java正则匹配简介
java正则匹配简介
1. 问题描述
根据指定的字段名限制条件,提取出sql语句中的对应字段名并返回。
字段名限制条件如下:
必须以 ${ 开头,} 结尾;
中间只能包含字母、数字和下划线(_);
中间只能以字母开头;
中间长度在 3~63 个字符范围内。
比如:从小面这段sql中提取出t2_name和t3_name, 并替换成空字符串。
SELECT
t.`t2_name` AS `t2_name`,
t.`t3_name` AS `t3_name`
FROM
(
SELECT
t2.`name` AS `t2_name`,
t3.`name` AS `t3_name`
FROM
mysql130.database1.`table1` t1
LEFT JOIN mysql130.database1.`table2` t2 ON t2.`id` = t1.`id`
LEFT JOIN mysql130.database1.`table3` t3 ON t1.`id` = t3.`id`
) t
WHERE
t.`t2_name` = '${t2_name}' and t.`t3_name` = '${t3_name}'
2. 问题思路
大体思路如下
- 先写出对应的正则表达式
- 使用Pattern和Matcher类进行匹配,提取出对应的内容
- 替换掉原来的内容
1. 正则表达式
必须以 ${ 开头,} 结尾; ^${ and }$
中间只能包含字母、数字和下划线(); [a-zA-Z0-9] or \w (等价)
中间只能以字母开头; [a-zA-Z]
中间长度在 3~63 个字符范围内。 {3,63} 除去第一个为
最终的组合结果为:
^\$\{ + [a-zA-Z] + [a-zA-Z0-9_]{2,62} + \}$ -> ^\$\{[a-zA-Z][a-zA-Z0-9_]{2,62}\}$
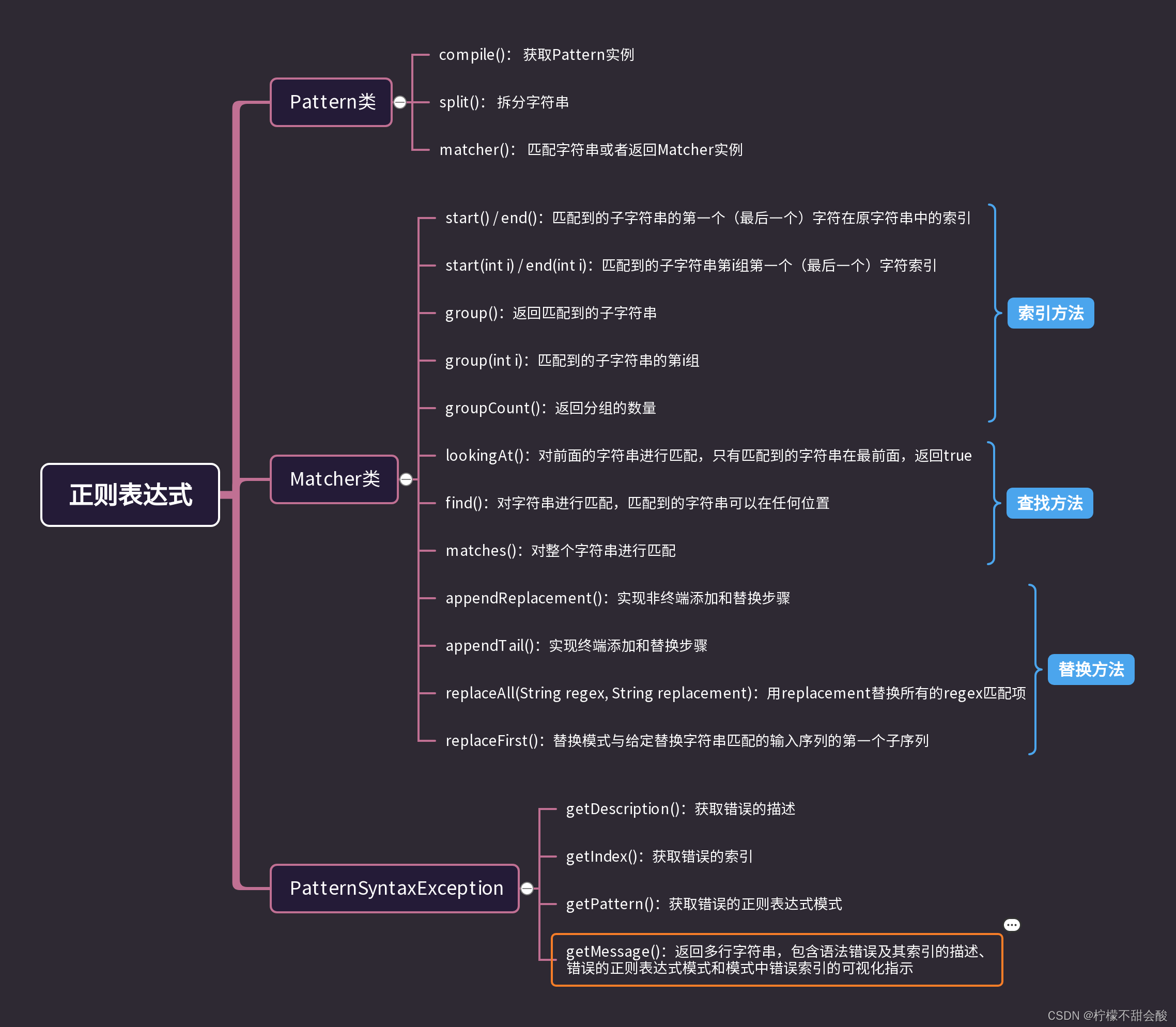
