在win10环境下配置spark和scala
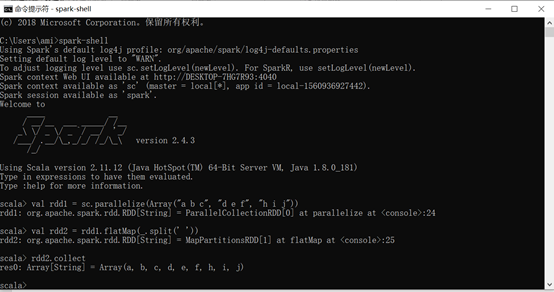
在这里配置的是在命令行下运行spark的环境用来学习,最后结果如下,可运行简单的代码。
0、jdk、scala和spark的版本问题
有关版本如官网所示,我想要强调的是spark至今并不支持jdk11,只支持到jdk8(jdk1.8).如果版本不对,你跑普通的代码都会报类、函数不存在的错误,我所下载的版本如上图所示spark2.4.3、scala2.11.12、java1.8。

1、 安装环境
在win10 64位系统中,我已经安装好jdk、scala,并设置好了环境变量JAVA_HOME、SCALA_HOME、PATH。此时在cmd里输入scala -version和java -version可以获得对应的版本。
2、 安装spark
从官网http://spark.apache.org/downloads.html下载对应版本的压缩包,解压在本地某个目录下,并设置好环境变量。
下载:

解压:

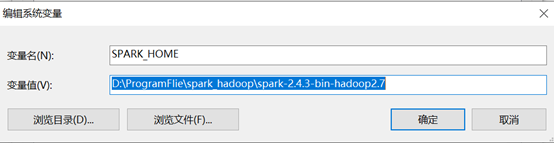
设置环境变量:
SPARK_HOME设置为你的解压后的文件目录、在path中添加%SPARK_HOME%\bin
3、 配置hadoop
同样是下载压缩包、解压、添加环境变量。需要注意hadoop对应的版本,下载官网http://hadoop.apache.org/releases.html
环境变量:
HADOOP_HOME设置为你的解压后的文件目录、在path中添加%HADOOP_HOME%\bin
4、 测试
之后就可以通过spark-shell进入交互spark命令行,进行简单的代码测试了,比如:
练习1:
//通过并行化生成rdd val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10)) //对rdd1里的每一个元素乘2然后排序 val rdd2 = rdd1.map(_ * 2).sortBy(x => x, true) //过滤出大于等于十的元素 val rdd3 = rdd2.filter(_ >= 10) //将元素以数组的方式在客户端显示 rdd3.collect
参考:
https://blog.csdn.net/songhaifengshuaige/article/details/79480491
当你深入了解,你就会发现世界如此广袤,而你对世界的了解则是如此浅薄,请永远保持谦卑的态度。

