影响了其他回归参数估计值的数值或符号,同时本身的回归参数也通不过 \(t\) 检验,说明出现了严重的多重共线性。
岭回归法(Ridge Regression)
岭回归分析实际上是一种改良的最小二乘法,是一种专门用于共线性数据分析的有偏估计回归方法,其目的是以引入偏误为代价减小参数估计量的方差。
当解释变量之间存在多重共线性时,\(\boldsymbol{X}^{\rm T}\boldsymbol{X}\) 是奇异的,也就是说它的行列式的值接近于 \(0\) ,或者说该矩阵有接近于 \(0\) 的特征根,此时 OLS 估计近乎失效。岭回归方法就是用 \((\boldsymbol{X}^{\rm T}\boldsymbol{X}+r\boldsymbol{D})\) 代替正规方程中的 \(\boldsymbol{X}^{\rm T}\boldsymbol{X}\) 。其中 \(r\) 为大于 \(0\) 的常数,称为岭回归系数,矩阵 \(\boldsymbol{D}\) 一般选择为主对角阵,具体计算方法如下:
此时岭回归的参数估计式为:
关于岭回归系数的选择:由上式可知 \(r\) 越大,\(\tilde{\boldsymbol\beta}(r)\) 对 \(\boldsymbol\beta\) 的偏差越大,但方差越小。因此我们需要选择一个惩罚适中的方案。理论选择最小化均方误差的 \(r\) :
其中,均方误差的定义为:
实际操作时可以利用统计软件对岭回归系数 \(r\) 进行搜索,直到估计的系数趋于稳定为止。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号