


kafka客户端源码
kafka开发语言是scala+java,gradle管理,包含的子工程有:
clients : 实现了consumer、producer、admin三种客户端以及服务器端和各客户端
consumer:消费者客户端
producer:生产者客户端
admin:运维管理客户端
consumer客户端
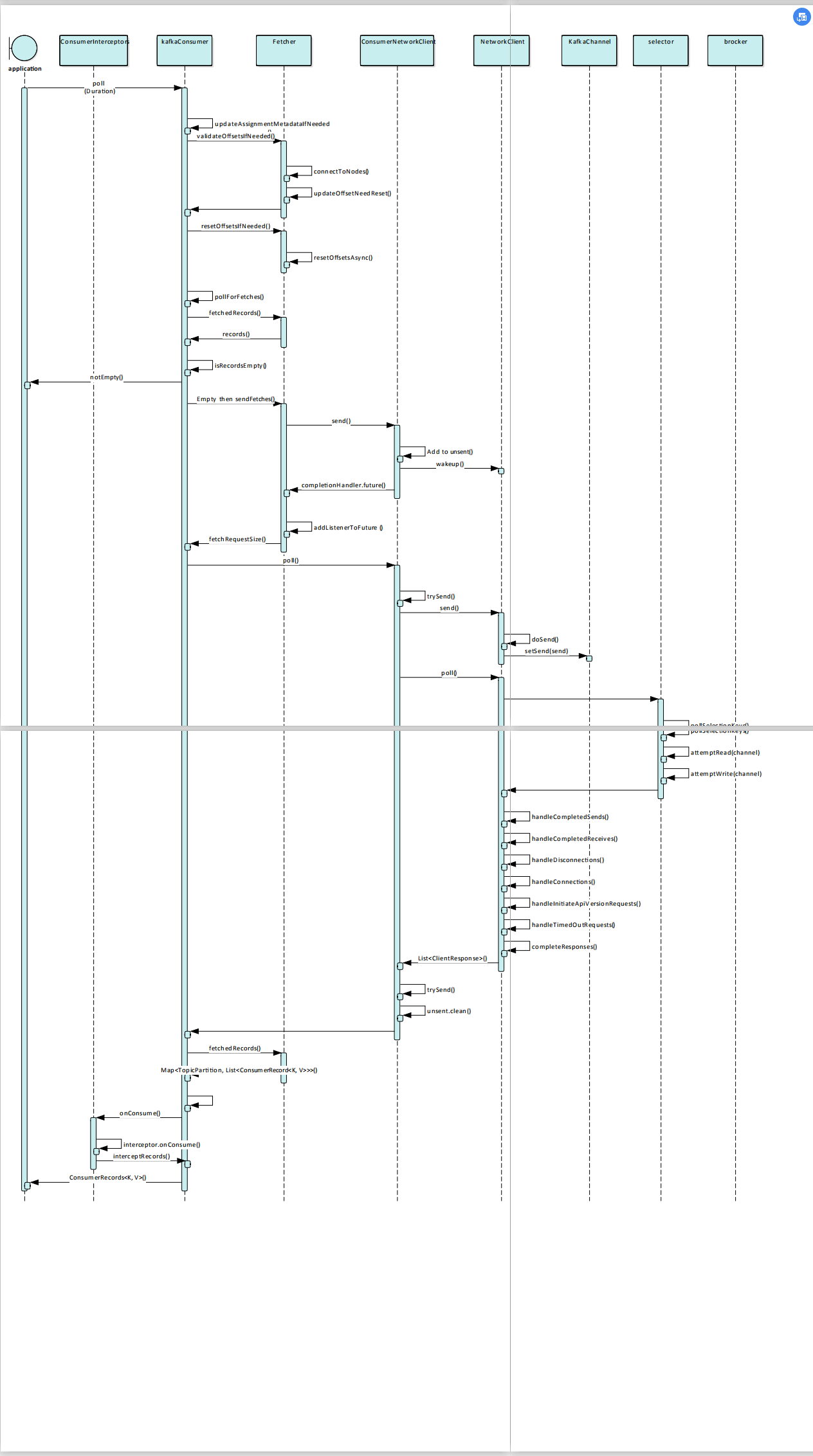
consumer的实现类:KafkaConsumer
创建consumer客户端:
生成rebalance配置:
设置
生成groupId:获取用户配置的 group.id
groupInstanceId:获取用户配置的group.instance.id,用户通过该属性为客户端指定固定的id,如果要设置该属性,必须是非空字符串,broker会将设置了id的客户端视为静态成员,对于静态成员,可以通过设置较大session超时时间避免因瞬时不可用导致的rebalance.
