CSAPP lab5 Y86-64 Assembler笔记
lab5 Y86-64 Assembler笔记
本lab需要编写汇编器(assembler),将Y86-64的汇编代码转换为二进制代码。代码文件:y64sam.c
头文件重要数据结构
/* Table used to encode information about instructions */
// 指令集的指令
typedef struct instr {
char *name; // 指令名称,如rrmovq
int len; // 指令字符串长度
byte_t code; /* code for instruction+op */ // 指令指示符,占一个字节
int bytes; /* the size of instr */ // 二进制编码的总长度
} instr_t;
/* Token types: comment, instruction, error */
// 解析一行的结果,TYPE_COMM是注释,TYPE_INS是指令,TYPE_ERR表示解析错误
typedef enum{ TYPE_COMM, TYPE_INS, TYPE_ERR } type_t;
// 一条二进制代码
typedef struct bin {
int64_t addr; // 虚拟空间地址
byte_t codes[10]; // 代码内容
int bytes; // 代码长度
} bin_t;
// 一行汇编代码
typedef struct line {
type_t type; /* TYPE_COMM: no y64bin, TYPE_INS: both y64bin and y64asm */
bin_t y64bin; // 待解析的二进制代码
char *y64asm; // 汇编代码
struct line *next;
} line_t;
/* label defined in y64 assembly code, e.g. Loop */
// 符号,以单链表形式组织
typedef struct symbol {
char *name; // 符号名称
int64_t addr; // 虚拟空间地址
struct symbol *next;
} symbol_t;
/* binary code need to be relocated */
// 待重定向的代码,以单链表形式组织
typedef struct reloc {
bin_t *y64bin;
char *name;
struct reloc *next;
} reloc_t;
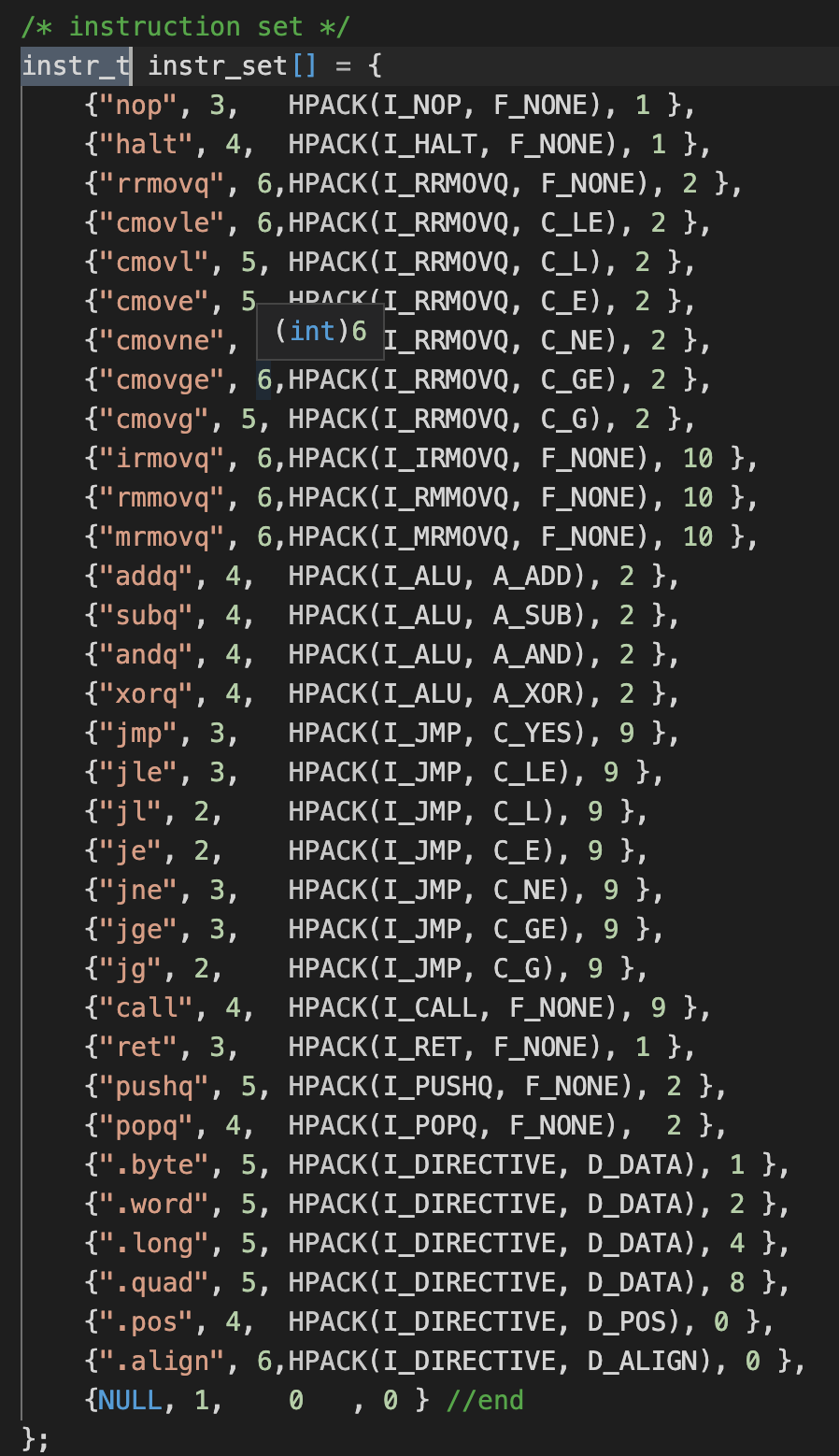
伪指令I_DIRECTIVE说明
这些指令未在CSAPP书中列出,只是简单提及了一下。
-
D_DATA类型:如.byte,用于指定常量数据的大小。比如.byte 0x123456说明将常数视为1个byte,所以指令占据1个byte
-
D_POS类型:.pos 0x200,指定当前代码的虚拟空间地址,本身不占指令长度。 -
D_ALIGN类型:如.align 8,当前代码的地址vmaddr要进行8对齐,比如如果vmaddr=5,应该修改为vmaddr=8
符号和重定向
符号和重定向均是单链表,在init()中初始化(malloc),在finit()中释放空间。
/* symbol table (don't forget to init and finit it) */
symbol_t *symtab = NULL;
/* relocation table (don't forget to init and finit it) */
reloc_t *reltab = NULL;
-
find_symbol:在符号表中寻找符号,简单的单链表遍历:
symbol_t *find_symbol(char *name) { for (symbol_t* sym = symtab->next; sym != NULL; sym = sym->next) if (strcmp(sym->name, name) == 0) return sym; return NULL; } -
add_symbol:添加符号到符号表中。symbol_t.name需要申请空间(申请空间应该是
strlen(name)+1,因为strlen()不统计末尾的'\0'),然后将新符号添加到头符号后面一个即可。/* * add_symbol: add a new symbol to the symbol table * args * name: the name of symbol * * return * 0: success * -1: error, the symbol has exist */ int add_symbol(char *name) { /* check duplicate */ if (find_symbol(name) != NULL) return -1; /* create new symbol_t (don't forget to free it)*/ symbol_t* sym = (symbol_t*)malloc(sizeof(symbol_t)); sym->name = (char*)malloc(strlen(name) + 1); strcpy(sym->name, name); sym->addr = vmaddr; /* add the new symbol_t to symbol table */ sym->next = symtab->next; symtab->next = sym; return 0; } -
