实践 2-0 selenium使用的一些总结
关键词:python、selenium
1、 selenium
selenium准确来说是自动化实例,可以用于一些自动化测试,但是所看到其不少应用大多跟爬虫相关。
1.1 爬虫的合法性
1.1.1 爬虫是否是违法的
主要是参考
结论是我们绝大多数公司和个人使用的爬虫都是没有问题的,不必人人自危,只要把握住不要爬取个人信息,不要利用爬虫非法获利,不要爬取网站的付费内容,基本上不会有问题。
技术无罪,不过人却是可以自我控制的,有时候就算公司要求,自己也得掂量掂量,需要注意:
-
遵守Robots协议。爬虫程序规避网站经营者设置的反爬虫措施或者破解服务器放抓取措施,非法获取相关信息,情节严重的,有可能构成“非法获取计算机信息系统数据罪”。
-
不能造成对方服务器瘫痪,干扰被访问的网站或系统正常运营,后果严重的,触犯刑法,构成破幻计算机信息系统罪。
-
不能非法获利。
-
爬取数据不能涉及个人隐私、公民信息,有可能构成侵犯公民个人信息罪。
-
不要将涉及到入侵、暴力破解、病毒等的代码上传到Github等地方。
-
......
1.1.2 robots.txt
网站根目录下通常会有一个文件robots.txt用来指明网站不允许爬取的内容与允许爬取的内容。以https://blog.csdn.net/robots.txt为例。
User-agent: * Disallow: /images/ Disallow: /content/ Disallow: /ui/ Disallow: /js/ Disallow: /*?* Sitemap: https://blog.csdn.net/s/sitemap_index/index_site_map.xml Sitemap: https://blog.csdn.net/s/sitemap_index/sitemap_list_index_category.xml Sitemap: https://blog.csdn.net/s/sitemap_index/sitemap_list_index_list.xml Sitemap: https://blog.csdn.net/s/sitemap_index/sitemap_list_index_time.xml
-
User-agent该项的值用于描述搜索引擎robot的名字,当其为*的时候,指的是以下规则针对的是全部访问。
-
Disallow用于描述不被希望被访问的一组URL,Allow描述的是希望被访问的一组URL。该值可以是一条完整的路径,也可以是路径的非空前缀。
-
Sitemap可方便网站管理员,通知搜索引擎他们网站上有哪些可供抓取的网页。
不过一般来说一个网站,出于什么目的会欢迎爬虫造访自己呢?好像只有搜索引擎这个答案吧?
1.1 爬虫与反爬虫
爬虫与反爬虫的争斗就像是加密解密一样,相互之间不断的卷了起来,不断地在时间成本及安全之间做取舍,不过因为网站创建出来就是供用户访问的,你能够做出一定的限制来拦住爬虫程序,但是并不能完全杜绝所有访问。
我在
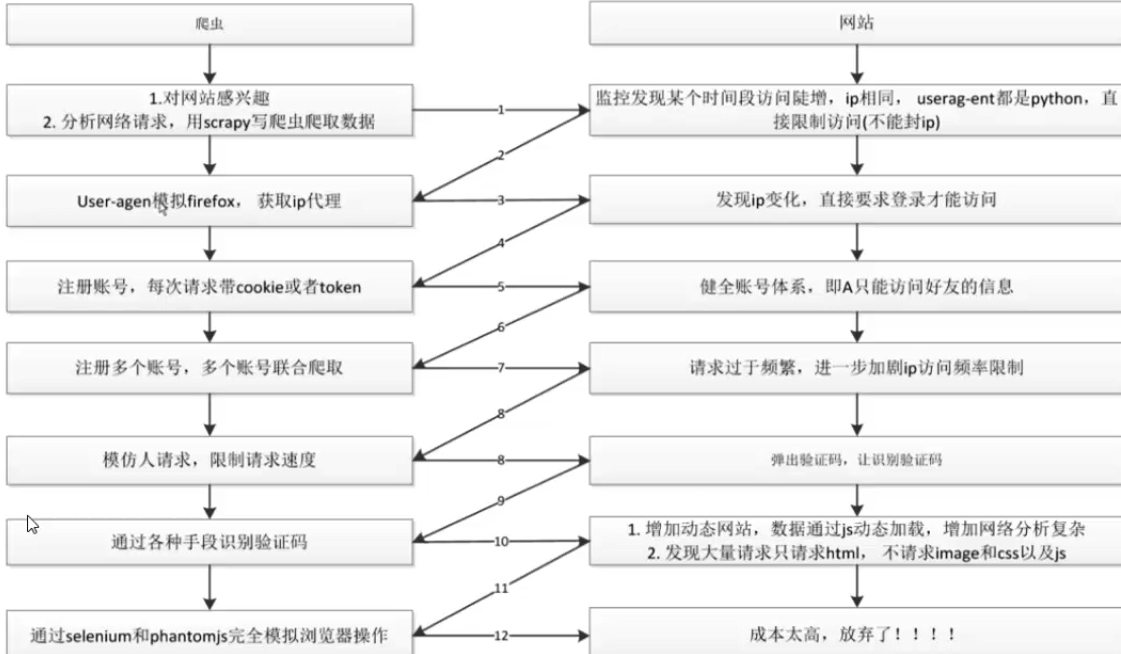
网站反爬虫也不过是出于以下考虑:
-
程序做出的大并发量的访问操作会加大服务器负担,影响正常访问,甚至可能直接把人家服务器搞掉。
-
爬虫窃取数据。
反爬虫的措施也包含:
-
针对useragent及ip访问频率限制。
-
限制登录才能查看信息。
-
健全账号体系,限制账号权限。
-
为登录、注册或者某些访问设置验证码
-
将网站数据访问、加载的过程变得更加复杂,加大网络分析的复杂程度
虽说爬虫的手段也在不断地进步,从设置ip代理、设置访问时的参数如(useragent、cookie、token)、验证码识别、selenium模拟浏览器,爬虫的手段不过是不断地模拟正常的访问,使得网站无法识别,但反爬虫的手段已经过滤了很多东西。例如useragent及ip访问频率限制过滤了一些简单粗暴的爬取;更加复杂的数据加载过程、账号登录及cookie、token的设置,加大了网络分析的成本;验证码及一些其他验证手段,发展到现在已经成为识别普通用户与机器人的重要手段,从账号登录注册、到某些论坛发言。
1.2 什么是selenium
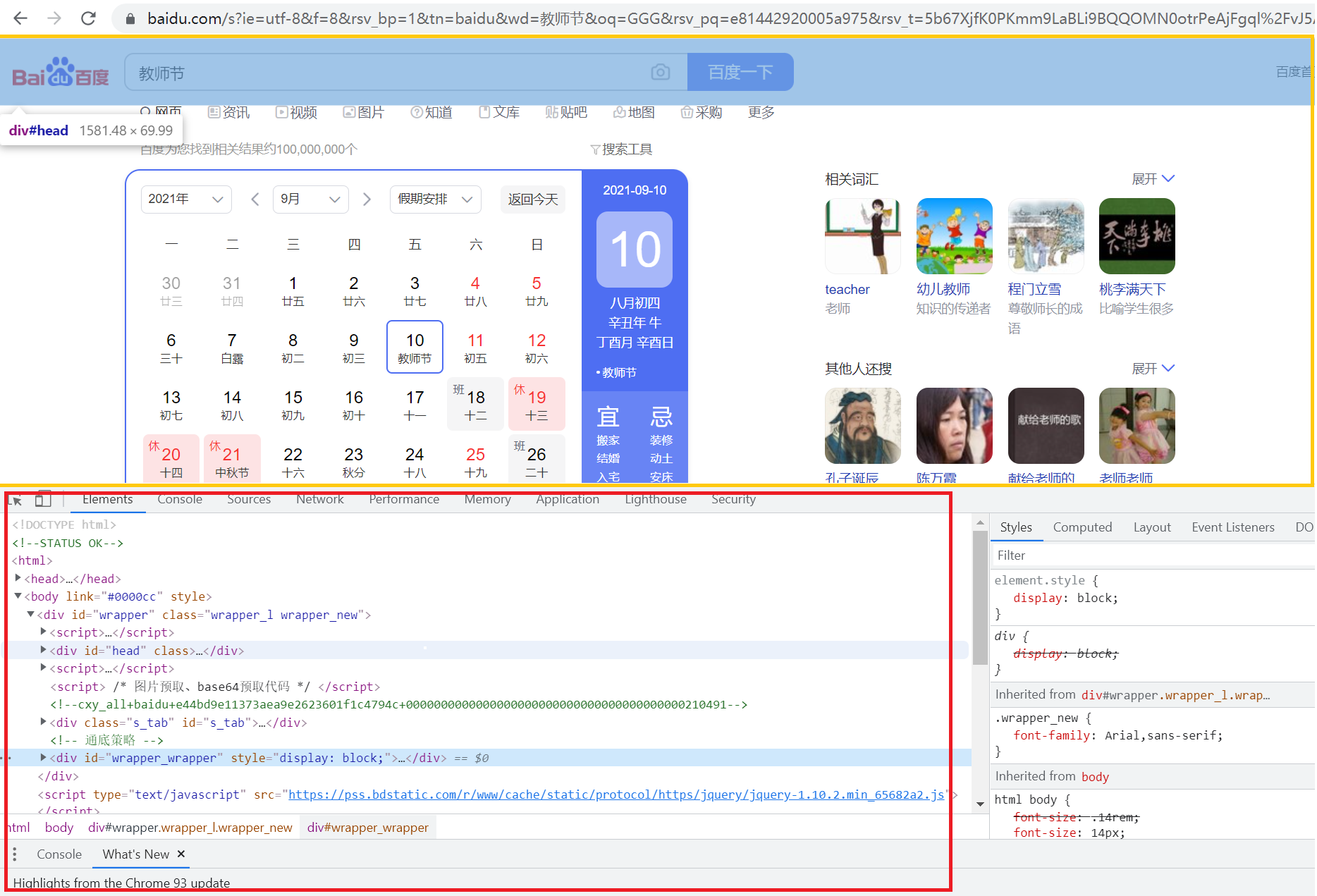
我看到有人将selenium称为自动化实例(Automation Example),selenium是一个用于对web网页进行自动化测试的工具,可以通过它提供的一些方法自动操作浏览器,可以完全模拟人的操作。相比于使用get/post方法,需要分析网页页面交互过程中的网络收发情况来组织网络请求操作与数据,selenium直接与页面交互,只要是最终展示在页面上,普通用户能够访问的数据,都能够访问到,能够绕开复杂的网络请求分析。
selenium所做的就是通过浏览器驱动提供的接口发起一些浏览器访问与交互操作。只不过普通用户关注的是黄框框内的内容,以及在网页界面内进行点击、悬浮、拖拽。而selenuim则是关注下方的内容,通过直接调用接口实现交互,如browser.find_element_by_css_selector('#botton').click()。
1.3 参考
2、selenium开发
2.1 selenium环境准备
这是基于python+selenuim+谷歌模拟器的开发:
-
安装python
-
安装selenuim
-
下载谷歌浏览器以及对应谷歌浏览器版本的驱动:http://npm.taobao.org/mirrors/chromedriver/ 驱动名称chromedriver.exe
使用的python是python3.7,python安装需要将安装目录及/Scrpits目录配置到环境变量中,chromedriver.exe放在python目录下,或者可以在创建是指定驱动位置。
from selenium import webdriver from selenium.webdriver import ChromeOptions import time browser = webdriver.Chrome(executable_path=r'chromedriver.exe') browser.get('https://www.baidu.com') time.sleep(2) browser.quit()
2.2 设置等待时间
无论是出于防止太频繁访问网站造成服务器负担,还是太频繁访问网站造成自己被封ip,还是说需要等待浏览器加载网页的时间,在配置爬虫程序的时候,最好配置合适的等待时间,虽然可能会花费更多时间,但是这个是必要的。
配置等待时间的方法有三种:
-
强制等待time.sleep()
-
隐式等待implicitly_wait()
-
显式等待WebDriverWait():可结合until使用
time.sleep()强制等待,等待时间固定。implicitly_wait()是由webdriver提供的方法,其效果是全局的,即只需要设置一次,每次查找元素的时候都会等待。
设置隐式等待implicitly_wait()之后,如果webDriver没有DOM中找到元素,将继续等待,超出设定时间后则抛出找不到元素的异常。即当查找元素或者元素并没有立即出现的时候,隐式等待将等待一段时间(默认是0)再查找DOM,有说法是隐式等待并不针对你查找的那个元素而是针对全局,每次查找等待都是以全局有没有加载完毕来算的,所以会增加整个测试执行时间。
import time import random # 随机等待一段时间 def wait_a_time(num=0): if num<=0: time.sleep(random.randint(1,9)) else: time.sleep(num) # 设置隐式等待 driver.implicitly_wait(10) from selenium.webdriver.support.wait import WebDriverWait WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None) #driver:浏览器驱动 #timeout:最长超时时间,默认以秒为单位 #poll_frequency:检测的间隔步长,默认为0.5s #ignored_exceptions:超时后的抛出的异常信息,默认抛出NoSuchElementExeception异常。
