Mysql
1.版本介绍和选择
Oracle MySQL 8.0 MariaDB PerconaDB 主流版本 mysql 5.6 5.6.36 5.38 5.6.40 mysql 5.7 5.7.18 5.7.20 5.7.22 企业版本选择: 6-12月之间的GA
2.安装
3.体系结构
3.1 MySQL C/S结构 两种链接方法: TCP/IP (远程,本地),SOCKET(本地) mysql -uroot -poldboy123 -h 10.0.0.200 -P3306 mysql -uroot -poldboy123 -S /tmp/mysql.sock 3.2 MySQL实例 实例=mysqld+内存结构 MySQL实例======> mysqld(董事长)---->master thread(经理)---->N Thread(员工) ------>内存结构(办公区) 3.3 mysqld三层结构 连接层 1.提供连接协议(TCP ,Socket) 2.用户验证 3.提供专用链接线程 SQL层 1.接收上层的命令 2.语法检测 3.语义(SQL类型),权限 SQL类型:DDL数据定义语言 DCL数据控制语言 DML数据操作语言 DQL数据查询 4.专用解析器解析SQL,解析成多种执行计划 5.优化器:帮我们选择一个代价最低的执行计划(cpu,IO,MEM) 6.执行器:按照优化器的选择,执行SQL语句,得出获取数据方法 7.查询缓存:默认是关闭的. 一般会使用redis产品替代 Tair 8.记录日志:二进制日志 存储引擎层 按照SQL层结论,找相应数据,结构化成表的形式 3.4 MySQL的逻辑结构 库(schema):存储表的地方(库名,属性) 表(Table):二维表 元数据 表名字 表的属性(表的大小,权限,存储引擎,字符集等) 列:列名字,列属性(数据类型,约束,其他定义) 记录:数据行
4.SQL
4.1 SQL 种类 DDL数据定义语言 DCL数据控制语言 DML数据操作语言 DQL数据查询语言 4.2 SQL语句的操作对象 库 表 4.3 不同分类语句作用 DDL : 库 CREATE DATABASE DROP DATABASE ALTER DATABSE SQL语句规范第一条: CREATE DATABASE oldboy CHARSET utf8mb4; 1.关键字大写(非必须),字面量小写(必须) 2.库名字,只能是小写,不能有数字开头,不能是预留关键字 3.库名字必须和业务名有关,例如his_user; 4.必须加字符集. 表 CREATE TABLE DROP TABLE ALTER TABLE CREATE TABLE t1 ( id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '用户ID', sname VARCHAR(20) NOT NULL COMMENT '用户姓名', gender ENUM('f','m','u') NOT NULL DEFAULT 'u' COMMENT '用户性别', telnum CHAR(11) NOT NULL UNIQUE COMMENT '手机号', tmdate DATETIME NOT NULL DEFAULT NOW() COMMENT '录入时间' )ENGINE INNODB CHARSET utf8mb4; SQL语句规范第二条: 1.关键字大写(非必须),字面量小写(必须) 2.表名必须小写,不能有数字开头,不能是预留关键字 3.表名字必须和业务名有关 4.必须加存储引擎和字符集 5.适合的数据类型 6.必须要有主键 7.尽量非空选项 8.字段唯一性 9.必须加注释 10.避免使用外键 11.建立合理的索引 DCL: grant revoke lock DML : insert update delete SQL语句规范第三条: 1.insert语句按批量插入数据 2.update必须加where条件 3.delete尽量替换为update 4.如果有清空全表需求,不要用delete,推荐使用truncate DQL : select show SQL语句规范第四条: 1. select语句避免使用 select * from t1; ----> select id,name from t1; 2. select语句尽量加等值的where条件.例如 select * from t1 where id=20; 3. select 语句对于范围查询,例如 ;select * from t1 where id>200; 尽量添加limit或者 id>200 and id<300 union all id>300 and id<400 4. select 的where 条件 不要使用 <> like '%name' not in not exist 5. 不要出现3表以上的表连接,避免子查询 6. where条件中不要出现函数操作.
