机器学习篇:sklearn.model_selection
sklearn提供了许多包来进行机器学习,只是很多不去了解的话,到使用的时候就会手忙脚乱根本不会去用,所以这里整理一下,这里整理的顺序是个人想要了解的顺序。
在一开始对这个工具毫无概念的话,可以尝试阅读:
2、sklearn.model_selection
sklearn有很完善的官方文档(

2.1.1 train_test_split 拆分训练集测试集
# train_test_split from sklearn.model_selection import train_test_split from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, random_state=SEED) print("拆分前:",X.shape,y.shape) X_train,y_train,X_test,y_test = train_test_split(X,y,test_size=0.25,random_state=SEED) print("拆分后:",X_train.shape,y_train.shape,X_test.shape,y_test.shape)
2.1.2 check_cv 简单进行五折拆分数据集
-
check_cv返回的是一个KFold实例
-
check_cv拆分后的顺序是没有打乱的,譬如100个样本拆分五折会默认分成五份,其下标固定为(0,19)(20,39)(40,59),(60,79)(80,99)
# check_cv from sklearn.model_selection import check_cv from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, random_state=SEED) print("拆分前:",X.shape,y.shape) aKFold = check_cv(cv=5, y=y, classifier=False) #返回的是一个KFold实例 for train_index, test_index in aKFold.split(X): # train_index, test_index返回的是下标 #print("%s %s" % (train_index, test_index)) X_train,y_train,X_test,y_test = X[train_index],y[train_index],X[test_index],y[test_index] print("拆分后:",X_train.shape,y_train.shape,X_test.shape,y_test.shape)
2.2 Splitter Classes 拆分器类
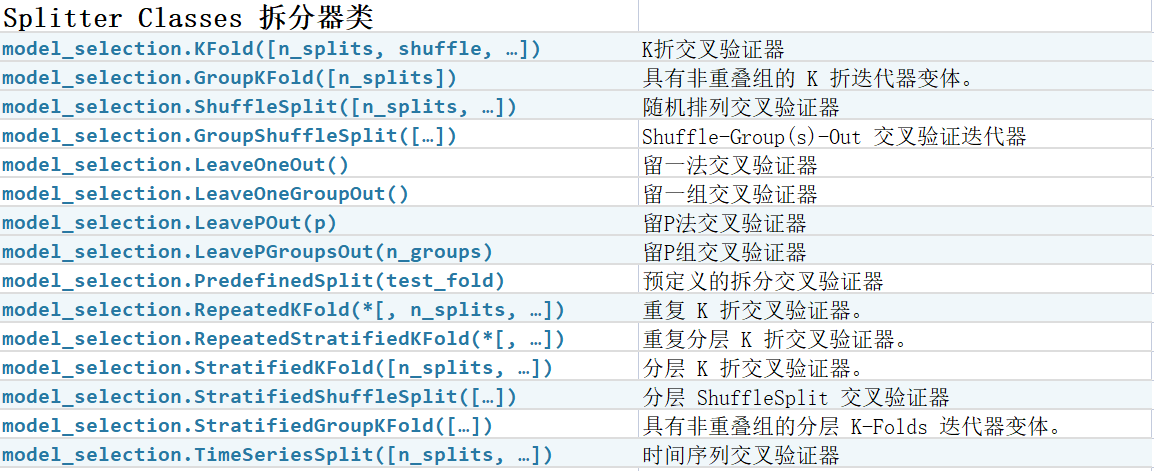

这里有15个数据集拆分器,为了灵活地应对各种拆分需求,各种拓展看着我头疼,甚至一度怀疑我这样子是不是在浪费时间。有时候其实只有在有应用需求的时候才会明白为什么需要这个拆分器。所以进行以下的分类,从简单的开始。

2.2.1 K折拆分--KFold
-
默认是五折拆分,不打乱顺序,不放回
-
shuffle=True后则是不固定的五折拆分,需要设置随机种子random_state以进行复现
# KFold #K折交叉验证,即将原数据集分成K份,每一折将其中一份作为测试集,其他k-1份作为训练集 # 随机的多折拆分(默认五折拆分),shuffle=True会打乱训练集测试集 from sklearn.model_selection import KFold from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, random_state=SEED) print("拆分前:",X.shape,y.shape) aKFold = KFold(n_splits=5, shuffle=True, random_state=SEED) #返回的是一个KFold实例,shuffle=True则不是固定的下标 for train_index, test_index in aKFold.split(X): # train_index, test_index返回的是下标 print("%s %s" % (train_index, test_index)) X_train,y_train,X_test,y_test = X[train_index],y[train_index],X[test_index],y[test_index] print("拆分后:",X_train.shape,y_train.shape,X_test.shape,y_test.shape)
2.2.2 K折拆分--GroupKFold
-
GroupKFold(n_splits=5):返回一个GroupKFold实例 -
GroupKFold.get_n_splits(self, X=None, y=None, groups=None):返回拆分的折数 -
split(self, X, y=None, groups=None),返回拆分结果index的迭代器, 会根据传入的第三个参数groups来拆分数据集X,y,使得拆分后分类比例不变
# GroupKFold # 简单的多折拆分(默认五折拆分),需要传入groups,会根据传入groups使得每个groups在训练集测试集的比例不变,与Stratified类似 from sklearn.model_selection import GroupKFold import numpy as np import pandas as pd from sklearn.datasets import make_classification #help(GroupKFold) SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, n_classes=2, n_clusters_per_class=1, n_informative =18, weights=[0.1,0.9], random_state=SEED) print("拆分前:",X.shape,y.shape) print("拆分前的数据") print(pd.DataFrame(y).value_counts()) group_kfold = GroupKFold(n_splits=2) #n_splits要与传入groups的分类数相符 #group_kfold.get_n_splits(X, y, y) # 会根据传入的第三个参数groups来拆分数据集X,y,传入了分类标签y所以会将二分类数据按照0,1拆开 for train_index, test_index in group_kfold.split(X, y, groups = y): print("拆分--------------------------------------------------") print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts()) print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] print("拆分后:",X_train.shape,y_train.shape,X_test.shape,y_test.shape)
2.2.3 K折拆分--StratifiedKFold
-
生成测试集,使所有包含相同的类分布,或尽可能接近。
-
是不变的类别标签:重贴标签到 不应该改变所产生的指标。
y = ["Happy", "Sad"]``y = [1, 0] -
保留数据集排序中的顺序依赖性,当
shuffle=False:某些测试集中来自类 k 的所有样本在 y 中是连续的,或者在 y 中被来自除 k 之外的类的样本分隔。 -
生成测试集,其中最小和最大最多相差一个样本。
# StratifiedKFold # 相比于KFold,在进行split的时候需要传入y,并且会根据y的分类,保证分类后y在各个数据集中比例不变,类似于GroupKFold(基于参数groups) import numpy as np import pandas as pd from sklearn.model_selection import * from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=200, n_features=20, shuffle=True, n_classes=3, n_clusters_per_class=1, n_informative =18, random_state=SEED) skf = StratifiedKFold(n_splits=5, shuffle=False, random_state=None) print("拆分前的数据") print(pd.DataFrame(y).value_counts()) for train_idx, test_idx in skf.split(X,y): print("拆分--------------------------------------------------") print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.4 K折拆分--StratifiedGroupKFold
# StratifiedGroupKFold # 在进行split的时候需要传入X,y和groups,观察其结果,似乎只取决于传入的group,group的长度取决于X、y的长度,分类数最好与n_splits相同 import numpy as np import pandas as pd from sklearn.model_selection import * from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=30, n_features=20, shuffle=True, n_classes=2, n_clusters_per_class=1, n_informative =18, random_state=SEED) sgk = StratifiedGroupKFold(n_splits=3, shuffle=False, random_state=None) print("拆分前的数据") print(pd.DataFrame(y).value_counts()) groups = np.hstack((np.zeros(10),np.ones(10),np.ones(10)+1)) for train_idx, test_idx in sgk.split(X,y,groups): print("TRAIN:", train_idx, "TEST:", test_idx) print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.5 K折拆分--RepeatedKFold
# RepeatedKFold #重复n_repeats次n_splits折的KFold拆分,最后拆分的次数应该是n_splits*n_repeats import numpy as np import pandas as pd from sklearn.model_selection import * from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=20, n_features=20, shuffle=True, n_classes=6, n_clusters_per_class=1, n_informative =18, weights=[0.1,0.5,0.1,0.1,0.1,0.1], random_state=SEED) #重复n_repeats次n_splits折的拆分,最后拆分的次数应该是n_splits*n_repeats rkf = RepeatedKFold(n_splits=4, n_repeats=2, random_state=666) for train_idx, test_idx in rkf.split(X): print("TRAIN:", train_idx, "TEST:", test_idx)
2.2.6 K折拆分--RepeatedStratifiedKFold