显示等待WebDriverWait可配合until()、until_not()、expected_conditions()等配置有等待条件的等待,也可以设置超时。
WebDriverWait(driver, timeout).until(method, message=’’) WebDriverWait(driver, timeout).until_not(method, message=’’) print(time.ctime()) try: WebDriverWait(driver, 10).until(lambda the_driver: the_driver.find_element_by_id('kw'), '失败') except Exception as e: print(e) print(time.ctime())
也可以配合expected_conditions使用。
from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By wait = WebDriverWait(driver,10,0.5) element =wait.until(EC.presence_of_element_located((By.ID,"kw")),message="") # 此处注意,如果省略message=“”,则By.ID外面是三层()
expected_conditions类提供的预期条件判断的方法
| 方法 | 说明 |
|---|---|
| title_is | 判断当前页面的title是否完全等于(==)预期字符串,返回布尔值 |
| title_contains | 判断当前页面的title是否包含预期字符串,返回布尔值 |
| presence_of_element_located | 判断某个元素是否被加到了dom树里,并不代表该元素一定可见 |
| visibility_of_element_located | 判断元素是否可见(可见代表元素非隐藏,并且元素宽和高都不等于0) |
| visibility_of | 同上一方法,只是上一方法参数为locator,这个方法参数是定位后的元素 |
| presence_of_all_elements_located | 判断是否至少有1个元素存在于dom树中。举例:如果页面上有n个元素的class都是’wp’,那么只要有1个元素存在,这个方法就返回TRUE |
| text_to_be_present_in_element | 判断某个元素中的text是否包含了预期的字符串 |
| text_to_be_present_in_element_value | 判断某个元素中的value属性是否包含了预期的字符串 |
| frame_to_be_available_and_switch_to_it | 判断该frame是否可以switch进去,如果可以的话,返回TRUE并且switch进去,否则返回FALSE |
| invisibility_of_element_located | 判断某个元素中是否不存在于dom树或不可见 |
| element_to_be_clickable | 判断某个元素中是否可见并且可点击 |
| staleness_of | 等某个元素从dom树中移除,注意,这个方法也是返回True或FALSE |
| element_to_be_selected | 判断某个元素是否被选中了,一般用在下拉列表 |
| element_selection_state_to_be | 判断某个元素的选中状态是否符合预期 |
| element_located_selection_state_to_be | 跟上面的方法作用一样,只是上面的方法传入定位到的element,而这个方法传入locator |
| alert_is_present | 判断页面上是否存在alert |
参考:
2.3 获取元素
# selenium提供的元素定位的方法 ## CSS选择器 相关的方法 browser.find_element_by_css_selector(selector) #匹配符合css选择器条件的元素 browser.find_element_by_class_name(name) #匹配class属性值元素 browser.find_element_by_id(id) #匹配id属性值的元素 browser.find_element_by_link_text(text) #完全匹配提供text的a元素 browser.find_element_by_partial_link_text(text) #包含提供的text的a元素 browser.find_element_by_name(name) #匹配name属性值的元素 browser.find_element_by_tag_name(name) #匹配标签name的元素(大小写无关,a匹配'a'和'A',div则匹配所有div元素) ## xpath 相关的方法 browser.find_element(s)_by_xpath() #匹配符合xpath路径的元素
查找元素存在则返回元素的方法:
# 某浏览器页面是否包含某元素,有则返回 def find_tag(browser,seletor): try: return browser.find_element_by_css_selector(seletor) except: pass # 调用 browser = webdriver.Chrome(executable_path='chromedriver.exe') browser.get('https://www.baidu.com') time.sleep(2) print(find_tag(browser,'div')) browser.quit()
一些选择器(
| 例子 | 例子描述 | |
|---|---|---|
| .intro | 选择 class="intro" 的所有元素。 | |
| .class1.class2 | .name1.name2 | 选择 class 属性中同时有 name1 和 name2 的所有元素。 |
| .class1 .class2 | .name1 .name2 | 选择作为类名 name1 元素后代的所有类名 name2 元素。 |
| #firstname | 选择 id="firstname" 的元素。 | |
| * | 选择所有元素。 | |
| p | 选择所有 <p> 元素。 | |
| p.intro | 选择 class="intro" 的所有 <p> 元素。 | |
| div, p | 选择所有 <div> 元素和所有 <p> 元素。 | |
| div p | 选择 <div> 元素内的所有 <p> 元素。 | |
| div > p | 选择父元素是 <div> 的所有 <p> 元素。 | |
| div + p | 选择紧跟 <div> 元素的首个 <p> 元素。 | |
| p ~ ul | 选择前面有 <p> 元素的每个 <ul> 元素。 | |
| [ | [target] | 选择带有 target 属性的所有元素。 |
| [ | [target=_blank] | 选择带有 target="_blank" 属性的所有元素。 |
| [ | [title~=flower] | 选择 title 属性包含单词 "flower" 的所有元素。 |
| [ | [lang|=en] | 选择 lang 属性值以 "en" 开头的所有元素。 |
| [ | a[href^="https"] | 选择其 src 属性值以 "https" 开头的每个 <a> 元素。 |
| [ | a[href$=".pdf"] | 选择其 src 属性以 ".pdf" 结尾的所有 <a> 元素。 |
| [ | a[href*="w3schools"] | 选择其 href 属性值中包含 "abc" 子串的每个 <a> 元素。 |
| a:active | 选择活动链接。 | |
| p::after | 在每个 <p> 的内容之后插入内容。 | |
| p::before | 在每个 <p> 的内容之前插入内容。 | |
| input:checked | 选择每个被选中的 <input> 元素。 | |
| input:default | 选择默认的 <input> 元素。 | |