5.mysql配置与多实例
5.1 初始化数据: /usr/local/mysql/bin/mysqld --initialize-insecure --user=mysql --datadir=/opt/mysql/data --basedir=/opt/mysql 5.2 配置文件 vim /etc/my.cnf [mysqld] basedir=/usr/local/mysql datadir=/usr/local/mysql/mydata socket=/tmp/mysql.sock log_error=/var/log/mysql.log user=mysql port=6606 [mysql] socket=/tmp/mysql.sock 作用: 1.影响服务端的启动 标签: [mysqld] [mysqld_safe] [server] ... [mysqld] basedir=/opt/mysql datadir=/opt/mysql/data user=mysql socket=/tmp/mysql.sock port=3306 server_id=6 2.影响客户端连接 标签: [client] [mysql] [mysqldump] .... [mysql] socket=/tmp/mysql.sock ======================= 5.3 多实例(3307 3308 3309) 5.3.1 创建相关目录 mkdir -p /data/330{7..9}/data 5.3.2 创建配置文件 cat>> /data/3307/my.cnf<<EOF [mysqld] basedir=/opt/mysql datadir=/data/3307/data user=mysql socket=/data/3307/mysql.sock port=3307 server_id=3307 EOF cp /data/3307/my.cnf /data/3308 cp /data/3307/my.cnf /data/3309 sed -i 's#3307#3308#g' /data/3308/my.cnf sed -i 's#3307#3309#g' /data/3309/my.cnf 5.3.3 初始化数据 mysqld --initialize-insecure --user=mysql --datadir=/data/3307/data --basedir=/opt/mysql mysqld --initialize-insecure --user=mysql --datadir=/data/3308/data --basedir=/opt/mysql mysqld --initialize-insecure --user=mysql --datadir=/data/3309/data --basedir=/opt/mysql 5.3.4 启动多实例 chown -R mysql.mysql /data/* mysqld_safe --defaults-file=/data/3307/my.cnf & mysqld_safe --defaults-file=/data/3308/my.cnf & mysqld_safe --defaults-file=/data/3309/my.cnf & 5.3.5 测试 netstat -lnp|grep 330 mysql -S /data/3307/mysql.sock mysql -S /data/3308/mysql.sock mysql -S /data/3309/mysql.sock 5.3.6 systemd管理多实例 cat >> /etc/systemd/system/mysqld3307.service <<EOF [Unit] Description=MySQL Server Documentation=man:mysqld(8) Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html After=network.target After=syslog.target [Install] WantedBy=multi-user.target [Service] User=mysql Group=mysql ExecStart=/opt/mysql/bin/mysqld --defaults-file=/data/3307/my.cnf LimitNOFILE = 5000 EOF cp /etc/systemd/system/mysqld3307.service /etc/systemd/system/mysqld3308.service cp /etc/systemd/system/mysqld3307.service /etc/systemd/system/mysqld3309.service sed -i 's#3307#3308#g' /etc/systemd/system/mysqld3308.service sed -i 's#3307#3309#g' /etc/systemd/system/mysqld3309.service systemctl start mysqld3307 systemctl start mysqld3308 systemctl start mysqld3309 netstat -lnp|grep 330 systemctl stop mysqld3309 systemctl stop mysqld3308 systemctl stop mysqld3307 systemctl enable mysqld3307 systemctl enable mysqld3308 systemctl enable mysqld3309
6.忘记密码处理
mysqladmin -uroot -p password 123 select user,authentication_string,host from mysql.user; 1.停数据库 /etc/init.d/mysqld stop 2.启动数据库为无密码验证模式 mysqld_safe --skip-grant-tables --skip-networking & update mysql.user set authentication_string=PASSWORD('456') where user='root' and host='localhost'; /etc/init.d/mysqld restart [root@standby ~]# mysql -uroot -p123 [root@standby ~]# mysql -uroot -p456
