calcite解析sql
calcite解析sql
1. Calcite简介
Apache Calcite是一个动态数据管理框架,它具备很多典型数据库管理系统的功能,比如SQL解析、SQL校验、SQL查询优化、SQL生成以及数据连接查询等,但是又省略了一些关键的功能,比如Calcite并不存储相关的元数据和基本数据,不完全包含相关处理数据的算法等。
也正是因为Calcite本身与数据存储和处理的逻辑无关,所以这让它成为与多个数据存储位置(数据源)和多种数据处理引擎之间进行调解的绝佳选择。
Calcite所做的工作就是将各种SQL语句解析成抽象语法树(AST Abstract Syntax Tree),并根据一定的规则或成本对AST的算法与关系进行优化,最后推给各个数据处理引擎进行执行。
2. Calcite 主要功能
- SQL解析:通过JavaCC将SQL解析成未经校验的AST语法树
- SQL校验:校验分两部分,一种为无状态的校验,即验证SQL语句是否符合规范;一种为有状态的即通过与元数据结合验证SQL中的Schema、Field、Function是否存在。
- SQL查询优化:对上个步骤的输出(RelNode)进行优化,得到优化后的物理执行计划
- SQL生成:将物理执行计划生成为在特定平台/引擎的可执行程序,如生成符合Mysql or Oracle等不同平台规则的SQL查询语句等
- 数据连接与执行:通过各个执行平台执行查询,得到输出结果。

如上图中所述,一般来说Calcite解析SQL有以下几步:
- Parser. 此步中Calcite通过Java CC将SQL解析成未经校验的AST
- Validate. 该步骤主要作用是校证Parser步骤中的AST是否合法,如验证SQL scheme、字段、函数等是否存在; SQL语句是否合法等. 此步完成之后就生成了RelNode树(关于RelNode树, 请参考下文)
- Optimize. 该步骤主要的作用优化RelNode树, 并将其转化成物理执行计划。主要涉及SQL规则优化如:基于规则优化(RBO)及基于代价(CBO)优化; Optimze 这一步原则上来说是可选的, 通过Validate后的RelNode树已经可以直接转化物理执行计划,但现代的SQL解析器基本上都包括有这一步,目的是优化SQL执行计划。此步得到的结果为物理执行计划。
- Execute,即执行阶段。此阶段主要做的是:将物理执行计划转化成可在特定的平台执行的程序。如Hive与Flink都在在此阶段将物理执行计划CodeGen生成相应的可执行代码。
3. 技术特性
- 支持标准 SQL 语言;
- 独立于编程语言和数据源,可以支持不同的前端和后端;
- 支持关系代数、可定制的逻辑规划规则和基于成本模型优化的查询引擎;
- 支持物化视图( materialized view)的管理(创建、丢弃、持久化和自动识别);
- 基于物化视图的 Lattice 和 Tile 机制,以应用于 OLAP 分析;
- 支持对流数据的查询。
技术特性详细介绍
基于关系代数的查询引擎
我们知道,关系代数是关系型数据库操作的理论基础,关系代数支持并、差、笛卡尔积、投影和选择等基本运算。关系代数是Calcite 的核心,任何一个查询都可以表示成由关系运算符组成的树。 你可以将SQL 转换成关系代数,或者通过Calcite 提供的API 直接创建它。比如下面这段SQL 查询:
|
SELECT deptno, count(*) AS c, sum(sal) AS s
|
|
|
FROM emp
|
|
|