| input:disabled | 选择每个被禁用的 <input> 元素。 | |
| p:empty | 选择没有子元素的每个 <p> 元素(包括文本节点)。 | |
| input:enabled | 选择每个启用的 <input> 元素。 | |
| p:first-child | 选择属于父元素的第一个子元素的每个 <p> 元素。 | |
| p::first-letter | 选择每个 <p> 元素的首字母。 | |
| p::first-line | 选择每个 <p> 元素的首行。 | |
| p:first-of-type | 选择属于其父元素的首个 <p> 元素的每个 <p> 元素。 | |
| input:focus | 选择获得焦点的 input 元素。 | |
| :fullscreen | 选择处于全屏模式的元素。 | |
| a:hover | 选择鼠标指针位于其上的链接。 | |
| input:in-range | 选择其值在指定范围内的 input 元素。 | |
| input:indeterminate | 选择处于不确定状态的 input 元素。 | |
| input:invalid | 选择具有无效值的所有 input 元素。 | |
| p:lang(it) | 选择 lang 属性等于 "it"(意大利)的每个 <p> 元素。 | |
| p:last-child | 选择属于其父元素最后一个子元素每个 <p> 元素。 | |
| p:last-of-type | 选择属于其父元素的最后 <p> 元素的每个 <p> 元素。 | |
| a:link | 选择所有未访问过的链接。 | |
| :not(p) | 选择非 <p> 元素的每个元素。 | |
| p:nth-child(2) | 选择属于其父元素的第二个子元素的每个 <p> 元素。 | |
| p:nth-last-child(2) | 同上,从最后一个子元素开始计数。 | |
| p:nth-of-type(2) | 选择属于其父元素第二个 <p> 元素的每个 <p> 元素。 | |
| p:nth-last-of-type(2) | 同上,但是从最后一个子元素开始计数。 | |
| p:only-of-type | 选择属于其父元素唯一的 <p> 元素的每个 <p> 元素。 | |
| p:only-child | 选择属于其父元素的唯一子元素的每个 <p> 元素。 | |
| input:optional | 选择不带 "required" 属性的 input 元素。 | |
| input:out-of-range | 选择值超出指定范围的 input 元素。 | |
| input::placeholder | 选择已规定 "placeholder" 属性的 input 元素。 | |
| input:read-only | 选择已规定 "readonly" 属性的 input 元素。 | |
| input:read-write | 选择未规定 "readonly" 属性的 input 元素。 | |
| input:required | 选择已规定 "required" 属性的 input 元素。 | |
| :root | 选择文档的根元素。 | |
| ::selection | 选择用户已选取的元素部分。 | |
| #news:target | 选择当前活动的 #news 元素。 | |
| input:valid | 选择带有有效值的所有 input 元素。 | |
| a:visited | 选择所有已访问的链接。 |
2.4 元素方法
只讲讲暂时涉及的,后面用到其他的再添加。
将一个获取的元素打开来,结果如下所示:
element = browser.find_element_by_css_selector('nody') print(dir(element)) ''' ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_execute', '_id', '_parent', '_upload', '_w3c', 'clear', 'click', 'find_element', 'find_element_by_class_name', 'find_element_by_css_selector', 'find_element_by_id', 'find_element_by_link_text', 'find_element_by_name', 'find_element_by_partial_link_text', 'find_element_by_tag_name', 'find_element_by_xpath', 'find_elements', 'find_elements_by_class_name', 'find_elements_by_css_selector', 'find_elements_by_id', 'find_elements_by_link_text', 'find_elements_by_name', 'find_elements_by_partial_link_text', 'find_elements_by_tag_name', 'find_elements_by_xpath', 'get_attribute', 'get_property', 'id', 'is_displayed', 'is_enabled', 'is_selected', 'location', 'location_once_scrolled_into_view', 'parent', 'rect', 'screenshot', 'screenshot_as_base64', 'screenshot_as_png', 'send_keys', 'size', 'submit', 'tag_name', 'text', 'value_of_css_property'] '''
# 在元素中查找其子元素的方法:find开头的方法 get_attribute #获取元素的特性,attribute是HTML标签上的特性,它的值只能够是字符串 get_property #获取元素的属性,property是DOM中的属性,是JavaScript里的对象 value_of_css_property #属性值 id #元素id,但是返回值并不是我们以为的id parent #返回的是元素对应的WebDriver对象 tag_name #元素的tag值 text #text属性 is_displayed # 是否可见 is_enabled #是否可用 is_selected #是否被选中 location #返回元素坐标 size #获取元素大小 # 3、行为 clear #清空元素文本,如input的输入框 click #点击动作 send_keys #向元素输入key submit #提交动作 location_once_scrolled_into_view #滚动到该元素 rect #返回元素的坐标及大小,但是跟location可能会有偏差 #截图相关 screenshot screenshot_as_base64 screenshot_as_png
1)在元素中查找其子元素的方法:find开头的方法
find_element, find_element_by_class_name, find_element_by_css_selector, find_element_by_id, find_element_by_link_text, find_element_by_name, find_element_by_partial_link_text, find_element_by_tag_name, find_element_by_xpath, find_elements, find_elements_by_class_name, find_elements_by_css_selector, find_elements_by_id, find_elements_by_link_text, find_elements_by_name, find_elements_by_partial_link_text, find_elements_by_tag_name, find_elements_by_xpath
2)获取一些元素的属性和状态
get_property与get_attribute的区别具体可看
