CSAPP lab6 piplined processor笔记
lab6 piplined processor笔记
part A
主要是写汇编代码。比较简单,略过
part B
比较简单,略过
part C
修改pipe-full.hcl和ncopy.ys,保证程序正确性的同时,使得程序运行越快越好。
要求:
- pipe-full.hcl:实现iaddq指令
- ncopy.ys:根据csapp章节3.5.8(循环展开)进行优化
sdriver:2个元素。ldriver:63个元素
benchmark结果:1~64个元素,平均CPE=15.18(pdf上说的)
iaddq优化
类似part B,在pipe-fll.hcl可以轻松实现iaddq指令。
将ncopy.ys的组合指令irmovq和addq合并为iaddq后,benchmark结果:

循环展开
使用最基础的2*1循环展开,其余的元素(Remain)用最简单的for循环:
xorq %rax,%rax
Test:
iaddq $-2, %rdx
jl Remain
Loop:
mrmovq (%rdi), %r10
rmmovq %r10, (%rsi)
andq %r10, %r10
jle Npos1
iaddq $1, %rax
Npos1:
mrmovq 8(%rdi), %r10
rmmovq %r10, 8(%rsi)
andq %r10, %r10
jle Npos2
iaddq $1, %rax
Npos2:
iaddq $16, %rdi
iaddq $16, %rsi
jmp Test
Remain:
iaddq $2, %rdx
jle Done
Loop1:
mrmovq (%rdi), %r10
rmmovq %r10, (%rsi)
andq %r10, %r10
jle Npos3
iaddq $1, %rax
Npos3:
iaddq $8, %rdi
iaddq $8, %rsi
iaddq $-1, %rdx
jg Loop1
benchmark结果:

4*1展开:

8*1展开:

有两个可以继续优化的地方:
- Loop8循环
- 剩余元素
Loop8循环优化
原本的Loop8:
Loop8:
mrmovq (%rdi), %r10
rmmovq %r10, (%rsi)
andq %r10, %r10
jle Npos1
iaddq $1, %rax
Npos1:
mrmovq 8(%rdi), %r10
rmmovq %r10, 8(%rsi)
andq %r10, %r10
jle Npos2
iaddq $1, %rax
Npos2:
....
为什么慢?因为mrmovq和rmmovq紧挨在一起。根据流水线原理,分为FDEMW五个阶段,rmmovq需要前一条指令的访存值(数据冒险,通过数据转发解决),
FDEMW (mrmovq)
FDEMW
FDEMW (rmmovq)
则需要插入1个Bubble,保证rmmovq的D和mrmovq的M在同一时间。所以浪费了1个周期。
优化:将mrmovq放在一起,将rmmovq放在一起,将有数据依赖的隔远一点:
Loop8:
mrmovq (%rdi), %rcx
mrmovq 8(%rdi), %rbx
mrmovq 16(%rdi), %r8
mrmovq 24(%rdi), %r9
mrmovq 32(%rdi), %r10
mrmovq 40(%rdi), %r11
mrmovq 48(%rdi), %r12
mrmovq 56(%rdi), %r13
rmmovq %rcx, (%rsi)
rmmovq %rbx, 8(%rsi)
rmmovq %r8, 16(%rsi)
rmmovq %r9, 24(%rsi)
rmmovq %r10, 32(%rsi)
rmmovq %r11, 40(%rsi)
rmmovq %r12, 48(%rsi)
rmmovq %r13, 56(%rsi)
andq %rcx, %rcx
jle Npos1
iaddq $1, %rax
Npos1:
andq %rbx, %rbx
jle Npos2
iaddq $1, %rax
Npos2:
andq %r8, %r8
jle Npos3
iaddq $1, %rax
Npos3:
andq %r9, %r9
jle Npos4
iaddq $1, %rax
Npos4:
andq %r10, %r10
jle Npos5
iaddq $1, %rax
Npos5:
andq %r11, %r11
jle Npos6
iaddq $1, %rax
Npos6:
andq %r12, %r12
jle Npos7
iaddq $1, %rax
Npos7:
andq %r13, %r13
jle Npos8
iaddq $1, %rax
Npos8:
iaddq $64, %rdi
iaddq $64, %rsi
iaddq $-8, %rdx
jge Loop8
结果:
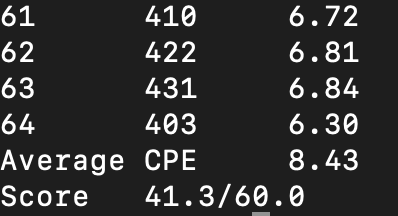
剩余元素优化 法1 二分法
二分法思想:如果满足8个,则进入Loop8循环,若满足4个,则进入Loop4,若满足2个,进入Loop2。
Remain4标签作用:由于之前-8,现在必须+8
xorq %rax,%rax
Test8:
iaddq $-8, %rdx
jl Remain4
Loop8:
//省略
jmp Test8
Remain4:
iaddq $8, %rdx
Test4:
iaddq $-4, %rdx
jl Remain2
Loop4:
//省略
jmp Test4
Remain2:
iaddq $4, %rdx
Test2:
iaddq $-2, %rdx
jl Remain1
Loop2:
//省略
jmp Test2
Remain1:
iaddq $2, %rdx
Test1:
iaddq $-1, %rdx
jl Done
Loop1:
//省略
结果:

优化Remain标签的iaddq后:
xorq %rax,%rax
Test8:
iaddq $-8, %rdx
jl Test4
Loop8:
// 省略
jmp Test8
Test4:
iaddq $4, %rdx
jl Test2
Loop4:
// 省略
iaddq $-4, %rdx
Test2:
iaddq $2, %rdx
jl Test1
Loop2:
// 省略
iaddq $-2, %rdx
Test1:
iaddq $1, %rdx
jl Done
Loop1:
// 省略
Test8已经把8消耗完了,进入Test4的是-8-1(对应07)。
Test4
Test2
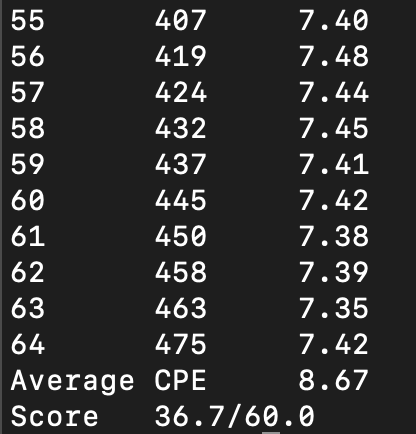
benchmark:

剩余元素优化 法2 跳转表
剩余元素是0~7个,可以用跳转表的形式实现。首先push,然后ret即可
xorq %rax,%rax
Test8:
iaddq $-8, %rdx
jl Remain
Loop8:
//省略
iaddq $-8, %rdx
jge Loop8
Remain:
addq %rdx, %rdx
addq %rdx, %rdx
addq %rdx, %rdx # rdx * 8
mrmovq JumpTable(%rdx), %rdx
pushq %rdx
ret # goto JumpTable[rdx]
R7:
mrmovq 48(%rdi), %r10
rmmovq %r10, 48(%rsi)
andq %r10, %r10
jle R6
iaddq $1, %rax
R6:
mrmovq 40(%rdi), %r10
rmmovq %r10, 40(%rsi)
andq %r10, %r10
jle R5
iaddq $1, %rax
R5:
mrmovq 32(%rdi), %r10
rmmovq %r10, 32(%rsi)
andq %r10, %r10
jle R4
iaddq $1, %rax
R4:
mrmovq 24(%rdi), %r10
rmmovq %r10, 24(%rsi)
andq %r10, %r10
jle R3
iaddq $1, %rax
R3:
mrmovq 16(%rdi), %r10
rmmovq %r10, 16(%rsi)
andq %r10, %r10
jle R2
iaddq $1, %rax
R2:
mrmovq 8(%rdi), %r
rmmovq %r10, 8(%rsi)
andq %r10, %r10
jle R1
iaddq $1, %rax
R1:
mrmovq (%rdi), %r10
rmmovq %r10, (%rsi)
andq %r10, %r10
jle Done
iaddq $1, %rax
Done:
ret
quad Done
.quad R1
.quad R2
.quad R3
.quad R4
.quad R5
.quad R6
.quad R7
JumpTable:
剩余元素优化 法3 单循环展开
使用单循环展开,效果最优:
方法:循环展开,并且在mrmovq和rmmovq之间插入指令,利用气泡。
xorq %rax,%rax
Test8:
iaddq $-8, %rdx
jl Test4
Loop8:
// 省略
jmp Test8
Remain:
iaddq $8, %rdx
jg R1
ret
R1:
mrmovq (%rdi), %r10
mrmovq 8(%rdi), %r11
rmmovq %r10, (%rsi)
andq %r10, %r10
jle Npos9
iaddq $1, %rax
Npos9:
iaddq $-1, %rdx
jne R2
ret
R2:
mrmovq 16(%rdi), %r10
rmmovq %r11, 8(%rsi)
andq %r11, %r11
jle Npos10
iaddq $1, %rax
Npos10:
iaddq $-1, %rdx
jne R3
ret
R3:
mrmovq 24(%rdi), %r11
rmmovq %r10, 16(%rsi)
andq %r10, %r10
jle Npos11
iaddq $1, %rax
Npos11:
iaddq $-1, %rdx
jne R4
ret
R4:
mrmovq 32(%rdi), %r10
rmmovq %r11, 24(%rsi)
andq %r11, %r11
jle Npos12
iaddq $1, %rax
Npos12:
iaddq $-1, %rdx
jne R5
ret
R5:
mrmovq 40(%rdi), %r11
rmmovq %r10, 32(%rsi)
andq %r10, %r10
jle Npos13
iaddq $1, %rax
Npos13:
iaddq $-1, %rdx
jne R6
ret
R6:
mrmovq 48(%rdi), %r10
rmmovq %r11, 40(%rsi)
andq %r11, %r11
jle Npos14
iaddq $1, %rax
Npos14:
iaddq $-1, %rdx
jne R7
ret
R7:
rmmovq %r10, 48(%rsi)
andq %r10, %r10
jle Npos15
iaddq $1, %rax
Npos15:
结合loop8优化,最终结果:
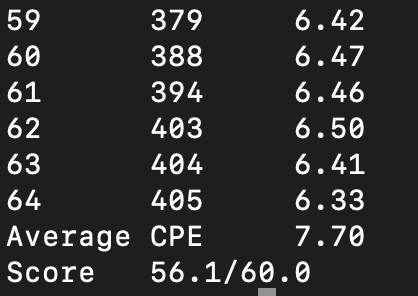
分类:
csapp lab


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!