



在准备学习人工智能之前呢,我看了一下大体的学习纲领。发现排在前面的是PYTHON的基础知识和爬虫相关的知识,再者就是相关的数学算法与金融分析。不过想来也是,如果想进行大量的数据运算与分析,宏大的基础数据是必不可少的。有了海量的基础数据,才可以支撑我们进行分析与抽取样本,进行深度的学习。
看到这个爬虫的介绍,突然想起来2012年左右在微软亚洲院做外派时做的一个项目。当时在亚洲研究院有一个试验性质的项目叫“O Project", 这里面的第一个字符是字母O。在真正的进入项目之后才知道为什么叫“O”:在IPAD上面使用safari浏览器浏览一个网站,激活插件后,使用手指画圈圈,而圈圈内的词组就会向Bing和Google发出查询请求,在查询请求完成后,返回相应的结果。这个主要是应用在页面级,类似于现在页面上的单词翻译一样。
当时在做这个项目的时候,还没有爬虫的概念与理念。所以我是通过这样的方式来实现这个需求的:
1. 创建一个服务,这个服务主要是接收前台页面回传的圈圈词句;
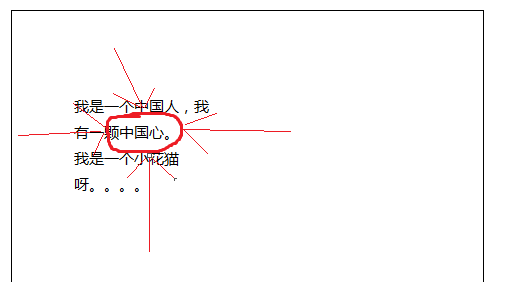
2. 在页面当中激活绘图功能(主要是safari),根据绘制的圈圈,取出页面当中的词句。取出词语的方式也很简单,例如下面的图画:
所画的圈圈的四个最上、下、左、右的元素的X和Y坐标,然后再根据页面当中的文字对应出其所在页面当中的坐标值,如果字符串在这四个坐标内,就认为其为圈中的字符串。
如果像图当中的“颗”这个字,其左坐标没有包含在左箭头的X和Y的范围内,则不将“颗”统计的字符串内,但是“中”满足这样的条件。
3. 在取得圈内的字符串后,回传回后台的服务。
4. 后台的服务向BING和GOOGLE发出查询请求。当时因为没有现在的Python和Scrapy这些流行的框架及组件,我只能通过C#来进行解析:创建一个流程器对象,设置其URL为BING或者GOOGLE的查询字符串。在接收完回传信息后,截取其内容也就是HTML字符串,摘取其中的搜索结果、引用地址及相应的简介。
5. 将所收集到的内容存放到数据库当中进行备案查询或者其他的用处。
6. 当时要对于可能感兴趣的内容进行推荐,就需要人工去点击或者匹配相应的词汇来完成更深入的查询与匹配。现在想想真是太落后了。
随着学习的深入,目前完成了Python的基础使用、工具的使用、第三方工具的初步使用等。在接下来的文章当中我一步步的向大家进行共享吧。