2. 梳理java中 Pattern 和 Matcher类的关系
-
梳理Matcher类常用方法
-
常见报错
-
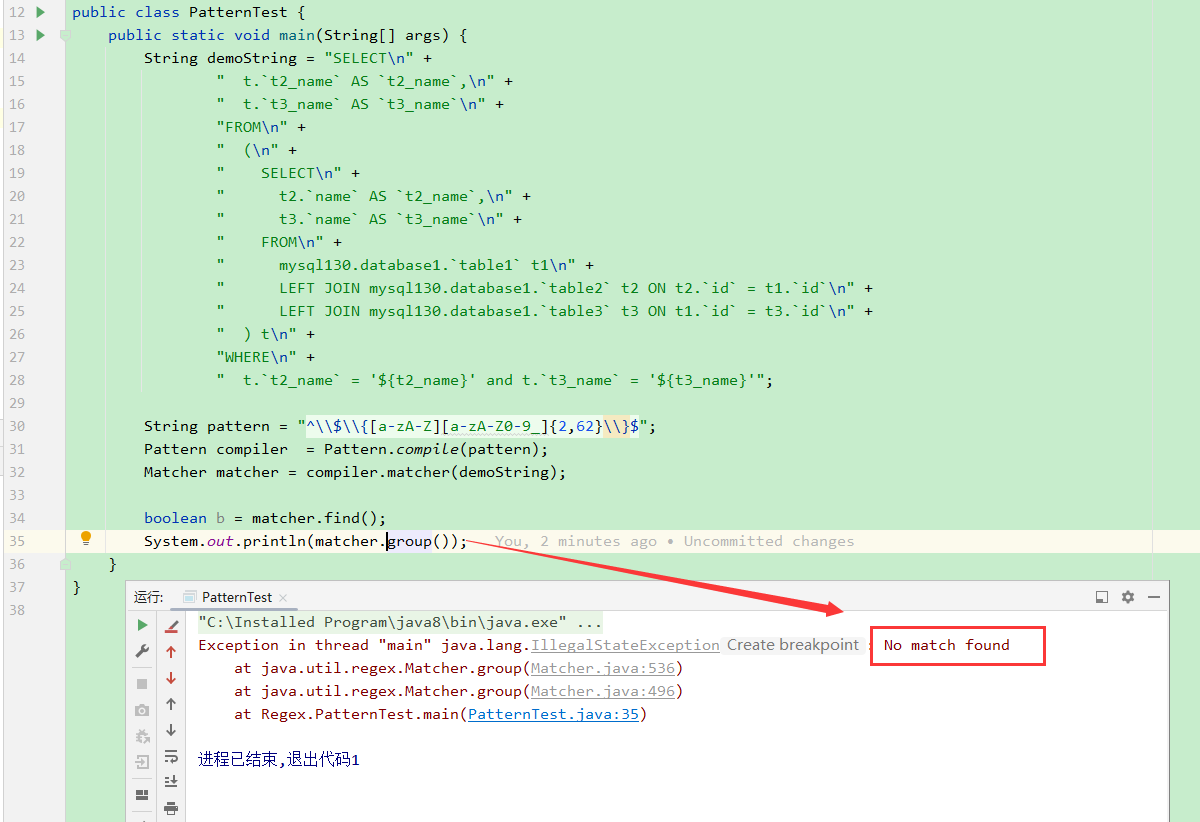
goup()方法报错
java.lang.IllegalStateException: No match found
解决方法:使用find()方法进行匹配,如果匹配成功,再使用group()方法获取匹配的内容。
// 匹配成功 if (matcher.find()) { // 获取匹配的内容 String group = matcher.group(); System.out.println(group); }
-
^表示匹配行的开头,$表示匹配行的结尾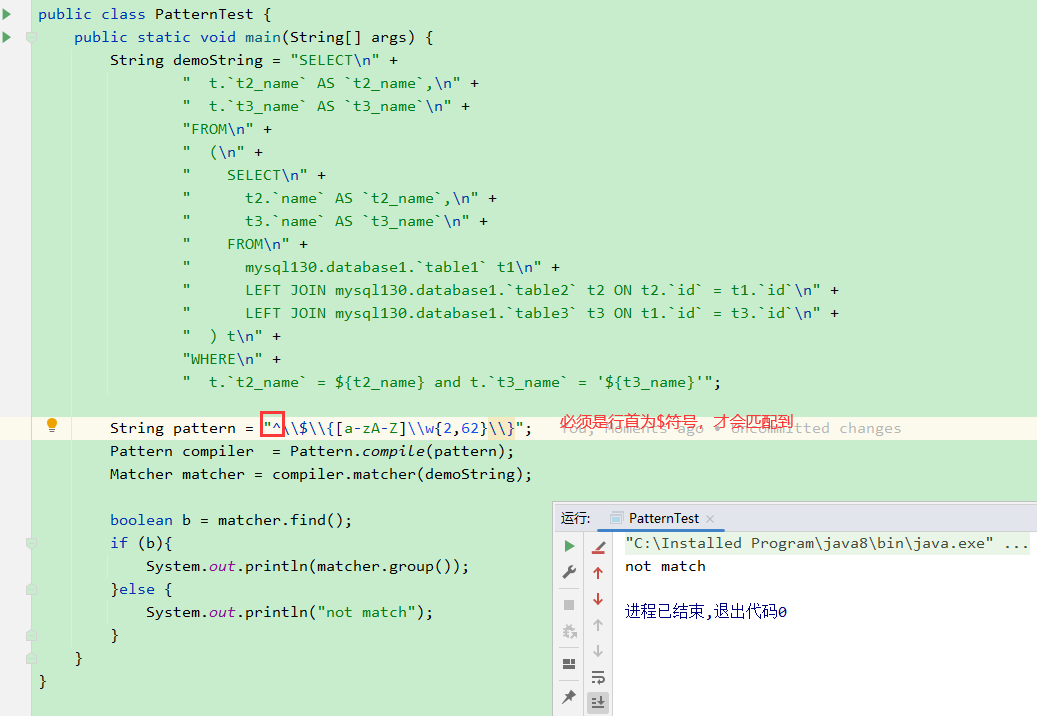
此处为行首则可匹配成功
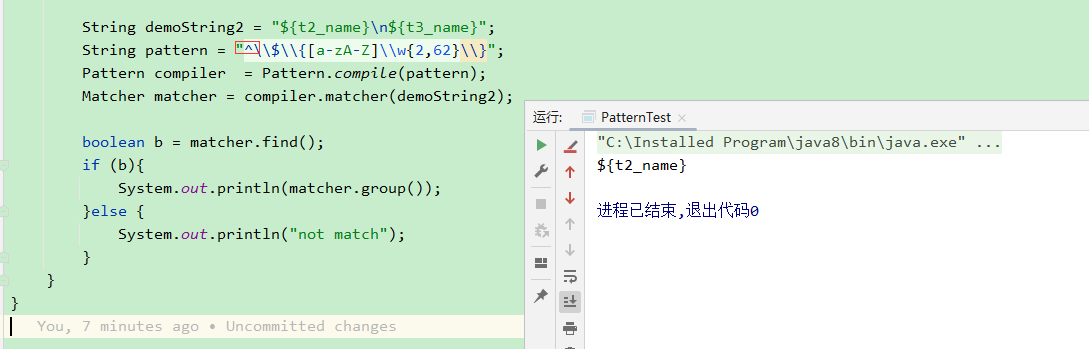