w = webdriver.Chrome(executable_path='chromedriver.exe',options=option) w.get('https://www.baidu.com/s?ie=UTF-8&wd=selenium') w.implicitly_wait(10) #设置隐式等待 input = w.find_element_by_css_selector('#kw') print(input.id) #fcbde355-0086-466a-98fd-435d783e3aa4 print(type(input.parent)) #<class 'selenium.webdriver.chrome.webdriver.WebDriver'> print(input.tag_name)# input print(input.text) # 为空,因为没有这个属性 print(input.get_attribute('innerHTML')) # 为空,因为input类型的标签内部没有html了 print(input.get_property ('outerHTML')) #<input id="kw" name="wd" class="s_ipt" value="selenium" maxlength="255" autocomplete="off"> print(input.is_displayed) #<bound method WebElement.is_displayed of <selenium.webdriver.remote.webelement.WebElement (session="234b2dfc560e24832424c87eb2680093", element="e9bd7414-a358-462e-9296-c26cccc6766c")>> print(input.is_enabled) #<bound method WebElement.is_enabled of <selenium.webdriver.remote.webelement.WebElement (session="234b2dfc560e24832424c87eb2680093", element="e9bd7414-a358-462e-9296-c26cccc6766c")>> print(input.is_selected) #<bound method WebElement.is_selected of <selenium.webdriver.remote.webelement.WebElement (session="234b2dfc560e24832424c87eb2680093", element="e9bd7414-a358-462e-9296-c26cccc6766c")>>
3)keys
在send_keys方法中,除了字母及特殊符号,还可以输入一些其他的按键信息,如ctrl,alt等等
from selenium.webdriver.common.keys import Keys dir(Keys) ['ADD', 'ALT', 'ARROW_DOWN', 'ARROW_LEFT', 'ARROW_RIGHT', 'ARROW_UP', 'BACKSPACE', 'BACK_SPACE', 'CANCEL', 'CLEAR', 'COMMAND', 'CONTROL', 'DECIMAL', 'DELETE', 'DIVIDE', 'DOWN', 'END', 'ENTER', 'EQUALS', 'ESCAPE', 'F1', 'F10', 'F11', 'F12', 'F2', 'F3', 'F4', 'F5', 'F6', 'F7', 'F8', 'F9', 'HELP', 'HOME', 'INSERT', 'LEFT', 'LEFT_ALT', 'LEFT_CONTROL', 'LEFT_SHIFT', 'META', 'MULTIPLY', 'NULL', 'NUMPAD0', 'NUMPAD1', 'NUMPAD2', 'NUMPAD3', 'NUMPAD4', 'NUMPAD5', 'NUMPAD6', 'NUMPAD7', 'NUMPAD8', 'NUMPAD9', 'PAGE_DOWN', 'PAGE_UP', 'PAUSE', 'RETURN', 'RIGHT', 'SEMICOLON', 'SEPARATOR', 'SHIFT', 'SPACE', 'SUBTRACT', 'TAB', 'UP', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
参考:
2.5 WebDriver相关方法
from selenium import webdriver from selenium.webdriver import ChromeOptions option = ChromeOptions() browser = webdriver.Chrome(executable_path='chromedriver.exe',options=option) print(dir(browser)) ''' ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_file_detector', '_is_remote', '_mobile', '_switch_to', '_unwrap_value', '_web_element_cls', '_wrap_value', 'add_cookie', 'application_cache', 'back', 'capabilities', 'close', 'command_executor', 'create_options', 'create_web_element', 'current_url', 'current_window_handle', 'delete_all_cookies', 'delete_cookie', 'desired_capabilities', 'error_handler', 'execute', 'execute_async_script', 'execute_cdp_cmd', 'execute_script', 'file_detector', 'file_detector_context', 'find_element', 'find_element_by_class_name', 'find_element_by_css_selector', 'find_element_by_id', 'find_element_by_link_text', 'find_element_by_name', 'find_element_by_partial_link_text', 'find_element_by_tag_name', 'find_element_by_xpath', 'find_elements', 'find_elements_by_class_name', 'find_elements_by_css_selector', 'find_elements_by_id', 'find_elements_by_link_text', 'find_elements_by_name', 'find_elements_by_partial_link_text', 'find_elements_by_tag_name', 'find_elements_by_xpath', 'forward', 'fullscreen_window', 'get', 'get_cookie', 'get_cookies', 'get_log', 'get_network_conditions', 'get_screenshot_as_base64', 'get_screenshot_as_file', 'get_screenshot_as_png', 'get_window_position', 'get_window_rect', 'get_window_size', 'implicitly_wait', 'launch_app', 'log_types', 'maximize_window', 'minimize_window', 'mobile', 'name', 'orientation', 'page_source', 'quit', 'refresh', 'save_screenshot', 'service', 'session_id', 'set_network_conditions', 'set_page_load_timeout', 'set_script_timeout', 'set_window_position', 'set_window_rect', 'set_window_size', 'start_client', 'start_session', 'stop_client', 'switch_to', 'switch_to_active_element', 'switch_to_alert', 'switch_to_default_content', 'switch_to_frame', 'switch_to_window', 'title', 'w3c', 'window_handles'] '''