add_reloc:添加重定向。和add_symbol类似。
-
relocate:重定向。在assemble()调用每一行的parse_line后,对重定向表对应的二进制代码修改值为符号的地址。
int relocate(void) { reloc_t *rtmp = reltab->next; while (rtmp) { /* find symbol */ symbol_t* stmp = find_symbol(rtmp->name); if (stmp == NULL) { err_print("Unknown symbol:'%s'", rtmp->name); return -1; } /* relocate y64bin according itype */ switch (rtmp->y64bin->bytes) { case 1: case 2: case 4: case 8: for (int i = 0; i < rtmp->y64bin->bytes; i++) { rtmp->y64bin->codes[i] = (stmp->addr >> (i * 8)) & 0xFF; } break; case 9: case 10: for (int i = 0; i < 8; i++) { rtmp->y64bin->codes[rtmp->y64bin->bytes - 8 + i] = (stmp->addr >> (i * 8)) & 0xFF; } break; default: return -1; } /* next */ rtmp = rtmp->next; } return 0; }
解析token:parse_xxx
-
parse_instr:解析指令标识符:
parse_t parse_instr(char **ptr, instr_t **inst) { /* skip the blank */ SKIP_BLANK(*ptr); /* find_instr and check end */ instr_t* ins = find_instr(*ptr); if (ins == NULL) return PARSE_ERR; /* set 'ptr' and 'inst' */ (*ptr) += ins->len; *inst = ins; return PARSE_INSTR; }-
parse_delim,parse_reg类似,略过
-
parse_symbol:解析符号(符号出现在指令中,用于代替数字,比如jmp或者irmovq)。这里同样要注意,字符串申请空间要比字符数大1,因为末尾是'\0'
parse_t parse_symbol(char **ptr, char **name) { /* skip the blank and check */ SKIP_BLANK(*ptr); if (!IS_LETTER(*ptr)) return PARSE_ERR; /* allocate name and copy to it */ char* tmp = *ptr; int cnt = 0; while (!IS_BLANK(tmp) && !IS_END(tmp) && (*tmp) != ',') { tmp++; cnt++; } /* set 'ptr' and 'name' */ *name = (char*)malloc(cnt + 1); strncpy(*name, *ptr, cnt); (*name)[cnt] = '\0'; *ptr = tmp; return PARSE_SYMBOL; } -
parse_digit:解析数字。有一个坑:strtoll()转换结果是有符号
long,对于大于LONG_MAX的数,会自动转化为LONG_MAX。但是测试样例中一个大于LONG_MAX,正确答案是转化为无符号long存储。这里偷了懒,面向测试样例编程,只考虑了那一个特殊情况(是16进制)parse_t parse_digit(char **ptr, long *value) { /* skip the blank and check */ SKIP_BLANK(*ptr); if (!IS_DIGIT(*ptr)) return PARSE_ERR; /* calculate the digit, (NOTE: see strtoll()) */ char* tmp; *value = strtoll(*ptr, &tmp, 0); // if digit exceeds INT_MAX, need to intercept the value manually if (*value == __LONG_MAX__) { unsigned long val = 0; tmp = *ptr; if (*tmp == '0' && (*(tmp + 1) == 'x' || *(tmp + 1) == 'X')) { tmp += 2; } byte_t b = 0; for (int i = 0; i < 16; i++) { if (*tmp >= '0' && *tmp <= '9') { b = *tmp - 48; } else if (*tmp >= 'A' && *tmp <= 'F') { b = *tmp - 55; } else if (*tmp >= 'a' && *tmp <= 'f') { b = *tmp - 87; } val = (val << 4) + b; tmp++; } *value = val; } /* set 'ptr' and 'value' */ *ptr = tmp; return PARSE_DIGIT; } -
