SQL Server 索引 聚集索引、非聚集索引、堆
一、存储结构
1、平衡树(B-树)
平衡树或B- 树仅仅是提供了一种以一致且相对低成本的方式查找特定信息的方法,其名称中的“平衡”是自说明的。平衡树是自平衡的,这意味着每次树进行分支时,都有接近一半的数据在一边,而另一半数据在另一边。树命 名的由来是因为,如果绘制该接口,再倒过来,发现很像一棵树。
平衡树始于根节点,如果有少量的数据,这个根节点可以直接指向数据的实际位置。
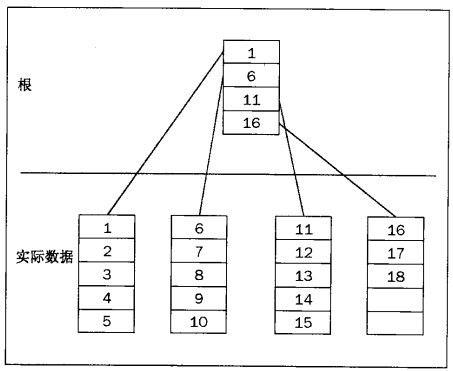
所有的数据,都是根节点开始,直到找到以小于查找值得值开始的最后一页。然后获得指向该节点的一个指针并且浏览它。直到找到想要的行。
当数据很多时,根节点指向中间的节点(非顶级节点)。非页级节点是位于根节点和说明数据的物理存储位置的节点之间的节点。
非叶级节点可以指向其他非叶级节点或叶节点。叶级节点是从中可以获取实际物理数据的引用的节点。

从上图可以看出,查找开始于根节点,然后移动到以等于或小于查找值的最高值开始的同时也在下一级节点中的节点。然后重复这个过程-查找具有等于或者小于查找值的最高起始值节点。继续沿着树一级一级往下,直到二级节点-从而知道数据的物理位置。
2、页拆分
所有这些页在读取方面工作良好-但在插入时会有点麻烦。前面提到B-树结构,每次遇到树中的分支时,因为每一边都大约有一半的数据,所以B-树是平衡的。另外,由于添加新数据到树的方法一般可避免出现不平衡,所以B-树有时被认为是自平衡的。
通过将数据添加到树上,节点最终将变满,并且将需要拆分。因为在 SQL Server中,一个节点相当于一个页-所以这被称为页拆分。如图所示:
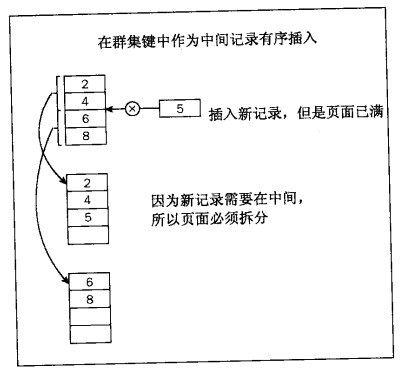
当发生页拆分时,数据自动地四处移动以保持平衡,数据的前半部分保留在旧页上,而数据的剩余部分添加到新页 - 这样就形成了对半拆分,使得树保持平衡。
如果考虑下这个拆分过程,将认识到它在拆分时增加了大量的系统开销。不只是插入一页还将进行下列操作:
- 创建新页
- 将行从现有数据页移动到新页上
- 将新行添加到其中一页上
- 在父节点中添加另一个记录项
注意最后一条,如果在父节点中添加记录时,父页也满了引起拆分,整个过程会重新开始。甚至会影响到根节点。并且,如果根节点拆分,那么实际最终会创建两个额外的页,因此只能有一个根节点,所以之前的根节点的页被拆分成两个页,而且称为树的新中间级别节点。然后创建全新的根节点,并且将有两个记录项,指向刚刚由根节点分拆出来的两个中间节点。
由上面的原理可以知道,当向树的上层移动时,页拆分的数量变得越来越少。因为下级的一个页拆分对上级来说是一条记录。
虽然SQL Server有许多不同类型的索引,但是所有这些索引都以某种方式利用这种平衡树方法。事实上由于平衡树的灵活特性,所有索引在结构上都非常类似,不过他们实际上还有一点点区别,并且这些区别会对系统的性能产生影响。
3、索引类型和索引导航
尽管表面上在SQL Server中有两种索引结构(聚集索引和非聚集索引),但就内部而言,有3种不同的索引类型。
- 聚集索引
- 非聚集索引,其中非聚集索引又包括以下两种:
- 堆上的非聚集索引
- 聚集表上的非聚集索引
物理数据的存储方式在聚集索引和非聚集索引中是不同的。而SQL Server遍历平衡树以到达末端数据的方式在所有3种索引类型中也是不同的。
所有的SQL Server索引都有叶级和非叶级页,叶级是保存标识记录的“键”的级别,非叶级是叶级的引导者。
索引在聚集表(如果表有聚集索引)或者堆(用于没有聚集索引的表)上创建。
(1)、聚集表
聚集表是在其上具有聚集索引的任意表。但是它们对于表而言意味着以指定顺序物理存储数据。通过使用聚集索引键唯一地标志独立的行-聚集键即定义聚集索引的列。
如果聚集索引不是唯一的,那将怎样?如果索引不是唯一索引,那么聚集索引如何用于唯一地标志一行?SQL Server会在内部添加一个后缀到键上,以保证行具有唯一的标识符。
(2)、堆
堆是在其上没有聚集索引的一个表。在这种情况下,基于行的区段、页以及行偏移量(偏移页顶部的位置)的组合创建唯一的标识符,或者称为行ID(RID)。如果没有可用的聚集键(没有聚集索引),那么RID是唯一必要的内容。堆表并不是B树结构。
创建聚集索引 CREATE CLUSTERED INDEX index_id ON dbo.TrackLog(ID);
删除聚集索引 DROP INDEX dbo.TrackLog.index_id
清空数据库缓存 DBCC DROPCLEANBUFFERS
开启IO统计 SET STATISTICS IO ON

 浙公网安备 33010602011771号
浙公网安备 33010602011771号