7.数据类型和字符集
整型 int 最多存10位数字 -2^31 ~ 2^31-1 2^32 10位数 11 浮点 字符串类型 char 定长,存储数据效率较高,对于变化较多的字段,空间浪费较多 varchar 变长,存储时判断长度,存储会有额外开销,按需分配存储空间. enum 时间 datetime timestamp date time SQL语句规范第五条: 1.少于10位的数字int ,大于10位数 char,例如手机号 2.char和varchar选择时,字符长度一定不变的可以使用char,可变的尽量使用varchar 在可变长度的存储时,将来使用不同的数据类型,对于索引树的高度是有影响的. 3.选择合适的数据类型 4.合适长度
8.索引及执行计划
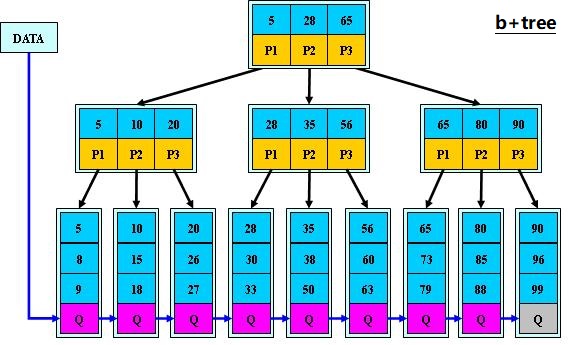
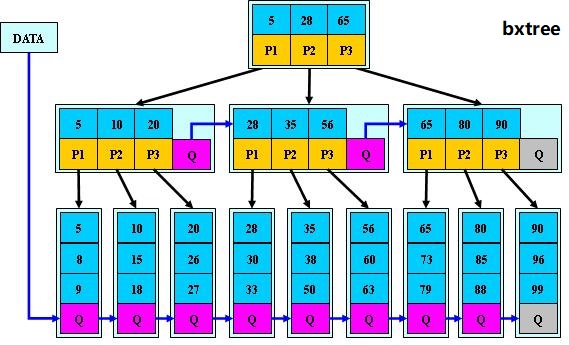
8.1 索引 作用: 优化查询,select 查询有三种情况:缓存查询(不在mysql中进行数据查询),全表扫描,索引扫描 8.2 索引种类 Btree(btree b+tree b*tree) Rtree HASH FullText 8.3 Btree 分类 聚集索引:基于主键,自动生成的,一般是建表时创建主键.如果没有主键,自动选择唯一键做为聚集索引. 辅助索引:人为创建的(普通,覆盖) 唯一索引:人为创建(普通索引,聚集索引) 聚集索引和辅助索引的对比 1.聚集索引:叶子结点,按照主键列的顺序,存储的整行数据,就是真正的数据页 2.辅助索引: 叶子结点,列值排序之后,存储到叶子结点+对应的主键的值,便于回表查询 8.4 索引管理命令 8.4.1 索引键(key),表中的某个列 辅助索引(BTREE) 怎么生成的: 根据创建索引时,指定的列的值,进行排序后,存储的叶子节点中 好处: 1.优化了查询,减少cpu mem IO消耗 2.减少的文件排序 创建普通辅助索引(MUL) alter table blog_userinfo add key idx_email(email); create index idx_phone on blog_userinfo(phone); 查看索引 desc blog_userinfo; show index from blog_userinfo; 删除索引 alter table blog_userinfo drop index idx_email; drop index idx_phone on blog_userinfo; 前缀索引 select count(*),substring(password,1,20) as sbp from blog_userinfo group by sbp; alter table blog_userinfo add index idx(password(10)); 唯一键索引(UNI,如果有重复值是创建不了的) alter table blog_userinfo add unique key uni_email(email); 覆盖索引(联合索引) 作用:不需要回表查询,不需要聚集索引,所有查询的数据都从辅助索引中获取 select * from people where gender , age , money a,b,c where a b c where a b alter table t1 add index idx_gam(gender,age,money); a b c where b c a where c a b where c where b 好处: 减少回表查询的几率
9. explain(desc)命令的应用
9.1 获取优化器选择后的执行计划 oldguo [world]>explain select * from city where countrycode='CHN'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: city type: ref possible_keys: CountryCode,idx_co_po key: CountryCode key_len: 3 ref: const rows: 1 Extra: Using index condition 1 row in set (0.00 sec) 9.2 重要的字段 9.2.1 type: 查询类型 作用: 1. 可以判断出,全表扫描还是索引扫描(ALL就是全表扫描,其他的就是索引扫描) 2. 对于索引扫描来讲,又可以细划分,可以判断是哪一种类的索引扫描 type的具体类型介绍: ALL:全表扫描 select * from t1; Index:全索引扫描 例子: desc select countrycode from city ; range:索引范围扫描 where > < >= <= in or between and like 'CH%' in 或者 or 改写成 union select * from city where countrycode='CHN' union all select * from city where countrycode='USA'; ref:辅助索引的等值查询 select * from city where countrycode='CHN' eq_ref: 多表链接查询(join on ) const ,system :主键或唯一键等值查询 Extra: using filesort: 文件排序 将order by group by distinct 后的列和where条件列建立联合索引 possible_keys: CountryCode,idx_co_po ---->可能会走的索引 key: CountryCode ---->真正走的索引 type: ref ---->索引类型 Extra: Using index condition ---->额外信息