parse_imm:解析立即数。立即数可能是以
$开头的数字,也可能是一个符号。parse_t parse_imm(char **ptr, char **name, long *value) { /* skip the blank and check */ parse_t result = PARSE_ERR; SKIP_BLANK(*ptr); /* if IS_IMM, then parse the digit */ if (IS_IMM(*ptr)) { (*ptr)++; result = parse_digit(ptr, value); } /* if IS_LETTER, then parse the symbol */ else if (IS_LETTER(*ptr)) result = parse_symbol(ptr, name); /* set 'ptr' and 'name' or 'value' */ return result; } -
parse_mem:解析
D(reg)内存符(如8(%rax))。parse_t parse_mem(char **ptr, long *value, regid_t *regid) { /* skip the blank and check */ SKIP_BLANK(*ptr); *value = 0; /* calculate the digit and register, (ex: (%rbp) or 8(%rbp)) */ if (IS_DIGIT(*ptr)) { if (parse_digit(ptr, value) != PARSE_ERR && parse_delim(ptr, '(') != PARSE_ERR && parse_reg(ptr, regid) != PARSE_ERR && parse_delim(ptr, ')') != PARSE_ERR) return PARSE_MEM; } else { if (parse_delim(ptr, '(') != PARSE_ERR && parse_reg(ptr, regid) != PARSE_ERR && parse_delim(ptr, ')') != PARSE_ERR) return PARSE_MEM; } /* set 'ptr', 'value' and 'regid' */ return PARSE_ERR; } -
parse_data:解析data(用于I_DIRECTIVE指令),data可能是一个数字或者符号。解析过程和parse_imm类似,略过。
-
parse_label:解析标签(如
Loop:)。这里和parse_symbol不同,碰到:才算一个合法的标签。parse_t parse_label(char **ptr, char **name) { /* skip the blank and check */ SKIP_BLANK(*ptr); if (!IS_LETTER(*ptr)) return PARSE_ERR; /* allocate name and copy to it */ char* tmp = *ptr; int cnt = 0; while (!IS_BLANK(tmp) && !IS_END(tmp)) { if ((*tmp) == ':') { *name = (char*)malloc(cnt + 1); strncpy(*name, *ptr, cnt); (*name)[cnt] = '\0'; *ptr = tmp + 1; return PARSE_LABEL; } tmp++; cnt++; } /* set 'ptr' and 'name' */ return PARSE_ERR; }
-
parse_line
核心函数,解析一行。需要根据情况选择以上的parse_xxx
/*
* parse_line: parse a line of y64 code (e.g., 'Loop: mrmovq (%rcx), %rsi')
* (you could combine above parse_xxx functions to do it)
* args
* line: point to a line_t data with a line of y64 assembly code
*
* return
* TYPE_XXX: success, fill line_t with assembled y64 code
* TYPE_ERR: error, try to print err information
*/
type_t parse_line(line_t *line)
{
/* when finish parse an instruction or lable, we still need to continue check