GROUP BY deptno
|
|
|
HAVING count(*) > 10
|
可以表达成如下的关系表达式语法树:
|
LogicalFilter(condition=[>($1, 10)])
|
|
|
LogicalAggregate(group=[{7}], C=[COUNT()], S=[SUM($5)])
|
|
|
LogicalTableScan(table=[[scott, EMP]])
|
当上层编程语言,如 SQL 转换为关系表达式后,就会被送到 Calcite 的逻辑规划器进行规则匹配。在这个过程中,Calcite 查询引擎会循环使用规划规则对关系表达式语法树的节点和子图进行优化。这种优化过程会以一个成本模型作为参考,每次优化都在保证语义的情况下利用规则来降低成本,成本主要以查询时间最快、资源消耗最少这些维度去度量。
使用逻辑规划规则等同于数学恒等式变换,比如将一个过滤器推到内连接(inner join)输入的内部执行,当然使用这个规则的前提是过滤器不会引用内连接输入之外的数据列。图 1 就是一个将 Filter 操作下推到 Join 下面的示例,这样做的好处是减少 Join 操作记录的数量。
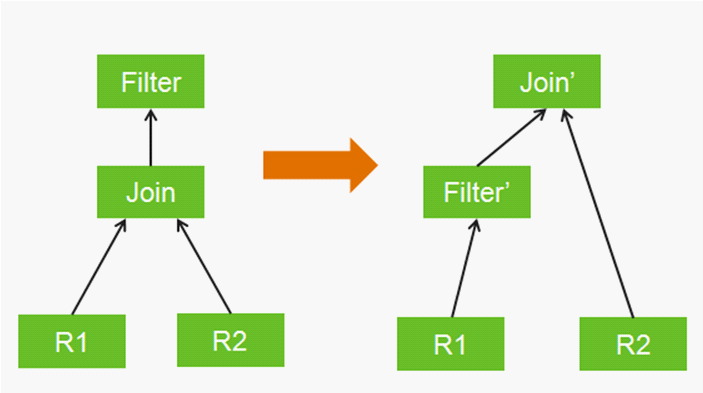
图 1:一个逻辑规划的规则匹配(Filter 操作下沉)
非常好的一点是 Calcite 中的查询引擎是可以定制和扩展的,你可以自定义关系运算符、规划规则、成本模型和相关的统计,从而应用到不同需求的场景。
动态的数据管理系统
Calcite 的设计目标是成为动态的数据管理系统,所以在具有很多特性的同时,它也舍弃了一些功能,比如数据存储、处理数据的算法和元数据仓库。由于舍弃了这些功能,Calcite 可以在应用和数据存储、数据处理引擎之间很好地扮演中介的角色。用Calcite 创建数据库非常灵活,你只需要动态地添加数据即可。
同时,前面提到过,Calcite 使用了基于关系代数的查询引擎,聚焦在关系代数的语法分析和查询逻辑的规划制定上。它不受上层编程语言的限制,前端可以使用SQL、Pig、Cascading 或者Scalding,只要通过Calcite 提供的API 将它们转化成关系代数的抽象语法树即可。
同时,Calcite 也不涉及物理规划层,它通过扩展适配器来连接多种后端的数据源和处理引擎,如Spark、Splunk、HBase、Cassandra 或者MangoDB。简单的说,这种架构就是“一种查询引擎,连接多种前端和后端”。
物化视图的应用
Calcite 的物化视图是从传统的关系型数据库系统(Oracle/DB2/Teradata/SQL server)借鉴而来,传统概念上,一个物化视图包含一个 SQL 查询和这个查询所生成的数据表。
下面是在 Hive 中创建物化视图的一个例子,它按部门、性别统计出相应的员工数量和工资总额:
|
CREATE MATERIALIZED VIEW emp_summary AS
|
|
|
SELECT deptno, gender, COUNT(*) AS c, SUM(salary) AS s
|
|
|
FROM emp
|
|
|
GROUP BY deptno, gender;
|
|
|
;
|
因为物化视图本质上也是一个数据表,所以你可以直接查询它,比如下面这个例子查询男员工人数大于 20 的部门:
|
SELECT deptno FROM emp_summary
|
|
|
WHERE gender = ‘M’ AND c > 20;
|