从上面可以看到WebDriver的方法不少,不过大部分没有应用过。懒得一个个去看了,应用到了再说。
-
quit和close的区别:quit是退出当前窗口,close是退出浏览器驱动,退出全部关联窗口。
参考:
2.6 ActionChains
ActionChains直译过来就是动作链,当调用ActionChains的方法时不会立即执行,而是将所有操作按顺序放在一个队列里,当调用perform()方法时才会依次执行,可用于模拟鼠标操作,如单击、双击、点击鼠标右键、拖拽等等。
有两种写法,链式写法和分布写法。
#链式写法 menu = driver.find_element_by_css_selector(".nav") hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1") ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform() #分步写法 menu = driver.find_element_by_css_selector(".nav") hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1") actions = ActionChains(driver) actions.move_to_element(menu) actions.click(hidden_submenu) actions.perform()
ActionChains方法列表
click(on_element=None) ##单击鼠标左键 click_and_hold(on_element=None) ##点击鼠标左键,不松开 context_click(on_element=None) ##点击鼠标右键 double_click(on_element=None) ##双击鼠标左键 drag_and_drop(source, target) ##拖拽到某个元素然后松开 drag_and_drop_by_offset(source, xoffset, yoffset) ##拖拽到某个坐标然后松开 key_down(value, element=None) ##按下某个键盘上的键 key_up(value, element=None) ##松开某个键 move_by_offset(xoffset, yoffset) ##鼠标从当前位置移动到某个坐标 move_to_element(to_element) ##鼠标移动到某个元素 move_to_element_with_offset(to_element, xoffset, yoffset) ##移动到距某个元素(左上角坐标)多少距离的位置 perform() ##执行链中的所有动作 release(on_element=None) ##在某个元素位置松开鼠标左键 send_keys(*keys_to_send) ##发送某个键到当前焦点的元素 send_keys_to_element(element, *keys_to_send) ##发送某个键到指定元素
参考:
2.7 浏览器窗口切换及iframe
-
常用的访问网址的方法是get,其默认是在原来窗口打开一个网页,会覆盖原来的网页。
-
selenium提供了直接调用js语句的方法,所以可以通过调用window.open()来打开界面
-
selenium使用快捷方式打开新的标签页,不过结果失败,不明原因打不开
from selenium import webdriver from selenium.webdriver import ChromeOptions from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.keys import Keys if __name__=='__main__': option = ChromeOptions() w = webdriver.Chrome(executable_path='chromedriver.exe',options=option) w.implicitly_wait(10) w.get('https://www.baidu.com') # 【窗口1】 # 方法一 覆盖界面 w.get('https://www.baidu.com/s?ie=UTF-8&wd=selenium') # 直接覆盖在同一窗口的同一标签页 【窗口1】 # 方法二 js调用window.open() js='window.open("");' # 打开新的空标签页 【窗口2】 w.execute_script(js) js='window.open("https://www.baidu.com/s?ie=UTF-8&wd=python");' w.execute_script(js) # 在新的标签页打开python的百度界面 【窗口3】 # 方法三 使用ctrl+t的方式打开新的空标签页 w.find_element_by_css_selector('body').send_keys(Keys.CONTROL +"t");#【窗口4】 ActionChains(w).key_down(Keys.CONTROL).send_keys("t").key_up(Keys.CONTROL).perform(); #【窗口5】 tabs = w.window_handles; for t in tabs: print(t) w.quit()
最后输出如下所示,即只有三个窗口,因为窗口4、窗口5没能打开,我并不清楚原因。
手动进入模拟浏览器界面输入键盘ctrl+t是可以打开新标签页的,将.send_keys(Keys.CONTROL +"t")更改为.send_keys(Keys.CONTROL +"a")会在窗口1呈现“全选”的状态,但是就是无法通过.send_keys(Keys.CONTROL +"t")打开新的标签页,也无法通过.send_keys(Keys.CONTROL +Keys.TAB)切换标签页,这个问题只能暂时搁置。
CDwindow-87A4C884959850140C4D04DDF921D0A2 CDwindow-44BDF2CC599EF700F7969F31DAD9C4DE CDwindow-3AC76EF19AC69A09BFBCC455C7458E5A
句柄handle
前面语句测试的时候有说,ctrl+a的全选效果是呈现在窗口1,而不是后面新建的窗口2和窗口3,这是因为窗口句柄handle仍指向窗口1,如果需要操作新建的标签页,需要进行切换。
以下语句,在窗口1进行复制的动作链经常会失败。准确说来,只有我删除了后续跳转窗口的操作后才会复制成功。
