编码方式的一些总结
先从python和js切入吧
一、基础编码
编码问题通常是字符串的编码问题,字符要以数字的形式保存传输。字符的表达形式包括byte(8bit)和str,它们之间就是编码问题。byte方便储存和传输,但str才是人常用的查
看操作的对象。
1、ASCII
最早的也是最基础的,但大小是以一byte(8bit)作为单位,也即是最大255.表达英文符号和标点是足够了,但是中文、日文等其他国家的文字就不能兼容了。
2、各国做了自己的编码方式
比如说中国的GB2312。
3、unicode
但是,第二种方法的编码方式各国有各国的标准挺混乱的。所以后来出现了unicode,它是两个字节的,兼容ASCII。
4、utf-8
但是,第三种方法对英文就不怎么友好了,明明一个字节能解决的事情,非得多占资源,所以出现了utf-8(1-6字节),英文通常1字节,中文3字节,随着复杂度增添字节,是现在常用的编码方式。
以上四种是基本的编码方式,满足字符储存和传输的需要,在python中一般使用decode(编码)和encode(解码)来进行bytes数组和字符串之间的转换,可以从代码结果看出解码获得的
bytes数组的格式一般是b'\x11'的格式。ASCII使用的则是ord()和chr()。
代码
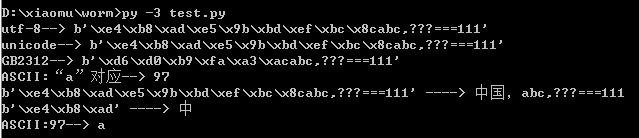
str="中国,abc,???===111" print('utf-8-->',str.encode('utf-8')) print('unicode-->',str.encode()) print('GB2312-->',str.encode('GB2312')) print('ASCII:“a”对应-->',ord('a')) b = b'\xe4\xb8\xad\xe5\x9b\xbd\xef\xbc\x8cabc,???===111' print(b,'---->',b.decode('utf-8')) a = b'\xe4\xb8\xad' print(a,'---->',a.decode('utf-8')) print('ASCII:97-->',chr(97))
结果截图
二、其他用途的编码
接触到前端开发工作,会发现多出了base64、uri编码等编码方式,这些编码方式有自己的用途,简单介绍一下用法,具体的实现就不介绍了。
1、uri/url编码
当我们使用url传输少量键值对时,如果值为“t&sss=ss”即显示在url中为‘xxx?xxx=t&sss=ss’则会解析出两个键值对,所以我们需要将这些特殊的字符进行一次编码后使得url安全。
url编码在js中有三种方式escape/unescape, encodeURI/decodeURI,encodeURIComponent/decodeURIComponent。除了安全符范围不同,以及escape编码中文是 ‘%uxxx’ 的格式外,三种编码方法得到对应的编码是一致的都是'%xx'。文件本身的编码方式会影响url编码结果,,比如是'utf-8'时,因为它们会经过一次utf-8编码后再进行url编码。三个方法的安全符如下:
escape(69个):*/@±._0-9a-zA-Z
encodeURI(82个):!#$&’()*+,/:;=?@-._~0-9a-zA-Z
encodeURIComponent(71个):!’()*-._~0-9a-zA-Z
代码
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <!--<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />--> <title></title> </head> <body> <script> var str = 'http://www.sss.com/api/搜索树/2.html?a=aaaa&b=t&sss=4aaa=1' document.write('原:'+str+'<br>'); document.write('escape: '+escape(str)+"<br>"); document.write('encodeURI: '+encodeURI(str)+"<br>"); document.write('Component: '+encodeURIComponent(str)+"<br>"); </script> </body> </html>
结果截图

而在python中,我没有找到解码escape'%uxxx'格式的方法,而其他url编码解码方法如下所示:
from urllib.parse import quote,unquote sss = 'http://www.sss.com/api/搜索树/2.html?a=aaaa&b=t&sss=4aaa=1' print(quote(sss)) ss = 'http%3A//www.sss.com/api/%u641C%u7D22%u6811/2.html%3Fa%3Daaaa%26b%3Dt%26sss%3D4aaa%3D1' print(unquote(ss))
总的来说url编码对于要传的值的部分可以进行encodeURIComponent编码,整体可以使用encodeURI。不过传值太复杂太隐私还是不要放在url了。
2、base64
简单来讲,Base64就是用总计64个字符去表示二进制数据的:'A-Z','a-z','0-9','+','/'。
复杂来讲,我不想讲了。
base64的用法有以下几种:
1.像url编码一样起一定过滤特殊字符的作用,将非ASCII字符转换成ASCII字符
2.编码起一定“加密”的作用,其中即使是英文字符也会产生变化
3.图片和特殊格式图片的渲染(通过canvas)
在js中进行base64编码解码使用的是window.btoa()/window.atob(),编码结果长度一般是4的倍数,不足的会使用符号'='补上
代码:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title></title> </head> <body> <script> document.write(window.btoa("test")+'<br>');//"dGVzdA==" document.write(window.atob("dGVzdA==")+'<br>');//"test" </script> </body> </html>
在python中有一个base64的包
代码:
import base64 encodestr = base64.b64encode('abcr34r344r'.encode('utf-8'))#结果是b'',是byte类型的数据 print(str(encodestr,'utf-8'))
3、8421 BCD
bcd码用来打印二进制。把任意一个字符变成2个可见的十六进制字符(0-9a-z 或 0-9A-z)。相比于Base64的隐蔽性,BCD码的优势在于其可读性好。
4、utf-8等
讲到起加密作用的编码,突然记起之前有一个操作,utf-8的bytes数组是按十六进制显示的数字,可以规定一个转换规则,在服务器端对数组进行了转换,然后到浏览器端js进行重新转换生成正确的字符。
参考:
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431664106267f12e9bef7ee14cf6a8776a479bdec9b9000
https://blog.csdn.net/chy555chy/article/details/84646591
https://www.cnblogs.com/accordion/p/4178289.html
https://blog.csdn.net/rainharder/article/details/26342919
https://blog.csdn.net/unopenmycode/article/details/78835545