建立索引的原则(运维规范) 一、数据库索引的设计原则: 为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引。 那么索引设计原则又是怎样的? 0.建表时一定要有主键,如果相关列可以作为主键,做一个无关列 1.选择唯一性索引 唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。 例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。 如果使用姓名的话,可能存在同名现象,从而降低查询速度。 主键索引和唯一键索引,在查询中使用是效率最高的。 select count(*) from world.city; select count(distinct countrycode) from world.city; select count(distinct countrycode,population ) from world.city; 注意:如果重复值较多,可以考虑采用联合索引 2.为经常需要排序、分组和联合操作的字段建立索引 经常需要ORDER BY、GROUP BY,join on等操作的字段,排序操作会浪费很多时间。 如果为其建立索引,可以有效地避免排序操作。 3.为常作为where查询条件的字段建立索引 如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此, 为这样的字段建立索引,可以提高整个表的查询速度。 3.1 经常查询 3.2 列值的重复值少(业务层面调整) 注:如果经常作为条件的列,重复值特别多,可以建立联合索引。 4.尽量使用前缀来索引 如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索 会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。 ------------------------以上的是重点关注的,以下是能保证则保证的-------------------- 5.限制索引的数目 索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。 修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。 6.删除不再使用或者很少使用的索引(percona toolkit) 表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理 员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。 7.大表加索引,要在业务不繁忙期间操作 建索引原则 (1) 必须要有主键,如果没有可以做为主键条件的列,创建无关列 (2) 经常做为where条件列 order by group by join on的条件(业务:产品功能+用户行为) (3) 最好使用唯一值多的列作为索引,如果索引列重复值较多,可以考虑使用联合索引 (4) 列值长度较长的索引列,我们建议使用前缀索引. (5) 降低索引条目,一方面不要创建没用索引,不常使用的索引清理,percona toolkit (6) 索引维护要避开业务繁忙期 业务: 1.产品的功能 2.用户的行为 =============================================== 不走索引的情况(开发规范) 重点关注: 1) 没有查询条件,或者查询条件没有建立索引 select * from tab; 全表扫描。 select * from tab where 1=1; 在业务数据库中,特别是数据量比较大的表。 是没有全表扫描这种需求。 1、对用户查看是非常痛苦的。 2、对服务器来讲毁灭性的。 (1)select * from tab; SQL改写成以下语句: selec * from tab order by price limit 10 需要在price列上建立索引 (2) select * from tab where name='zhangsan' name列没有索引 改: 1、换成有索引的列作为查询条件 2、将name列建立索引 2) 查询结果集是原表中的大部分数据,应该是25%以上。 查询的结果集,超过了总数行数25%,优化器觉得就没有必要走索引了。 假如:tab表 id,name id:1-100w ,id列有索引 select * from tab where id>500000; 如果业务允许,可以使用limit控制。 怎么改写 ? 结合业务判断,有没有更好的方式。如果没有更好的改写方案 尽量不要在mysql存放这个数据了。放到redis里面。 3) 索引本身失效,统计数据不真实 索引有自我维护的能力。 对于表内容变化比较频繁的情况下,有可能会出现索引失效。 4) 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等) 例子: 错误的例子:select * from test where id-1=9; 正确的例子:select * from test where id=10; 算术运算 函数运算 desc select * from blog_userinfo where DATE_FORMAT(last_login,'%Y-%m-%d') >= '2019-01-01'; 子查询 5)隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误. select * from t1 where telnum=110; 这样会导致索引失效. 