# RepeatedStratifiedKFold # 重复n_repeats次n_splits折的StratifiedKFold拆分,最后拆分的次数应该是n_splits*n_repeats import numpy as np import pandas as pd from sklearn.model_selection import * from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=30, n_features=20, shuffle=True, n_classes=2, n_clusters_per_class=1, n_informative =18, random_state=SEED) # rskf = RepeatedStratifiedKFold(n_splits=3, n_repeats=2, random_state=SEED) print("拆分前的数据") print(pd.DataFrame(y).value_counts()) for train_idx, test_idx in rskf.split(X,y): print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.7 随机拆分--ShuffleSplit
# ShuffleSplit # 相比于K折拆分,ShuffleSplit可指定拆分数据集的次数及每次拆分数据集的测试集比例 # 可指定拆分次数和测试集比例,需要指定random_state才可以复现数据 import numpy as np import pandas as pd from sklearn.model_selection import * from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, n_classes=6, n_clusters_per_class=1, n_informative =18, weights=[0.1,0.5,0.1,0.1,0.1,0.1], random_state=SEED) # ss = ShuffleSplit(n_splits=10, test_size=None, train_size=None, random_state=None) print("拆分前的数据") print(pd.DataFrame(y).value_counts()) # 完全是按照groups的参数进行的拆分 for train_idx, test_idx in ss.split(X, y): print("拆分--------------------------------------------------") print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.8 随机拆分--GroupShuffleSplit
# GroupShuffleSplit # 可指定拆分次数和测试集比例,需要传入groups,按照分组拆分 import numpy as np import pandas as pd from matplotlib import pyplot as plt from sklearn.model_selection import GroupShuffleSplit from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, n_classes=4, n_clusters_per_class=1, n_informative =18, weights=[0.1,0.6,0.2,0.1], random_state=SEED) # gss = GroupShuffleSplit(n_splits=5, test_size=0.2, train_size=None, random_state=SEED) print("拆分前的数据") print(pd.DataFrame(y).value_counts()) # 完全是按照groups的参数进行的拆分 for train_idx, test_idx in gss.split(X, y, groups=y): print("拆分--------------------------------------------------") print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.9 随机拆分--StratifiedShuffleSplit
# StratifiedShuffleSplit # 可指定拆分次数和测试集比例,需要传入X、y,在划分后的数据集中y标签比例相似 import numpy as np import pandas as pd from sklearn.model_selection import * from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=200, n_features=20, shuffle=True, n_classes=3, n_clusters_per_class=1, n_informative =18, random_state=SEED) skf = StratifiedShuffleSplit(n_splits=3, test_size=None, train_size=None, random_state=SEED) print("拆分前的数据") print(pd.DataFrame(y).value_counts()) for train_idx, test_idx in skf.split(X,y): print("拆分--------------------------------------------------") print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.10 留一法-- LeaveOneOut
#### LeaveOneOut import numpy as np import pandas as pd from sklearn.model_selection import * from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, n_classes=6, n_clusters_per_class=1, n_informative =18, weights=[0.1,0.5,0.1,0.1,0.1,0.1], random_state=SEED) # logo = LeaveOneOut() print("拆分前的数据") print(pd.DataFrame(y).value_counts()) # 完全是按照groups的参数进行的拆分 for train_idx, test_idx in