更重要的是,你还可以通过物化视图的查询取代对相关数据表的查询,可参见图 2。由于物化视图一般存储在内存中,且其数据更接近于最终结果,所以查询速度会大大加快。
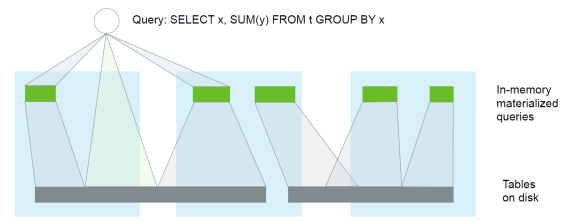
图 2:查询、物化视图和表的关系
比如下面这个对员工表(emp)的查询(女性的平均工资):
|
SELECT deptno, AVG(salary) AS average_sal
|
|
|
FROM emp WHERE gender = 'F'
|
|
|
GROUP BY deptno;
|
可以被 Calcite 规划器改写成对物化视图(emp_summary)的查询:
|
SELECT deptno, s / c AS average_sal
|
|
|
FROM emp_summary WHERE gender = 'F'
|
|
|
GROUP BY deptno;
|
我们可以看到,多数值的平均运算,即先累加再除法转化成了单个除法。
为了让物化视图可以被所有编程语言访问,需要将其转化为与语言无关的关系代数并将其元数据保存在 Hive 的 HCatalog 中。HCatalog 可以独立于 Hive,被其它查询引擎使用,它负责 Hadoop 元数据和表的管理。
物化视图可以进一步扩展为 DIMMQ(Discardable, In-Memory, Materialized Query)。简单地说,DIMMQ 就是内存中可丢弃的物化视图,它是高级别的缓存。相对原始数据,它离查询结果更近,所占空间更小,并可以被多个应用共享,并且应用不必感知物化视图存在,查询引擎会自动匹配它。物化视图可以和异构存储结合起来,即它可以存储在 Disk、SSD 或者内存中,并根据数据的热度进行动态调整。
除了上面例子中的归纳表(员工工资、员工数量),物化视图还可以应用在其它地方,比如 b-tree 索引 (使用基础的排序投影运算)、分区表和远端快照。总之,通过使用物化视图,应用程序可以设计自己的派生数据结构,并使其被系统自动识别和使用。
在线分析处理(OLAP)
为了加速在线分析处理,除了物化视图,Calcite 还引入 Lattice(格子)和 Tile(瓷片)的概念。Lattice 可以看做是在星模式(star schema)数据模型下对物化视图的推荐、创建和识别的机制。这种推荐可以根据查询的频次统计,也可以基于某些分析维度的重要等级。Tile 则是Lattice 中的一个逻辑的物化视图,它可以通过三种方法来实体化:1)在lattice 中声明;2)通过推荐算法实现;3)在响应查询时创建。
下图是 Lattice 和 Tile 的一个图例,这个 OLAP 分析涉及五个维度的数据:邮政编码、州、性别、年和月。每个椭圆代表一个 Tile,黑色椭圆是实体化后物化视图,椭圆中的数字代表该物化视图对应的记录数。
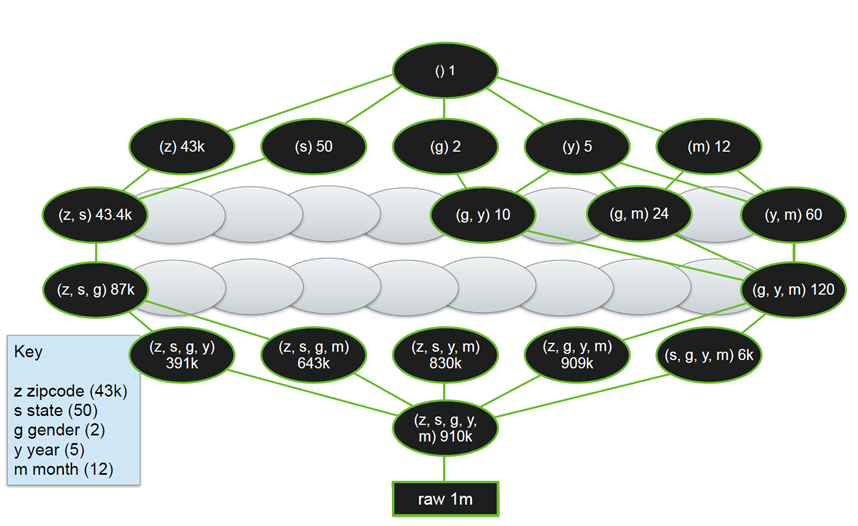
图 3:Lattice 和 Tile 的示例图
由于 Calcite 可以很好地支持物化视图和星模式这些 OLAP 分析的关键特性,所以 Apache 基金会的 Kylin 项目(Hadoop 上 OLAP 系统)在选用查询引擎时就直接集成了 Calcite。
支持流查询
Calcite 对其 SQL 和关系代数进行了扩展以支持流查询。Calcite 的 SQL 语言是标准 SQL 的扩展,而不是类 SQL(SQL-like),这个差别非常重要,因为:
- 如果你懂标准 SQL,那么流的 SQL 也会非常容易学;