错误的例子: ------------------------ mysql> alter table tab add index inx_tel(telnum); Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> mysql> desc tab; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | telnum | varchar(20) | YES | MUL | NULL | | +--------+-------------+------+-----+---------+-------+ 3 rows in set (0.01 sec) mysql> select * from tab where telnum='1333333'; +------+------+---------+ | id | name | telnum | +------+------+---------+ | 1 | a | 1333333 | +------+------+---------+ 1 row in set (0.00 sec) mysql> select * from tab where telnum=1333333; +------+------+---------+ | id | name | telnum | +------+------+---------+ | 1 | a | 1333333 | +------+------+---------+ 1 row in set (0.00 sec) mysql> explain select * from tab where telnum='1333333'; +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ | 1 | SIMPLE | tab | ref | inx_tel | inx_tel | 63 | const | 1 | Using index condition | +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ 1 row in set (0.00 sec) mysql> explain select * from tab where telnum=1333333; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | tab | ALL | inx_tel | NULL | NULL | NULL | 2 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec) mysql> explain select * from tab where telnum=1555555; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | tab | ALL | inx_tel | NULL | NULL | NULL | 2 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec) mysql> explain select * from tab where telnum='1555555'; +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ | 1 | SIMPLE | tab | ref | inx_tel | inx_tel | 63 | const | 1 | Using index condition | +----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+ 1 row in set (0.00 sec) mysql> --------------------------------------- 6) <> ,not in 不走索引 EXPLAIN SELECT * FROM teltab WHERE telnum <> '110'; EXPLAIN SELECT * FROM teltab WHERE telnum NOT IN ('110','119'); ------------ mysql> select * from tab where telnum <> '1555555'; +------+------+---------+ | id | name | telnum | +------+------+---------+ | 1 | a | 1333333 | +------+------+---------+ 1 row in set (0.00 sec) mysql> explain select * from tab where telnum <> '1555555'; ----- 单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit or或in 尽量改成union EXPLAIN SELECT * FROM teltab WHERE telnum IN ('110','119'); 改写成: EXPLAIN SELECT * FROM teltab WHERE telnum='110' UNION ALL SELECT * FROM teltab WHERE telnum='119' ----------------------------------- 7) like "%_" 百分号在最前面不走 EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%' 走range索引扫描 EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110' 不走索引 %linux%类的搜索需求,可以使用elasticsearch 专门做搜索服务的数据库产品 8) 单独引用联合索引里非第一位置的索引列.作为条件查询时不走索引. 列子: 复合索引: DROP TABLE t1 CREATE TABLE t1 (id INT,NAME VARCHAR(20),age INT ,sex ENUM('m','f'),money INT); ALTER TABLE t1 ADD INDEX t1_idx(money,age,sex); DESC t1 SHOW INDEX FROM t1 走索引的情况测试: EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30 AND sex='m'; EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30 ; EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND sex='m'; ----->部分走索引 不走索引的: EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=20 EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=30 AND sex='m'; EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE sex='m'; ===========压力测试=========== 1、模拟数据库数据 为了测试我们创建一个oldboy的库创建一个t1的表,然后导入50万行数据,脚本如下: vim slap.sh #!