if __name__=='__main__': option = ChromeOptions() w = webdriver.Chrome(executable_path='chromedriver.exe',options=option) w.implicitly_wait(10) w.get('https://www.baidu.com/s?ie=UTF-8&wd=selenium') # 【打开窗口1】 js='window.open("");' # 打开新的空标签页 【打开空标签页--窗口2】 w.execute_script(js) # 查看现有的窗口句柄 print('现有:') tabs = w.window_handles; for t in tabs: print(t) print('------------------------------------------') # 查看持有句柄的窗口 print('现在是:',w.current_window_handle) # 从现在持有句柄的窗口1的输入框复制文字 actions = ActionChains(w) input = w.find_element_by_css_selector('#kw') actions.key_down(Keys.CONTROL).send_keys_to_element(input,"a").send_keys_to_element(input,"c").key_up(Keys.CONTROL).perform() # 这个复制经常不成功 # 跳转到新窗口 #w.switch_to_window(tabs[1]) # 不推荐 w.switch_to.window(tabs[1]) w.get('https://www.baidu.com/s?ie=UTF-8&wd=1') # 查看持有句柄的窗口 print('现在是:',w.current_window_handle) #actions.send_keys_to_element(input,"v") input2 = w.find_element_by_css_selector('#kw') ActionChains(w).key_down(Keys.CONTROL).send_keys_to_element(input2,"a").send_keys_to_element(input2,"v").key_up(Keys.CONTROL).key_down(Keys.ENTER).key_up(Keys.ENTER).perform() # 跳转回窗口1 w.switch_to.window(tabs[0]) # 查看持有句柄的窗口 print('现在是:',w.current_window_handle) w.quit()
内嵌网页iframe
内嵌网页很好理解,就是在一个网页中嵌入了另外一个网页;而但我们browser获取的是外层网页的信息,就无法定位到内层网页中的元素;内嵌网页都是被一个iframe元素所包围的,所以我们需要先定位到这个iframe元素,接着再指定browser来跳转到iframe元素内的内嵌网页中来查找元素。
前面切换窗口有两个方法:
w.switch_to_window(tabs[1])
w.switch_to.window(tabs[1])
切换iframe的方法也有两个:
w.switch_to_frame(tabs[1])
w.switch_to.frame(tabs[1])
同样的还有switch_to_alert,不过似乎switch_to_window、switch_to_frame和switch_to_alert都会报warnning,不推荐使用,都替换成了switch_to方法,包含:
switch_to.window(window_handle) # 窗口切换 switch_to.frame(element) # 进入内嵌网页iframe switch_to.alert(element) #进入提示页 switch_to.default_content # 返回默认窗口
参考:
3 模拟浏览器参数options设置
大部分参考:
3.1 背景
在使用selenuim浏览器渲染技术爬取网站信息时,默认情况下就是一个普通的纯净的chrome浏览器,而我们平时在使用浏览器时,经常就添加一些插件,拓展,代理之类的应用。相对应的,当我们用chrome浏览器爬取网站时,可能需要对这个chrome做一些特殊的配置,以满足爬虫的行为。
常用的行为有:
-
禁止图片和视频加载:提升网页加载速度。
-
添加代理:用于FQ访问某些页面,或者应对ip访问频率限制的反爬技术。
-
使用移动头:访问移动端的站点,一般这种站点的反爬技术比较薄弱。
-
添加扩展:像正常使用浏览器一样的功能。
-
设置编码:应对中文站,防止乱码。
-
组织javascript执行。
-
等
3.2 ChromeOptions
ChromeOptions是一个配置chrome启动时属性的类。通过这个类,我们可以为chrome配置如下参数:
-
设置chrome二进制文件位置(binary_location)
-
添加启动参数(add_argument)
-
添加扩展应用(add_extension,add_encoded_extension)
-
添加实验性质的设置参数(add_experimental_option)
-
设置调试器地址(debugger_address)
from selenium.webdriver import ChromeOptions option = ChromeOptions() print(dir(option)) ''' ['KEY', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_arguments', '_binary_location', '_caps', '_debugger_address', '_experimental_options', '_extension_files', '_extensions', 'add_argument', 'add_encoded_extension', 'add_experimental_option', 'add_extension', 'arguments', 'binary_location', 'capabilities', 'debugger_address', 'experimental_options', 'extensions', 'headless', 'set_capability', 'set_headless', 'to_capabilities'] '''
-
使用案例
# 设置默认编码为 utf-8,也就是中文 from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument('lang=zh_CN.UTF-8') driver = webdriver.Chrome(chrome_options = options)
3.3 设置编码格式
# 设置默认编码为utf-8,防止中文乱码 from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument('lang=zh_CN.UTF-8') driver = webdriver.Chrome(chrome_options = options)
3.4 模拟移动设备
参考
# 通过设置user-agent来模拟移动设备 # 比如模拟android QQ浏览器 # 通过设置user-agent,用来模拟移动设备 # 比如模拟 android QQ浏览器 options.add_argument('user-agent="MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"') # 模拟iPhone 6 options.add_argument('user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1"')
3.5 禁止图片加载
不加载图片的情况下,可提升爬取速度,不过如果有验证码之类的操作,似乎会比较麻烦,原文未给出后面代码的详细解释,后续研究再说吧。
# 禁止图片的加载 from selenium import webdriver chrome_options = webdriver.ChromeOptions() prefs = {"profile.managed_default_content_settings.images": 2} chrome_options.add_experimental_option("prefs", prefs) # 启动浏览器,并设置好wait browser = webdriver.Chrome(chrome_options=chrome_options) browser.set_window_size(configure.windowHeight, configure.windowWidth) # 根据桌面分辨率来定,主要是为了抓到验证码的截屏 wait = WebDriverWait(browser, timeout = configure.timeoutMain)
3.6 添加代理