- 因为在流和表上使用相同的机制,语义会很清楚;
- 你可以写同时对流和表结合的查询语句;
- 很多工具可以直接生成标准的 SQL。
Calcite 的流查询除了支持排序、聚合、过滤等常用操作和子查询外,也支持各种窗口操作,比如翻滚窗口(Tumbling window)、跳跃窗口(Hopping window)、滑动窗口(Sliding windows)、级联窗口(Cascading window)。其中级联窗口可以看作是滑动窗口和翻滚窗口的结合。
4. Calcite相关组件
Calcite主要有以下概念:
- Catelog: 主要定义SQL语义相关的元数据与命名空间。
- SQL parser: 主要是把SQL转化成AST.
- SQL validator: 通过Catalog来校证AST.
- Query optimizer: 将AST转化成物理执行计划、优化物理执行计划.
- SQL generator: 反向将物理执行计划转化成SQL语句.
4.1 category
Catalog:主要定义被SQL访问的命名空间,主要包括以下几点: 1. schema: 主要定义schema与表的集合,schame 并不是强制一定需要的,比如说有两张同名的表T1, T2,就需要schema要区分这两张表,如A.T1, B.T1 2. 表:对应关系数据库的表,代表一类数据,在calcite中由RelDataType定义 3. RelDataType 代表表的数据定义,如表的数据列名称、类型等。
Schema:
public interface Schema {
Table getTable(String name);
Set<String> getTableNames();
Set<String> getFunctionNames();
Schema getSubSchema(String name);
Set<String> getSubSchemaNames();
Expression getExpression(SchemaPlus parentSchema, String name);
boolean isMutable();Table:
public interface Table {
RelDataType getRowType(RelDataTypeFactory typeFactory);
Statistic getStatistic();
Schema.TableType getJdbcTableType();
}其中RelDataType代表Row的数据类型, Statistic 用于统计表的相关数据、特别是在CBO用于计表计算表的代价。
一句Sql
selcct id, name, cast(age as bigint) from A.INFOid, name则为data type fieldbigint为 data typeA为schemaINFO为表
4.2 SQL Parser
由Java CC编写,将SQL转化成AST.
- Java CC 指的是Java Compiler Compiler, 可以将一种特定域相关的语言转化成Java语言
- 在Calcite中将标记(Token)表示为
SqlNode, 并且Sqlnode可以通过unparse方法反向转化成SQL
cast(id as float)Java CC 可表示为
```java cc e = Expression(ExprContext.ACCEPT_SUBQUERY) dt = DataType() {agrs.add(dt);} ....