默认模式下,一个字符串只有一个行首和行位,中间加了
\r\n也不能算是行首和行位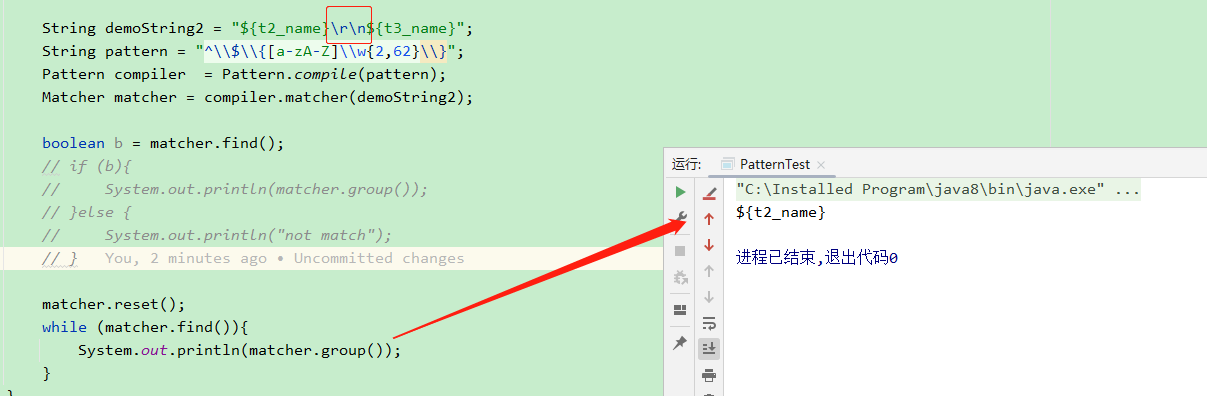
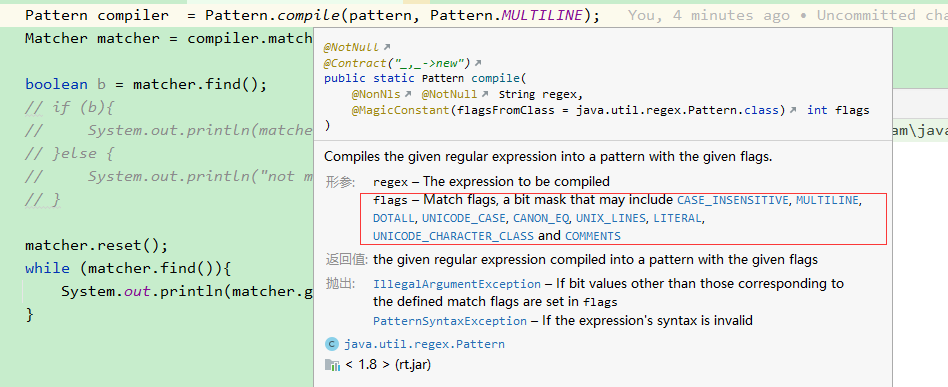
如果字符串中包含多行文本,需要使用多行模式(Pattern.MULTILINE)来匹配多行字符串。在多行模式下,^ 和 $ 会匹配行的开头和结尾,而不是整个字符串的开头和结尾。
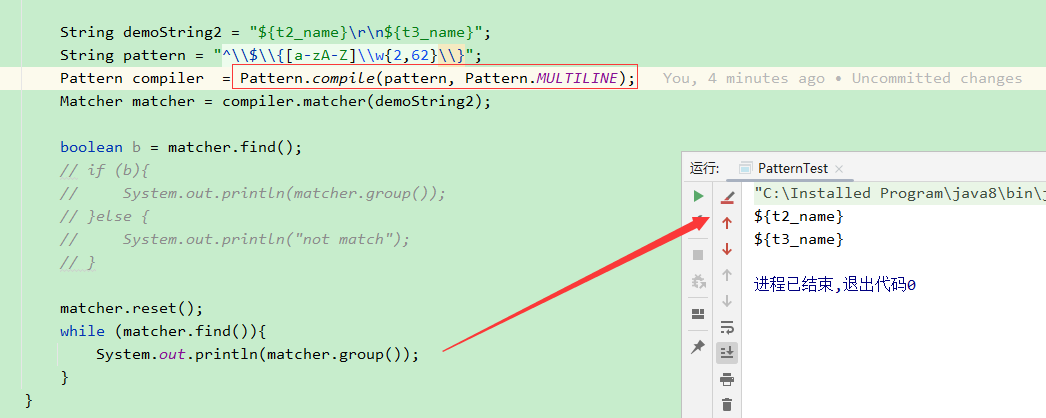
-
No Group 1

解决方法:使用group(0)获取匹配的内容
弄明白group的含义:
group代表的是The index of a capturing group in this matcher's pattern,即匹配的组的索引,从1开始,0代表整个匹配的内容。什么时候会出现组呢?