为selenium爬虫添加代理,这个地方尤其需要注意的是,在选择代理时,尽量选择静态ip,才能提升爬取的稳定性。因为如果选择selenium来做爬虫,说明网站的反爬能力比较高(要不然直接上scrapy了),对网页之间的连贯性,cookies,用户状态等有较高的检测。如果使用动态匿名ip,每个ip的存活时间是很短的(1-3分钟)。
from selenium import webdriver # 静态IP:102.23.1.105:2005 # 阿布云动态IP:http://D37EPSERV96VT4W2:CERU56DAEB345HU90@proxy.abuyun.com:9020 PROXY = "proxy_host:proxy:port" options = webdriver.ChromeOptions() desired_capabilities = options.to_capabilities() desired_capabilities['proxy'] = { "httpProxy": PROXY, "ftpProxy": PROXY, "sslProxy": PROXY, "noProxy": None, "proxyType": "MANUAL", "class": "org.openqa.selenium.Proxy", "autodetect": False } driver = webdriver.Chrome(desired_capabilities = desired_capabilities)
3.7 浏览器选项设置
selenium一般打开的是不带扩展的纯净的浏览器,但是有时候我们想对浏览器进行一些设置,比如设置flash选项的默认值为全局始终允许,清除cookies,清除缓存之类。
想要实现这个目的,有一种思路,下面以chrome浏览器为例,在seleuim爬虫启动时,首先开一个窗口,在地址栏键入:chrome://settings/content或chrome://settings/privacy,然后由程序,像操作普通网页一样,进行设置,保存。

3.8 添加浏览器拓展应用
selenuim一般打开的是不带扩展的纯净的浏览器,但是有时候我们爬取数据时需要借助一些插件,比如解析类xpath helper,翻译类,获取额外信息(销量)等。那么我们怎么在启动chromedriver时,带上一些我们需要的插件呢?
下面以在chrome中加载Xpath Helper插件为例。
先下载插件,Xpath Helper下载地址http://download.csdn.net/download/gengliang123/9944202。下载的结果为一个以crx为后缀的文件---Xpath-Helper_v2.0.2.crx。
然后将插件路径填入代码中
# 添加xpath helper应用 from selenium import webdriver chrome_options = webdriver.ChromeOptions() # 设置好应用扩展 extension_path = 'D:/extension/XPath-Helper_v2.0.2.crx' chrome_options.add_extension(extension_path) # 启动浏览器,并设置好wait browser = webdriver.Chrome(chrome_options=chrome_options)
3.9 设置浏览器代理ip
有时候需要设置代理ip,不过网上能公开查到的免费ip一般都已经被限制访问了。
from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument("--proxy-server=http://182.84.144.122:3256") driver_path = r"chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options) driver.get('http://httpbin.org/ip') #可显示ip driver.get('https://www.baidu.com') #测试是否可用
3.10 chrome地址栏命令
在Chrome的浏览器地址栏中输入以下命令,就会返回相应的结果,但是这些命令包括查看内存状态,浏览器状态,网络状态,DNS服务器状态,插件缓存等等。但是需要注意的是这些命令会不停的变动,所以不一定好用。
about:version - 显示当前版本 about:memory - 显示本机浏览器内存使用状况 about:plugins - 显示已安装插件 about:histograms - 显示历史记录 about:dns - 显示DNS状态 about:cache - 显示缓存页面 about:gpu -是否有硬件加速 about:flags -开启一些插件 //使用后弹出这么些东西:“请小心,这些实验可能有风险”,不知会不会搞乱俺的配置啊! chrome://extensions/ - 查看已经安装的扩展
3.11 chrome实用参数
其他的一些关于Chrome的使用参数及简要的中文说明。
–user-data-dir=”[PATH]” 指定用户文件夹User Data路径,可以把书签这样的用户数据保存在系统分区以外的分区。 –disk-cache-dir=”[PATH]“ 指定缓存Cache路径 –disk-cache-size= 指定Cache大小,单位Byte –first run 重置到初始状态,第一次运行 –incognito 隐身模式启动 –disable-javascript 禁用Javascript –omnibox-popup-count=”num” 将地址栏弹出的提示菜单数量改为num个。我都改为15个了。 –user-agent=”xxxxxxxx” 修改HTTP请求头部的Agent字符串,可以通过about:version页面查看修改效果 –disable-plugins 禁止加载所有插件,可以增加速度。可以通过about:plugins页面查看效果 –disable-javascript 禁用JavaScript,如果觉得速度慢在加上这个 –disable-java 禁用java –start-maximized 启动就最大化 –no-sandbox 取消沙盒模式 –single-process 单进程运行 –process-per-tab 每个标签使用单独进程 –process-per-site 每个站点使用单独进程 –in-process-plugins 插件不启用单独进程 –disable-popup-blocking 禁用弹出拦截 –disable-plugins 禁用插件 –disable-images 禁用图像 –incognito 启动进入隐身模式 –enable-udd-profiles 启用账户切换菜单 –proxy-pac-url 使用pac代理 [via 1/2] –lang=zh-CN 设置语言为简体中文 –disk-cache-dir 自定义缓存目录 –disk-cache-size 自定义缓存最大值(单位byte) –media-cache-size 自定义多媒体缓存最大值(单位byte) –bookmark-menu 在工具 栏增加一个书签按钮 –enable-sync 启用书签同步 –single-process 单进程运行Google Chrome –start-maximized 启动Google Chrome就最大化 –disable-java 禁止Java –no-sandbox 非沙盒模式运行
常用
–single-process 单进程运行Google Chrome –start-maximized 启动Google Chrome就最大化 –disable-java 禁止Java –no-sandbox 非沙盒模式运行
3.12 参考
4 一些报错
记录一些错误,不过大部分其实都是模拟浏览器访问某些网站造成问题,导致会一直因为某些功能及验证不支持而报错,但是并不影响爬取结果(就是有时候因为反复加载及验证导致慢点),这些问题经常性找不到解决方法。套用我在查找某个问题时找到最后的某些解决方案的答复:此错误无害且不会阻止新的浏览上下文(即Chrome浏览器会话)的生成,因此,您可以放心地忽略该错误。