### 4.3 Query Optimizer
首先看一下
```sql
INSERT INTO tmp_node
SELECT s1.id1, s1.id2, s2.val1
FROM source1 as s1 INNER JOIN source2 AS s2
ON s1.id1 = s2.id1 and s1.id2 = s2.id2 where s1.val1 > 5 and s2.val2 = 3;通过Calcite转化为:
LogicalTableModify(table=[[TMP_NODE]], operation=[INSERT], flattened=[false])
LogicalProject(ID1=[$0], ID2=[$1], VAL1=[$7])
LogicalFilter(condition=[AND(>($2, 5), =($8, 3))])
LogicalJoin(condition=[AND(=($0, $5), =($1, $6))], joinType=[INNER])
LogicalTableScan(table=[[SOURCE1]])
LogicalTableScan(table=[[SOURCE2]])是未经优化的RelNode树,可以发现最底层是TableScan,也是读取表的原始数据,紧接着是LogicalJoin,Joiner的类型为INNER JOIN, LogicalJoin之后接下做LogicalFilter 操作,对应SQL中的WHERE条件,最后做Project也就是投影操作。
但是我们可以观察到对于INNER JOIN而言, WHERE 条件是可以下推,如
LogicalTableModify(table=[[TMP_NODE]], operation=[INSERT], flattened=[false])
LogicalProject(ID1=[$0], ID2=[$1], VAL1=[$7])
LogicalJoin(condition=[AND(=($0, $5), =($1, $6))], joinType=[inner])
LogicalFilter(condition=[=($4, 3)])
LogicalProject(ID1=[$0], ID2=[$1], ID3=[$2], VAL1=[$3], VAL2=[$4],VAL3=[$5])
LogicalTableScan(table=[[SOURCE1]])
LogicalFilter(condition=[>($3,5)])
LogicalProject(ID1=[$0], ID2=[$1], ID3=[$2], VAL1=[$3], VAL2=[$4],VAL3=[$5])
LogicalTableScan(table=[[SOURCE2]])这样可以减少JOIN的数据量,提高SQL效率
实际过程中可以将JOIN 的中条件下推以较少Join的数据量
INSERT INTO tmp_node
SELECT s1.id1, s1.id2, s2.val1
FROM source1 as s1 LEFT JOIN source2 AS s2
ON s1.id1 = s2.id1 and s1.id2 = s2.id2 and s1.id3 = 5s1.id3 = 5 这个条件可以先下推过滤s1中的数据, 但在特定场景下,有些不能下推,如下sql:
INSERT INTO tmp_node
SELECT s1.id1, s1.id2, s2.val1
FROM source1 as s1 LEFT JOIN source2 AS s2
ON s1.id1 = s2.id1 and s1.id2 = s2.id2 and s2.id3 = 5如果s1,s2是流式表(动态表,请参考Flink流式概念)的话,就不能下推,因为s1下推的话,由于过滤后没有数据驱动join操作,因而得不到想要的结果(详见Flink/Sparking-Streaming)
那接下来我们可能有一个疑问,在什么情况下可以做类似下推、上推操作,又是根据什么原则进行的呢?如下图所示
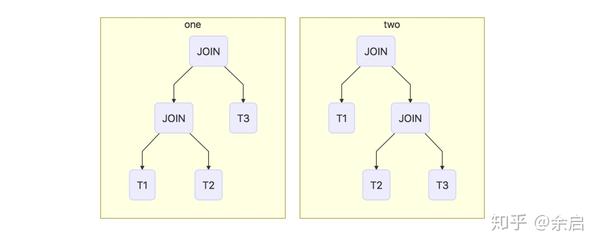
T1 JOIN T2 JOIN T3类似于此种情况JOIN的顺序是上图的前者还是后者?这就涉及到Optimizer所使用的方法,Optimizer主要目的就是减小SQL所处理的数据量、减少所消耗的资源并最大程度提高SQL执行效率如:剪掉无用的列、合并投影、子查询转化成JOIN、JOIN重排序、下推投影、下推过滤等。目前主要有两类优化方法:基于语法(RBO)与基于代价(CBO)的优化
- RBO(Rule Based Optimization)
通俗一点的话就是事先定义一系列的规则,然后根据这些规则来优化执行计划。 如 - ProjectFilterRule
此Rule的使用场景为Filter在Project之上,可以将Filter下推。假如某一个RelNode树
LogicalFilter
LogicalProject
LogicalTableScan则可优化成
LogicalProject
LogicalFilter
LogicalTableScan- FilterJoinRule
此Rule的使用场景为Filter在Join之上,可以先做Filter然后再做Join, 以减少Join的数量
