glidedsky-爬虫-字体反爬-2
直接看题目。

这里看起来和之前的字体反爬不太一样,但是道理是相似的,只要找到映射关系,就可以得到对应的数字了,先看一下源码。


数字显示那块的源码是这样的,用了中文,字体的文件和之前的一样,放在了style这里,先用之前的方法下载下来用FontCreator看看。

这啥也看不出来,直接看xml文件吧。
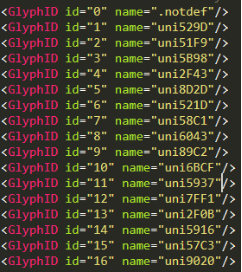
xml文件也和之前的不一样了,不只10个id,看name这里,像是Unicode编码,而源码里面显示的就是中文,那先把’ni’去掉看一下解码,第一个u529D解码出来是’劝’字。
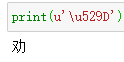
可以知道这里字体的映射逻辑是用源码中的中文转为unicode编码,映射到对应的id,那就是显示出来的数字了,这里要注意xml文件里面有些Unicode编码是康熙字体的编码,看上去是同一个字,但实际上是两个不一样的编码,所以需要加异常处理,当这个字在xml文件里面找不到映射的时候,要换成康熙字体去找映射的id。
kangxi={'一': '⼀','乙': '⼄','二': '⼆','人': '⼈','儿': '⾒','入': '⼊','八': '⼋','几': '⺇','刀': '⼑','力': '⼒','匕': '⼔',
'十': '⼗','卜': '⼘','厂': '⺁','又': '⼜','口': '⼞','土': '⼟','士': '⼠','大': '⼤','女': '⼥','子': '⼦','寸': '⼨',
'小': '⺌','尸': '⼫','山': '⼭','工': '⼯','己': '⼰','干': '⼲','广': '⼴','弓': '⼸','心': '⼼','戈': '⼽','手': '⼿',
'支': '⽀','文': '⽂','斗': '⽃','斤': '⽄','方': '⽅','无': '⽆','日': '⽇','曰': '⽈','月': '⺝','木': '⽊','欠': '⽋',
'止': '⽌','歹': '⽍','毋': '⽏','比': '⽐','毛': '⽑','氏': '⽒','气': '⽓','水': '⽔','火': '⽕','爪': '⽖','父': '⽗',
'片': '⽚','牙': '⽛','牛': '⽜','犬': '⽝','玄': '⽞','玉': '⽟','瓜': '⽠','瓦': '⽡','甘': '⽢','生': '⽣','用': '⽤',
'田': '⽥','白': '⽩','皮': '⽪','皿': '⽫','目': '⽬','矛': '⽭','矢': '⽮','石': '⽯','示': '⽰','禾': '⽲','穴': '⽳',
'立': '⽴','竹': '⽵','米': '⽶','缶': '⽸','网': '⽹','羊': '⽺','羽': '⽻','老': '⽼','而': '⽽','耳': '⽿','肉': '⾁',
'臣': '⾂','自': '⾃','至': '⾄','舌': '⾆','舟': '⾈','艮': '⾉','色': '⾊','虫': '⾍','血': '⾎','行': '⾏','衣': '⾐',
'角': '⻆','言': '⾔','谷': '⾕','豆': '⾖','赤': '⾚','走': '⾛','足': '⾜','身': '⾝','车': '⻋','辛': '⾟','辰': '⾠',
'邑': '⾢','酉': '⾣','采': '⾤','里': '⾥','金': '⾦','长': '⻓','门': '⻔','阜': '⾩','隶': '⾪','雨': '⻗','青': '⻘',
'非': '⾮','面': '⾯','革': '⾰','韭': '⾲','音': '⾳','页': '⻚','风': '⻛','飞': '⻜','食': '⻝','首': '⾸','香': '⾹',
'马': '⻢','骨': '⻣','高': '⾼','鬼': '⻤','鱼': '⻥','鸟': '⻦','卤': '⻧','鹿': '⿅','麻': '⿇','黍': '⿉','黑': '⿊',
'鼎': '⿍','鼓': '⿎','鼠': '⿏','鼻': '⿐','齿': '⻮','龙': '⻰','夕': '⼣','兀': '⺎', '尣': '⺏','尢': '⺐','𡯂': '⺑',
'巳': '⺒','幺': '⺓','旡': '⺛','母': '⺟','民': '⺠','冈': '⺱','芈': '⺸','虎': '⻁','西': '⻄','见': '⻅','𧢲': '⻇',
'贝': '⻉','镸': '⻒','韦': '⻙','𩠐': '⻡','麦': '⻨','黄': '⻩','齐': '⻬','竜': '⻯','龟': '⻳','臼': '⾅','户': '⼾',
'巾': '⼱'}
上面是常用的康熙字体,键是平时使用的中文,值是康熙字体。
for i in range(len(chinese)): unicode = chinese[i].encode('unicode_escape') name = 'uni' + str(unicode)[-5:-1].upper() try: num = font.getGlyphID(name) - 1 except: unicode = kangxi[chinese[i]].encode('unicode_escape') name = 'uni' + str(unicode)[-5:-1].upper() num = font.getGlyphID(name) - 1
这里chinese是<div class="col-md-1">下的几个中文,因为中文编码成Unicode再转字符串是这样的"b'\\\\u529d'",只要’529d’这几个,再将字母大写,加上前面的’uni’就得到了xml里面的name了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号