glidedsky-爬虫-雪碧图-2
先来看一下题目。
进入到待爬取网站看是这样的。

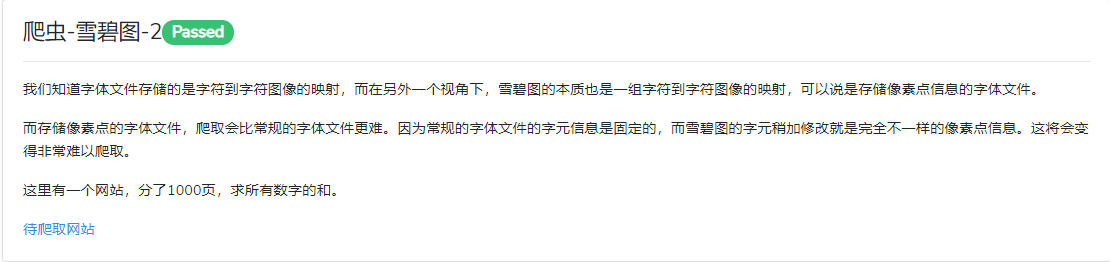
是一些形状不同的图片数字,因为做了雪碧图1,所以考虑能不能用模板匹配的方式来解决问题。打开开发者选项,里面是这样子的一张图片。

根据经验,在网页源代码的<style></style>里面会有每个数字的样式属性,这里需要的是x,y,w,h,这样就可以将对应的数字截取下来。
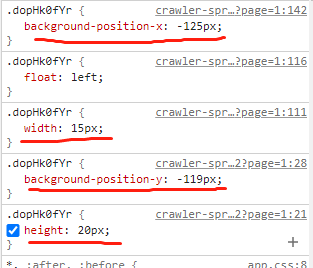
 截取下来的图片是这样的。那么我们需要做的就是识别出这个数字是0。雪碧图1是用的模板匹配的方法来识别数字,但是在这里面的模板图的数字都没有规律,而且每次请求都会不一样,所以要换另一个方法。最近在接触深度学习的知识,所以准备用深度学习的方法来对数字进行识别。这里的数字识别的场景和手写数字识别比较像,所以准备用手写数字识别的数据集训练一个模型来看一下识别效果,如果效果可以的话就不用自己打标签了。
截取下来的图片是这样的。那么我们需要做的就是识别出这个数字是0。雪碧图1是用的模板匹配的方法来识别数字,但是在这里面的模板图的数字都没有规律,而且每次请求都会不一样,所以要换另一个方法。最近在接触深度学习的知识,所以准备用深度学习的方法来对数字进行识别。这里的数字识别的场景和手写数字识别比较像,所以准备用手写数字识别的数据集训练一个模型来看一下识别效果,如果效果可以的话就不用自己打标签了。

 左图是输入的图片,右图是识别的结果,可能是因为数据分布不一样,所以效果不好。还是选择自己训练一个模型。
左图是输入的图片,右图是识别的结果,可能是因为数据分布不一样,所以效果不好。还是选择自己训练一个模型。
首先是下载数据,显示的数据是直接遍历1-1000页,将上面显示的图片都下载下来,大概遍历了5次,总共有十几万的数字;然后是最头痛一步了,数据标注,我这里是使用了百度的ocr识别进行初步的分类,但是一天只有5万次的识别次数,而且分类结果也没有特别准确,后面又人工看了一遍,最后整理出9万多的数据,从0到9每个数字都有9千多张;接着是模型训练,这里选择的是lenet5的模型结构,使用pytorch,训练的时候在测试集上的准确率是98.41%;最后使用模型对每一个数字图片进行识别。
import torch import torch.nn as nn # 模型结构 class LeNet5(nn.Module): def __init__(self, n_classes): super(LeNet5, self).__init__() self.feature_extractor = nn.Sequential( nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5, stride=1), nn.ReLU(inplace=True), nn.AvgPool2d(kernel_size=2), nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1), nn.ReLU(inplace=True), nn.AvgPool2d(kernel_size=2), nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1) ) self.classifier = nn.Sequential( nn.Linear(in_features=120, out_features=84), nn.ReLU(inplace=True), nn.Linear(in_features=84, out_features=n_classes) ) def forward(self, x): x = self.feature_extractor(x) x = torch.flatten(x, 1) logits = self.classifier(x) return logits
数据预处理,将图像调整大小为32×32的大小,最后进行归一化。
import cv2 import numpy as np def process(img, img_size=32): # 输入模型的图像是32×32的大小 height, width = img.shape[:2] if height > width: scale = img_size / height resize_height = img_size resize_width = int(width * scale) else: scale = img_size / width resize_height = int(height * scale) resize_width = img_size img = cv2.resize(img, (resize_width, resize_height)) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) new_img = np.zeros((img_size, img_size, 3)) new_img += 255 new_img[0:resize_height, 0:resize_width] = img new_img = new_img.astype(np.float32) / 255 return new_img
模型调用的方法
import numpy as np from torchvision import transforms # LeNet5()是上面的模型结构 model = LeNet5(10) model.load_state_dict(torch.load('模型的路径')) transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),]) # pic为数字图片,process是上面数据预处理的代码 img = process(pic.astype(np.uint8)) with torch.no_grad(): img = transform(img).unsqueeze(0) output1 = model(img) pred1 = output1.data.max(1, keepdim=True)[1] num = int(pred1[0][0]) # num为最后识别出来的结果
先对第一页识别试一下效果。

每个数字都识别出来了,然后开始遍历每一页,最后结果提交上去,没过。。。好吧,模型泛化性还是不行,因为每两页的模板图片是一样的,而且后面的数字也可能使用了相同的样式,所以在这个数据集里面应该有很多数字是重复的,模型还是过拟合了。但是标数据实在是太麻烦了,而且模型也有一定的识别效果,机子不行,不想再训练了。所以我选择对一个页面请求多次,然后取每个数字出现最多的那一次作为结果,最后得到了正确答案。
训练的模型,链接:https://pan.baidu.com/s/1hiIUUJ0CxUCt_gmCxP91Kw,提取码:zarw
整理的数据集(可能还不是很干净),链接:https://pan.baidu.com/s/19VCeh73pwSB2hk4EtRHX4A 提取码:5dft

 浙公网安备 33010602011771号
浙公网安备 33010602011771号