max.poll.interval.ms:客户端两次poll调用之间的最大时间间隔,如果间隔超过设置,broker会认为该客户端出问题
并且触发rebalance,用来将该客户端的partition分配给别的消费者。
rebalance.timeout.ms:客户端重新加入group的最大时间限制,如果发生了rebalance,所有客户端需要在时限内刷新
所有pending状态数据并提交offset,如果超时,客户端将被移出group,导致客户端提交offset失败。
session.timeout.ms:在使用kafka的group管理能力时,用来检测客户端失效,客户端发送周期性心跳给broker表明自己正常存活,如果在session超时前broker没有收到心跳消息,broker会将
超时客户端移出分组并启动一次rebalance.这个超时时间必须介于group.min.session.timeout.ms和group.max.session.timeout.ms之间
heartbeat.interval.ms:使用kafka group管理能力时指定客户协调器期望收到心跳的最大时间间隔,心跳用来确保客户端session处于激活状态,并且在有客户端离开或加入group时协助rebalancing.
enable.auto.commit:如果设置为true,consumer的offset会在后台定期被提交到broker
auto.commit.interval.ms:enable.auto.commit设置为true时起作用,consumer offset自动提交的频率,时间单位是ms
设置自定义客户端过滤器:
interceptor.classes:可以在客户端配置过滤器,所有客户端设置的自定义过滤器必须实现接口org.apache.kafka.clients.consumer.ConsumerInterceptor
设置自定义key、value解码实现:
key.deserializer:key解码器,实现org.apache.kafka.common.serialization.Deserializer接口
value.deserializer:value解码器,实现org.apache.kafka.common.serialization.Deserializer接口
bootstrap.servers:设置broker节点地址列表
client.dns.lookup:控制客户端DNS访问方式,如果设置为use_all_dns_ips,当DNS返回多个ip时,客户端会尝试和其中每一个ip,直到找到可用节点或者所有节点都不可用。
partition.assignment.strategy: class列表,根据优先级排序,在group管理功能开启时,客户端用来分配partition占有关系,通过实现org.apache.kafka.clients.consumer.ConsumerPartitionAssignor接口
你可以提供自定义的分配策略。
生成clientId
如果用户配置了client.id,使用用户指定的,否则检查groupId有没有设置,如果设置则使用groupId,groupInstanceId,和一个自增序列生成的数字组合成clientId,如果没有设置groupId,则直接使用自增序列生成一个编号:
private static String buildClientId(String configuredClientId, GroupRebalanceConfig rebalanceConfig) {
if (!configuredClientId.isEmpty())
return configuredClientId;
if (rebalanceConfig.groupId != null && !rebalanceConfig.groupId.isEmpty())
return "consumer-" + rebalanceConfig.groupId + "-" + rebalanceConfig.groupInstanceId.orElseGet(() ->
CONSUMER_CLIENT_ID_SEQUENCE.getAndIncrement() + "");
return "consumer-" + CONSUMER_CLIENT_ID_SEQUENCE.getAndIncrement();
}
创建ConsumerMetadata,维护着KafkaConsumer后续消费消息要使用的基本信息。
创建NetworkClient,包括了最核心的Selector,用来通信
创建ConsumerNetworkClient,以NetworkClient作为参数。
订阅topic
subscribe(Collection<String> topics)接口提供订阅能力,该接口实现默认提供一个空的ConsumerRebalanceListener,用来处理新增分区或者分区
撤销。
1. 清理没有分配分区的topic,登记所有订阅的topic