等等,还有很多类似的规则。但RBO一定程度上是经验试的优化方法,无法有一个公式上的判断哪种优化更优。 在Calcite中实现方法为 HepPlanner
- CBO(Cost Based Optimization)
通俗一点的说法是:通过某种算法计算SQL所有可能的执行计划的“代价”,选择某一个代价较低的执行计划,如上文中三张表作JOIN, 一般来说RBO无法判断哪种执行计划优化更好,只有分别计算每一种JOIN方法的代价。
Calcite会将每一种操作(如LogicaJoin、LocialFilter、 LogicalProject、LogicalScan) 结合实际的Schema转化成具体的代价数,比较不同的执行计划所具有的代价,然后选择相对小计划作为最终的结果,之所以说相对小,这是因为如果要完全遍历计算所有可能的代价可能得不偿失,花费更多的人力与资源,因此只是说选择相对最优的执行计划。CBO目的是“避免使用最差的执行计划,而不是找到最好的”
目前Calcite中就是采用CBO进行优化,实现方法为VolcanoPlanner,有关此算法的具体内容可以参考原码
5. 如何使用Calcite
由于Calcite是Java语言编写,因此只需要在工程或项目中引入相应的Jar包即可,下面为一个可以运行的例子:


1 public class TestOne { 2 public static class TestSchema { 3 public final Triple[] rdf = {new Triple("s", "p", "o")}; 4 } 5 6 public static void main(String[] args) { 7 SchemaPlus schemaPlus = Frameworks.createRootSchema(true); 8 9 //给schema T中添加表 10 schemaPlus.add("T", new ReflectiveSchema(new TestSchema())); 11 Frameworks.ConfigBuilder configBuilder = Frameworks.newConfigBuilder(); 12 //设置默认schema 13 configBuilder.defaultSchema(schemaPlus); 14 15 FrameworkConfig frameworkConfig = configBuilder.build(); 16 17 SqlParser.ConfigBuilder paresrConfig = SqlParser.configBuilder(frameworkConfig.getParserConfig()); 18 19 //SQL 大小写不敏感 20 paresrConfig.setCaseSensitive(false).setConfig(paresrConfig.build()); 21 22 Planner planner = Frameworks.getPlanner(frameworkConfig); 23 24 SqlNode sqlNode; 25 RelRoot relRoot = null; 26 try { 27 //parser阶段 28 sqlNode = planner.parse("select \"a\".\"s\", count(\"a\".\"s\") from \"T\".\"rdf\" \"a\" group by \"a\".\"s\""); 29 //validate阶段 30 planner.validate(sqlNode); 31 //获取RelNode树的根 32 relRoot = planner.rel(sqlNode); 33 } catch (Exception e) { 34 e.printStackTrace(); 35 } 36 37 RelNode relNode = relRoot.project(); 38 System.out.print(RelOptUtil.toString(relNode)); 39 } 40 } 41 类Triple 对应的表定义: 42 43 public class Triple { 44 public String s; 45 public String p; 46 public String o; 47 48 public Triple(String s, String p, String o) { 49 super(); 50 this.s = s; 51 this.p = p; 52 this.o = o; 53 } 54 55 }
详细可以代码在这里
参考链接:
1. 手把手教你使用calcite解析SQL - 知乎 (zhihu.com)
2. Apache顶级项目 Calcite使用介绍_慕课手记 (imooc.com)
3. Apache Calcite:Hadoop中新型大数据查询引擎_开源_楚晗_InfoQ精选文章
4. http://hbasefly.com/2017/05/04/bigdata%EF%BC%8Dcbo/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号