logo.split(X, y): print("拆分--------------------------------------------------") print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.11 留一法-- LeaveOneGroupOut
# LeaveOneGroupOut import numpy as np import pandas as pd from matplotlib import pyplot as plt from sklearn.model_selection import LeaveOneGroupOut from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, n_classes=6, n_clusters_per_class=1, n_informative =18, weights=[0.1,0.5,0.1,0.1,0.1,0.1], random_state=SEED) # logo = LeaveOneGroupOut() print("拆分前的数据") print(pd.DataFrame(y).value_counts()) for train_idx, test_idx in logo.split(X, y, groups=y): print("拆分--------------------------------------------------") print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.12 留一法-- LeavePOut
#### LeavePOut
import numpy as np
import pandas as pd
from sklearn.model_selection import *
from sklearn.datasets import make_classification
SEED = 666
X,y = make_classification(n_samples=100,
n_features=20,
shuffle=True,
n_classes=6,
n_clusters_per_class=1,
n_informative =18,
weights=[0.1,0.5,0.1,0.1,0.1,0.1],
random_state=SEED)
#
logo = LeavePOut(10)
print("拆分前的数据")
print(pd.DataFrame(y).value_counts())
# 完全是按照groups的参数进行的拆分
for train_idx, test_idx in logo.split(X, y):
print("拆分--------------------------------------------------")
print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts())
print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.13 留一法-- LeavePGroupsOut
# LeavePGroupsOut import numpy as np import pandas as pd from sklearn.model_selection import * from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, n_classes=6, n_clusters_per_class=1, n_informative =18, weights=[0.1,0.5,0.1,0.1,0.1,0.1], random_state=SEED) # logo = LeavePGroupsOut(2) print("拆分前的数据") print(pd.DataFrame(y).value_counts()) for train_idx, test_idx in logo.split(X, y, groups=y): print("拆分--------------------------------------------------") print("训练集数据:\n",pd.DataFrame(y[train_idx]).value_counts()) print("测试集数据:\n",pd.DataFrame(y[test_idx]).value_counts())
2.2.14 指定拆分--PredefinedSplit
# PredefinedSplit #根据提前指定的分类来划分数据集,譬如说test_fold包含三类0、1、2,那么会拆分三次,每一次其中一类作为测试集,(-1对应的index永远在训练集) import numpy as np import pandas as pd from sklearn.model_selection import * from sklearn.datasets import make_classification SEED = 666 X,y = make_classification(n_samples=100, n_features=20, shuffle=True, n_classes=6, n_clusters_per_class=1, n_informative =18, weights=[0.1,0.5,0.1,0.1,0.1,0.1], random_state=SEED) # test_fold = np.hstack((np.zeros(20),np.ones(40),np.ones(10)+1,np.zeros(30)-1)) #分为三类0,1,2,设置为-1的样本永远包含在测试集中 print(test_fold) pres = PredefinedSplit(test_fold) for train_idx, test_idx in pres.split(): print("TRAIN:", train_idx, "TEST:", test_idx)
2.2.15 时间窗口拆分--TimeSeriesSplit
时间序列的拆分。