* e.g.,
* Loop: mrmovl (%rbp), %rcx
* call SUM #invoke SUM function */
char* ptr= line->y64asm;
regid_t regA = REG_NONE, regB = REG_NONE;
char* name = NULL;
long value = 0;
instr_t* inst = NULL;
parse_t type = PARSE_ERR;
/* skip blank and check IS_END */
SKIP_BLANK(ptr);
if (IS_END(ptr)) {
line->type = TYPE_COMM;
return TYPE_COMM;
}
/* is a comment ? */
if (IS_COMMENT(ptr)) {
line->type = TYPE_COMM;
return TYPE_COMM;
}
/* is a label ? */
if (parse_label(&ptr, &name) == PARSE_LABEL) {
line->type = TYPE_INS;
line->y64bin.addr = vmaddr;
line->y64bin.bytes = 0;
if (add_symbol(name) == -1) {
err_print("Dup symbol:%s", name);
return TYPE_ERR;
}
}
/* is an instruction ? */
if (parse_instr(&ptr, &inst) == PARSE_INSTR) {
line->type = TYPE_INS;
line->y64bin.addr = vmaddr;
line->y64bin.bytes = inst->bytes;
line->y64bin.codes[0] = inst->code;
itype_t icode = HIGH(inst->code);
dtv_t dcode = LOW(inst->code);
switch (icode) {
case I_HALT:
case I_NOP:
case I_RET:
break;
case I_RRMOVQ:
case I_ALU:
if (parse_reg(&ptr, ®A) == PARSE_ERR) {
err_print("Invalid REG");
return TYPE_ERR;
}
if (parse_delim(&ptr, ',') == PARSE_ERR) {
err_print("Invalid ','");
return TYPE_ERR;
}
if (parse_reg(&ptr, ®B) == PARSE_ERR) {
err_print("Invalid REG");
return TYPE_ERR;
}
line->y64bin.codes[1] = HPACK(regA, regB);
break;
case I_IRMOVQ:
type = parse_imm(&ptr, &name, &value);
if (type == PARSE_ERR) {
err_print("Invalid Immediate");
return TYPE_ERR;
}
if (parse_delim(&ptr, ',') == PARSE_ERR) {
err_print("Invalid ','");
return TYPE_ERR;
}
if (parse_reg(&ptr, ®B) == PARSE_ERR) {
err_print("Invalid REG");
return TYPE_ERR;
}
line->y64bin.codes[1] = HPACK(regA, regB);
if (type == PARSE_DIGIT)
for (int i = 0; i < 8; i++)
line->y64bin.codes[i + 2] = (value >> (8 * i)) & 0xFF;
else if (type == PARSE_SYMBOL)
add_reloc(name, &line->y64bin);
break;
case I_RMMOVQ:
if (parse_reg(&ptr, ®A) == PARSE_ERR) {
err_print("Invalid REG");
return TYPE_ERR;
}
if (parse_delim(&ptr, ',') == PARSE_ERR) {
err_print("Invalid ','");
return TYPE_ERR;
}
if (parse_mem(&ptr, &value, ®B) == PARSE_ERR) {
err_print("Invalid MEM");
return TYPE_ERR;
}
line->y64bin.codes[1] = HPACK(regA, regB);
for (int i = 0; i < 8; i++)
line->y64bin.codes[i + 2] = (value >> (8 * i)) & 0xFF;
break;
case I_MRMOVQ:
if (parse_mem(&ptr, &value, ®B) == PARSE_ERR) {
err_print("Invalid MEM");
return TYPE_ERR;
}