/bin/bash HOSTNAME="localhost" PORT="3306" USERNAME="root" PASSWORD="123" DBNAME="oldboy" TABLENAME="t1" #create database mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} -e "drop database if exists ${DBNAME}" create_db_sql="create database if not exists ${DBNAME}" mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} -e "${create_db_sql}" #create table create_table_sql="create table if not exists ${TABLENAME}(stuid int not null primary key,stuname varchar(20) not null,stusex char(1) not null,cardid varchar(20) not null,birthday datetime,entertime datetime,address varchar(100)default null)" mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} ${DBNAME} -e "${create_table_sql}" #insert data to table i="1" while [ $i -le 500000 ] do insert_sql="insert into ${TABLENAME} values($i,'alexsb_$i','1','110011198809163418','1990-05-16','2017-09-13','oldboyedu')" mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} ${DBNAME} -e "${insert_sql}" let i++ done #select data select_sql="select count(*) from ${TABLENAME}" mysql -h ${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} ${DBNAME} -e "${select_sql}" 执行脚本: sh slap.sh 2、检查数据可用性 mysql -uroot -p123 select count(*) from oldboy.t1; 3、在没有优化之前我们使用mysqlslap来进行压力测试 mysqlslap --defaults-file=/etc/my.cnf \ --concurrency=100 --iterations=1 --create-schema='oldboy' \ --query="select * from oldboy.t1 where stuname='alexsb_100'" engine=innodb \ --number-of-queries=2000 -uroot -p123 -verbose
后端 服务器 ping 端口号(22,80,443,3306,6379,8080,8000) ssh: cpu : mem : IO : 服务器启停: 真实硬件:远程管理卡,fence设备等 虚拟化产品:kvm , openstack, ,vmware esxi, docker,k8s 自动装系统: 真实硬件: kickstart + cobbler 虚拟化产品:克隆,启动新容器 自动化配置: ansiable,saltstack =====>SSH 生命周期管理 启停服务,监控zabbix(硬件) Devops:git jenkins 代码上线 堡垒机(jumpserver) VPN 数据库审核: 危险性操作 SQL性能审计 (全表扫描,抓取执行事件过长的语) 性能参数审核,根据性能指标,提出性能优化建议 数据库对象监控,提出整改建议 explain
10.存储引擎
10.1 作用 和磁盘的数据打交道 10.2 简介 MySQL 基于存储引擎管理 表空间数据数据文件 10.3 种类 Innodb存储引擎 ibd:存储表的数据行和索引 frm:表基本结构信息 Myisam存储引擎 frm myi myd 10.4 Innodb存储引擎核心特性 事务 保证交易的完整性 ACID特性 Atomic(原子性) 所有语句作为一个单元全部成功执行或全部取消。不允许出现中间过程. Consistent(一致性) 如果数据库在事务开始时处于一致状态,则在执行该事务期间将保留一致状态。 Isolated(隔离性) 事务之间不相互影响。 两个方面: 修改同一行 , 一致性读 Durable(持久性) 事务成功完成后,所做的所有更改都会准确地记录在数据库中。所做的更改不会丢失。 redo undo 实现了 ACD I 行级锁:事务修改行,会锁定这行(持有这行的锁) 隔离级别(一致性读): RU RC RR S 10.5 事务控制语句 begin; xxx xxx commit; begin; xxx xxx begin; xxxxx xxx rollback; 隐式提交 set autocommit=0; 永久: my.cnf autocommit=0; begin xxxxxx xxx begin begin xxx xxx create drop alter grant