# TimeSeriesSplit # 时间序列拆分,类似于滑动窗口模式,以前n个样本作为训练集,第n+1个样本作为测试集 import numpy as np import pandas as pd from sklearn.model_selection import * X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]]) y = np.array([1, 2, 3, 4, 5, 6]) tss = TimeSeriesSplit(n_splits=5, max_train_size=None, test_size=None, gap=0) for train_idx, test_idx in tss.split(X): print("TRAIN:", train_idx, "TEST:", test_idx) ''' TRAIN: [0] TEST: [1] TRAIN: [0 1] TEST: [2] TRAIN: [0 1 2] TEST: [3] TRAIN: [0 1 2 3] TEST: [4] TRAIN: [0 1 2 3 4] TEST: [5] '''
2.2.x 附件笔记
# 15个 #---------------------------K折验证------------------------------------ #K折交叉验证,即将原数据集分成K份,每一折将其中一份作为测试集,其他k-1份作为训练集 # 随机的多折拆分(默认五折拆分),shuffle=True会打乱训练集测试集 KFold(n_splits=5, shuffle=True, random_state=SEED) for train_index, test_index in aKFold.split(X) # 简单的多折拆分(默认五折拆分),需要传入groups,会根据传入groups使得每个groups在训练集测试集的比例不变 GroupKFold(n_splits=5) for train_index, test_index in group_kfold.split(X, y, groups = y) # 相比于KFold,在进行split的时候需要传入y,并且会根据y的分类,保证分类后y在各个数据集中比例不变,类似于GroupKFold(基于参数groups) StratifiedKFold(n_splits=5, shuffle=False, random_state=None) # 在进行split的时候需要传入X,y和groups,观察其结果,似乎只取决于传入的group,group的长度取决于X、y的长度,分类数最好与n_splits相同 StratifiedGroupKFold(n_splits=3, shuffle=False, random_state=None) #重复n_repeats次n_splits折的KFold拆分,最后拆分的次数应该是n_splits*n_repeats RepeatedKFold(n_splits=4, n_repeats=2, random_state=666) # 重复n_repeats次n_splits折的StratifiedKFold拆分,最后拆分的次数应该是n_splits*n_repeats RepeatedStratifiedKFold(n_splits=3, n_repeats=2, random_state=SEED) # -------------------ShuffleSplit---------------------------------- # 相比于K折拆分,ShuffleSplit可指定拆分数据集的次数及每次拆分数据集的测试集比例 # 可指定拆分次数和测试集比例,需要指定random_state才可以复现数据 ShuffleSplit(n_splits=5, test_size=0.25, train_size=None, random_state=666) # 可指定拆分次数和测试集比例,需要传入X、y,在划分后的数据集中y标签比例相似 StratifiedShuffleSplit(n_splits=3, test_size=None, train_size=None, random_state=SEED) # 可指定拆分次数和测试集比例,需要传入groups,按照分组拆分 GroupShuffleSplit(n_splits=5, test_size=None, train_size=None, random_state=None) for train_idx, test_idx in gss.split(X, y=None, groups=y) # -------------------------留一法----------------------------------------- # 留一法及其拓展留P法,即指定1(或者P)个样本(或组)作为测试集,其他样本(或组)做为训练集,拆分数由样本数决定,不必指定 # 随机拆分的留一法,每次只会保留一个样本作为测试集,样本数为n则默认进行n-1次拆分 LeaveOneOut() for train_idx, test_idx in logo.split(X) # 按组拆分的留一法,按照传入的groups分组,然后根据分组进行留一拆分 LeaveOneGroupOut() for train_idx, test_idx in logo.split(X, y, groups=y): # 留一法的拓展,LeavePOut(1)与LeaveOneOut()是一样的 LeavePOut(p) # 留一法的拓展,LeavePGroupsOut(1)与LeaveOneGroupOut()是一样的 LeavePGroupsOut(p) #--------------------------指定拆分----------------------------------------- #根据提前指定的分类来划分数据集,譬如说test_fold包含三类0、1、2,那么会拆分三次,每一次其中一类作为测试集,(-1对应的index永远在训练集) test_fold = np.hstack((np.zeros(20),np.ones(40),np.ones(10)+1,np.zeros(30)-1)) #分为三类0,1,2,设置为-1的样本永远包含在测试集中 pres = PredefinedSplit(test_fold) # -------------------------时间序列拆分----------------------------------- # 时间序列拆分,类似于滑动窗口模式,以前n个样本作为训练集,第n+1个样本作为测试集 TimeSeriesSplit(n_splits=5, max_train_size=None, test_size=None, gap=0)