有些错误时触发时不触发,而且解决方案似乎也没啥用,过段时间又换另一种错误触发……不想深究了,就当记录吧。
4.1 驱动未下载或者版本不对、或者驱动未指定
selenium.common.exceptions.SessionNotCreatedException: Message: session not created
解决:参考https://blog.csdn.net/qq_41596734/article/details/109207171
这个很明显是驱动问题,下载对应版本的驱动,将其所在目录添加进环境变量,或者在写代码时指定executable_path=r'..\driver\chromedriver.exe'。由于存在反斜杠,路径需要使用r。参考上面2.1。
4.2 ‘WebElement‘ object is not subscriptable
原因:WebElement对象不可订阅,找不到元素
解决:参考https://blog.csdn.net/weixin_46777073/article/details/107316005
就是你使用find方法查找元素时没有在浏览器界面中找到对应元素而报错。可以写一个try...exception,当抛出错误时返回None。同时也需要考虑是否是因为浏览器没有加载完毕,可使用等待语句。
from selenium import webdriver from selenium.webdriver import ChromeOptions from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.common.keys import Keys import time import random import re # 某浏览器页面是否包含某元素,有则返回,超时返回None # seletor为选择器,如'#kw' def find_element(browser,seletor,timeout=10): try: WebDriverWait(browser, timeout).until(lambda the_driver: the_driver.find_element_by_css_selector(seletor), '') return browser.find_element_by_css_selector(seletor) except: print(seletor,'查找超时') return None
4.3 sys.meta_path is None, Python is likely shutting down
未找到原因,但算解决了吧。
这个报错出现在将browser.quit()写在了__del__函数中,怀疑是析构函数内部调用过程的缘故,也许是必须在析构前调用browser.quit()。所以我将browser.quit()另外定义在一个close()方法中手动调用,解决了问题。
browser定义在python类中作为成员变量,在__init__方法中初始化。虽然在__del__方法中查看type(browser)仍正常输出,但是不太清楚其析构函数运行前browser是否已经退出。
4.4 [报错但不影响结果]Mixed Content
Mixed Content: The page at 'https://www.so.com/s?q=888' was loaded over a secure connection, but contains a form that targets an insecure endpoint 'http://cx.shouji.360.cn/'. This endpoint should be made available over a secure connection.", source: https://www.so.com/s?q=888 (162)
混合内容是指http和https加载混合,这个是网站开发中会遇到的问题,但是爬虫的时候也看到了这个报错,虽然并未影响结果。主要原因是HTML页面是通过HTTPS加载的,但是其他资源文件(如图片,视频,样式表文件,脚本)是使用HTTP方式加载的。之所以称为混合内容,是因为在一个网页中同时使用了HTTP和HTTPS,而最初的请求方式为 HTTPS。
参考:
4.5 [报错但不影响结果] Failed to read descriptor from node connection
ERROR:device_event_log_impl.cc(214)] [20:49:24.630] USB: usb_device_handle_win.cc:1048 Failed to read descriptor from node connection: 连到系统上的设备没有发挥作用。 (0x1F)
这个错误出现在Windows10系统由于连接地USB设备无法正常工作而回调错误。此错误无害且不会阻止新的浏览上下文(即Chrome浏览器会话)的生成,因此,您可以放心地忽略该错误。
参考:
# 方法一
driver = webdriver.Chrome(resource_path("C:\\webdriver\\chromedriver.exe")) # to open the chromebrowser
driver.get("https://www.example.com")
# 方法二
webdriver.Chrome(executable_path=r'C:\webdriver\chromedriver.exe') # to open the chromebrowser
driver.get("https://web.whatsapp.com")
也有人说是因为使用上面的方法一造成的错误,更改为方法二就可以了……不过,我一直用的方法二,但是这个错误就还是会偶尔会出现。
参考:
4.6 [报错但不影响结果] Passthrough is not supported, GL is disabled
说是在设置无头浏览器(即不带窗口的浏览器)时会偶尔触发这个错误。添加--disable-software-rasterizer即可,之前触发的时候加这个没用,后面没触发这个错误也不知道有没有用。
4.7 [报错但不影响结果]ssl_client_socket_impl.cc:handshake failed
ERROR:ssl_client_socket_impl.cc(981)] handshake failed; returned -1, SSL error code 1, net_error -101
或许这个问题比较大,在进行一个简单的get的时候会反复报错,加载极慢,加载完之后标签上还是带着卷圈圈那个仍在加载的标志。但是这个错误在换个时间段后跑同一段代码就没有了……感觉还是不太懂。
说是添加以下参数即可,不过,当初触发错误的时候添加参数并没有用,后续不知道,可能是网站的拦截策略。
options.add_argument('--ignore-certificate-errors') #主要是该条
options.add_argument('--ignore-ssl-errors')
4.8 urllib3.exceptions.NewConnectionError: <urllib3.connection.HTTPConnection object at 0x0000020F201E15E0>: Failed to establish a new connection: [WinError 10061] 由于目标计算机积极拒绝,无法连接。
这个很明显是被识别爬虫了,被封ip了,需要配置代理ip
5、其他
本来只是想总结一下selenuim的应用,可以看到还有不少挺有趣的方法,只是比想象的花费了更多的时间,想要研究的东西也不少,但是有一些还需要写一些前端代码,但是暂时应该还不会深入。
记录一下计划写的应用代码及使用研究,但是既然是写在这里而不是默默放进备忘录,那显然实现是可能是久一点了,不一定会补:
-
验证码的识别
-
ActionChains更多的应用,如拖拽
-
HTML的解析方法
-
参考的一些,别人的链接:
参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号