2. 更新维护一个SubscriptionState,其中包括订阅的topic列表/topic正则、ConsumerRebalanceListener、PartitionStates
3. 更新topic版本
拉取消息(poll(timeout))
在KafkaConsumer.kafkaConsumerMetrics中记录开始时间点。
调用poll方法时会生成一个计时器Timer,记录了从Timer生成到当前经历的ms数,判断是否超时是通过比较这个ms数和用户调用poll方法时传入的毫秒数做比较
在Timer超时前,会持续调用pollForFetches(timer),直到pollForFetches有数据返回或者Timer超时。
pollForFetches:
每次调用该方法都有超时设置,如果用户 设置了groupId,则使用上面的Timer剩余时间作为本次超时时间,否则使用客户端coordinator计算:
1. 用户设置了自动提交offset,则取下次自动提交offset时间间隔、下次心跳时间间隔、Timer剩余时间最小值
2. 用户关闭了自动提交offset,则取下个心跳发送时间到当前时间间隔和Timmer剩余时间最小值
接下来先尝试Fetcher.fetchedRecords(),获取已经拿到的数据
如果获取到数据直接返回records
否则调用Fetcher.sendFetches()发送fetch请求
调用ConsumerNetworkClient.poll拉取消息,这个是真正读取server端返回
调用返回数据Fetcher.fetchedRecords()
Fetcher.fetchedRecords():
返回结果:Map<TopicPartition, List<ConsumerRecord<K, V>>>
如果拿到消息没有到达poll最大限制,则继续拉取
记录nextInLineFetch作为下个循环将读取的fetch看,如果nextInLineFetch为null或者已被消费,则从completedFetches里面取出最上面一个CompletedFetch作为nextInLineFetch。
Fetcher.sendFetches():
ConsumerNetworkClient.send(Node, FetchRequest.Builder)
ConsumerNetworkClient会将本次fetch请求放入unsent,并唤醒client处理请求发送
ConsumerNetworkClient.poll:
client.poll(pollTimer, () -> {
// since a fetch might be completed by the background thread, we need this poll condition
// to ensure that we do not block unnecessarily in poll()
return !fetcher.hasAvailableFetches();
});
/**
* Poll for any network IO.
* @param timer Timer bounding how long this method can block
* @param pollCondition Nullable blocking condition
* @param disableWakeup If TRUE disable triggering wake-ups
*/
public void poll(Timer timer, PollCondition pollCondition, boolean disableWakeup) {
// there may be handlers which need to be invoked if we woke up the previous call to poll
firePendingCompletedRequests();
lock.lock();
try {
// Handle async disconnects prior to attempting any sends
handlePendingDisconnects();
// send all the requests we can send now
long pollDelayMs = trySend(timer.currentTimeMs());
// check whether the poll is still needed by the caller. Note that if the expected completion
// condition becomes satisfied after the call to shouldBlock() (because of a fired completion
// handler), the client will be woken up.