if (parse_delim(&ptr, ',') == PARSE_ERR) {
err_print("Invalid ','");
return TYPE_ERR;
}
if (parse_reg(&ptr, ®A) == PARSE_ERR) {
err_print("Invalid REG");
return TYPE_ERR;
}
line->y64bin.codes[1] = HPACK(regA, regB);
for (int i = 0; i < 8; i++)
line->y64bin.codes[i + 2] = (value >> (8 * i)) & 0xFF;
break;
case I_JMP:
case I_CALL:
type = parse_imm(&ptr, &name, &value);
if (type == PARSE_ERR) {
err_print("Invalid DEST");
return TYPE_ERR;
} else if (type == PARSE_DIGIT)
for (int i = 0; i < 8; i++)
line->y64bin.codes[i + 1] = (value >> (8 * i)) & 0xFF;
else if (type == PARSE_SYMBOL)
add_reloc(name, &line->y64bin);
break;
case I_PUSHQ:
case I_POPQ:
if (parse_reg(&ptr, ®A) == PARSE_ERR) {
err_print("Invalid REG");
return TYPE_ERR;
}
line->y64bin.codes[1] = HPACK(regA, regB);
break;
case I_DIRECTIVE:{
switch(dcode){
case D_DATA:
type = parse_data(&ptr, &name, &value);
if (type == PARSE_ERR) {
err_print("parse data error");
return TYPE_ERR;
} else if (type == PARSE_DIGIT) {
for (int i = 0; i < inst->bytes; i++)
line->y64bin.codes[i] = (value >> (i * 8)) & 0xFF;
} else if (type == PARSE_SYMBOL) {
add_reloc(name, &line->y64bin);
}
break;
case D_POS:
if (parse_digit(&ptr, &value) == PARSE_ERR) {
err_print("parse digit error");
return TYPE_ERR;
}
vmaddr = value;
break;
case D_ALIGN:
if (parse_digit(&ptr, &value) == PARSE_ERR) {
err_print("parse digit error");
return TYPE_ERR;
}
vmaddr = (vmaddr + value - 1) / value * value;
break;
default:
break;
}
}
default:
break;
}
line->y64bin.addr = vmaddr;
vmaddr += line->y64bin.bytes;
}
// parse registers
/* set type and y64bin */
/* update vmaddr */
/* parse the rest of instruction according to the itype */
SKIP_BLANK(ptr);
if (!IS_END(ptr) && !IS_COMMENT(ptr)) {
return TYPE_ERR;
}
return line->type;
}
bin_file
对于所有解析过的line,生成二进制文件。这里要注意,写入每一行时,需要先用fseek()将文件指针指向当前行的地址
/*
* binfile: generate the y64 binary file
* args
* out: point to output file (an y64 binary file)
*
* return
* 0: success
* -1: error
*/
int binfile(FILE *out)
{
/* prepare image with y64 binary code */
line_t* line = line_head;
/* binary write y64 code to output file (NOTE: see fwrite()) */
while (line != NULL) {
if (line->type == TYPE_INS) {
fseek(out, line->y64bin.addr, SEEK_SET);
fwrite(line->y64bin.codes, 1, line->y64bin.bytes, out);
}
line = line->next;
}
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!