11.日志
11.1 错误日志 log_error=/var/log/mysql.log 分析[error] 11.2 二进制日志 (binlog,逻辑型日志) 11.2.1 作用 记录所有变更类的语句 DDL,DCL :以语句方式(statement)记录 DML(已提交的事务语句):默认是以行模式记录(row模式,数据行的变化) 可以做数据恢复和操作的审计 11.2.2 配置方法 log_bin=/opt/mysql/data/mysql-bin binlog_format=row server_id=6 sync_binlog=1 11.2.3 查看日志信息 mysql> show binary logs; mysql> show master status; 11.2.4 日志内容查看 按事件查看日志内容 mysql> show binlog events in 'mysql-bin.000012'; 直接查看日志内容 mysqlbinlog --base64-output=decode-rows -vvv /opt/mysql/data/mysql-bin.000012 |more 11.2.5 截取二进制日志 [root@standby data]# mysqlbinlog --start-position=219 --stop-position=186613 /opt/mysql/data/mysql-bin.000012 >/tmp/binlog.sql 11.3 慢日志(slow-log) 记录慢语句的日志文件 slow_query_log=1 slow_query_log_file=/opt/mysql/data/standby-slow.log long_query_time=1 log_queries_not_using_indexes=1 使用Box Anemometer基于pt-query-digest将MySQL慢查询可视化
12.备份恢复
12.1 备份的种类 逻辑备份:SQL语句的备份 物理备份:数据页备份 12.2 逻辑备份工具的介绍 select xxxx from t1 into outfile '/tmp/redis.txt' mysql -uroot -p123 -e "select concat('hmset city_',id,' id ', id,' name ',name,' countrycode ',countrycode,' district ',district,' population ',population) from world.city limit 10 "|redis-cli mysqldump -u -p -S -h -P -A 全库备份 mysqldump -uroot -p123 -A >/backup/full.sql -B 备份一个或多个指定库 mysqldump -uroot -p123 -B world bbs >/backup/wb.sql 备份单库中的表 mysqldump -uroot -p123 world city country >/backup/ccc.sql --master-data=2 备份时记录二进制日志的状态 --single-transaction 开启innodb热备功能 -R --triggers mysqldump -uroot -p123 -A --master-data=2 --single-transaction -R --triggers >/backup/full.sql
13.主从复制
基于二进制日志完成的. Master slave 3307---->3308 1. 3307中创建复制用户 主库开启二进制日志 vim /data/3307/my.cnf log_bin=/data/3307/mysql-bin [root@standby 3307]# systemctl restart mysqld3307 [root@standby backup]# mysql -S /data/3307/mysql.sock grant replication slave on *.* to repl@'10.0.0.%' identified by '123'; mysql> show master status -> ; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 154 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec) mysql> 2.3308节点开启主从复制功能 [root@standby 3307]# mysql -S /data/3308/mysql.sock mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.200', MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_PORT=3307, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154; mysql> start slave; mysql> show slave status\G Slave_IO_Running: Yes Slave_SQL_Running: Yes
14.高可用架构
99% 1%*365=3.65D = 87.6h 99.9% 8.76h 99.99% 0.876h 99.999% 0.0876h MySQL高可用架构介绍 MHA 5.7 MGR+Mysql router+mysql shell.....===>Mysql Innodb Cluster ======>mongodb sharding cluster PXC galera cluster
15.高性能架构
读写分离 atlas 360 C++ maxscale mariadb proxySQL DRDS(买) mysql router 分布式架构 分片集群 Mycat DBLE TDDL DRDS

 浙公网安备 33010602011771号
浙公网安备 33010602011771号