if (pendingCompletion.isEmpty() && (pollCondition == null || pollCondition.shouldBlock())) {
// if there are no requests in flight, do not block longer than the retry backoff
long pollTimeout = Math.min(timer.remainingMs(), pollDelayMs);
if (client.inFlightRequestCount() == 0)
pollTimeout = Math.min(pollTimeout, retryBackoffMs);
client.poll(pollTimeout, timer.currentTimeMs());
} else {
client.poll(0, timer.currentTimeMs());
}
timer.update();
// handle any disconnects by failing the active requests. note that disconnects must
// be checked immediately following poll since any subsequent call to client.ready()
// will reset the disconnect status
checkDisconnects(timer.currentTimeMs());
if (!disableWakeup) {
// trigger wakeups after checking for disconnects so that the callbacks will be ready
// to be fired on the next call to poll()
maybeTriggerWakeup();
}
// throw InterruptException if this thread is interrupted
maybeThrowInterruptException();
// try again to send requests since buffer space may have been
// cleared or a connect finished in the poll
trySend(timer.currentTimeMs());
// fail requests that couldn't be sent if they have expired
failExpiredRequests(timer.currentTimeMs());
// clean unsent requests collection to keep the map from growing indefinitely
unsent.clean();
} finally {
lock.unlock();
}
// called without the lock to avoid deadlock potential if handlers need to acquire locks
firePendingCompletedRequests();
metadata.maybeThrowAnyException();
}
通过调用trySend将unsent中的待发送请求发送出去。
long trySend(long now) {
long pollDelayMs = maxPollTimeoutMs;
// send any requests that can be sent now
for (Node node : unsent.nodes()) {
Iterator<ClientRequest> iterator = unsent.requestIterator(node);
if (iterator.hasNext())
pollDelayMs = Math.min(pollDelayMs, client.pollDelayMs(node, now));
while (iterator.hasNext()) {
ClientRequest request = iterator.next();
if (client.ready(node, now)) {
client.send(request, now);
iterator.remove();
} else {
// try next node when current node is not ready
break;
}
}
}
return pollDelayMs;
}
requestIterator(node)找到对应一个Node上的所有请求。
通过client.send(request, now);将请求发送出去。该方法是NetworkClient的方法,send方法通过doSend方法最终调用selector.send(send),将请求通过socket发送到broker.
send(send)方法是org.apache.kafka.common.network.Selector的方法,,实际上是放到channel区,并将selector设置为write等待写入:
/**
* Queue the given request for sending in the subsequent {@link #poll(long)} calls
* @param send The request to send
*/
public void send(Send send) {
String connectionId = send.destination();
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
if (closingChannels.containsKey(connectionId)) {
// ensure notification via `disconnected`, leave channel in the state in which closing was triggered
this.failedSends.add(connectionId);
} else {
try {
channel.setSend(send);
} catch (Exception e) {
// update the state for consistency, the channel will be discarded after `close`
channel.state(ChannelState.FAILED_SEND);
// ensure notification via `disconnected` when `failedSends` are processed in the next poll
this.failedSends.add(connectionId);
close(channel, CloseMode.DISCARD_NO_NOTIFY);
if (!(e instanceof CancelledKeyException)) {
log.error("Unexpected exception during send, closing connection {} and rethrowing exception {}",
connectionId, e);
throw e;
}
}
}
}
调完trySend后开始调用client.poll,实际调用Selector.poll(long timeout)拉取收到的数据:
if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) {
Set<SelectionKey> readyKeys = this.nioSelector.selectedKeys();
// Poll from channels that have buffered data (but nothing more from the underlying socket)
if (dataInBuffers) {
keysWithBufferedRead.removeAll(readyKeys); //so no channel gets polled twice
Set<SelectionKey> toPoll = keysWithBufferedRead;
keysWithBufferedRead = new HashSet<>(); //poll() calls will repopulate if needed
pollSelectionKeys(toPoll, false, endSelect);
}
// Poll from channels where the underlying socket has more data
pollSelectionKeys(readyKeys, false, endSelect);
// Clear all selected keys so that they are included in the ready count for the next select
readyKeys.clear();
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
immediatelyConnectedKeys.clear();
} else {
madeReadProgressLastPoll = true; //no work is also "progress"
}
Selector.attemptWrite(key, channel, nowNanos); -> Selector.write(channel) -> KafkaChannel.write() -> RecordsSend/MultiRecordsSend/ByteBufferSend.writeTo(GatheringByteChannel channel)
将消息发送出去