当正则表达式中包含括号时,就会出现组。比如:
(\d{3})-(\d{3,8}),这个正则表达式中有两个组,第一个组是(\d{3}),第二个组是(\d{3,8})。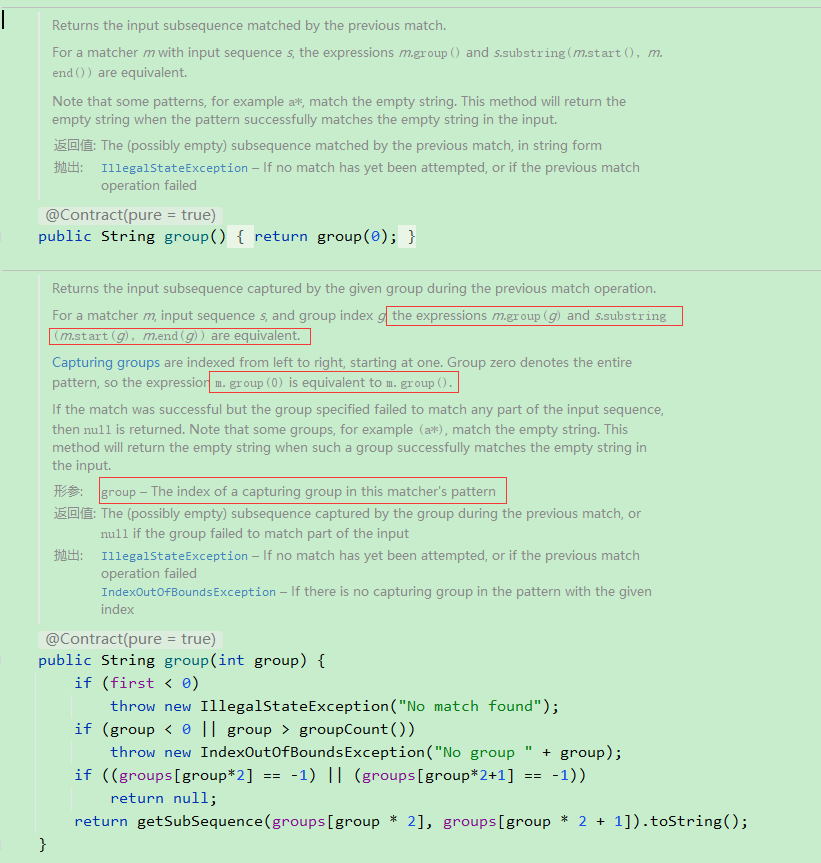
有组的demo
// 有组的情况下,group(0)是整个匹配的字符串,group(1)是第一个组匹配的字符串 // 无组的情况下,group(0)是整个匹配的字符串,group(1)是null // 无组的情况下,groupCount()是0 // 有组的情况下,groupCount()是组的个数 String demoString3 = "010-12345"; String pattern2 = "(\\d{3})-(\\d{3,8})"; Pattern compiler2 = Pattern.compile(pattern2); Matcher matcher2 = compiler2.matcher(demoString3); while (matcher2.find()) { System.out.println(matcher2.group(0)); System.out.println(matcher2.group(1)); System.out.println(matcher2.group(2)); } // 输出结果 010-12345 010 12345 ``` -
为什么中间的匹配不到呢?
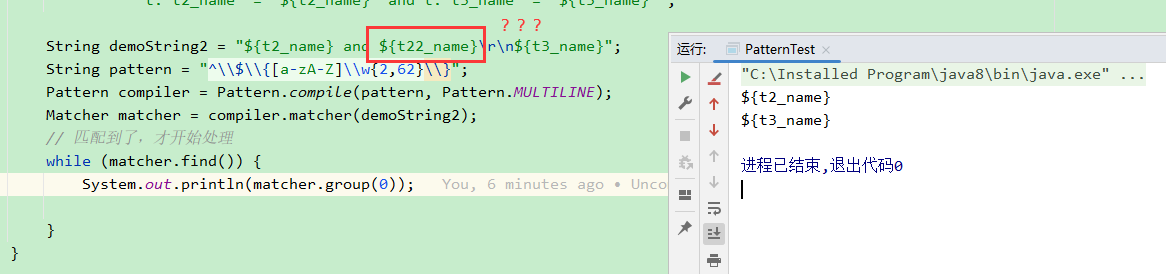
因为正则指定了必须以$开始的字符串,第二个没有换行,换行后则可匹配到
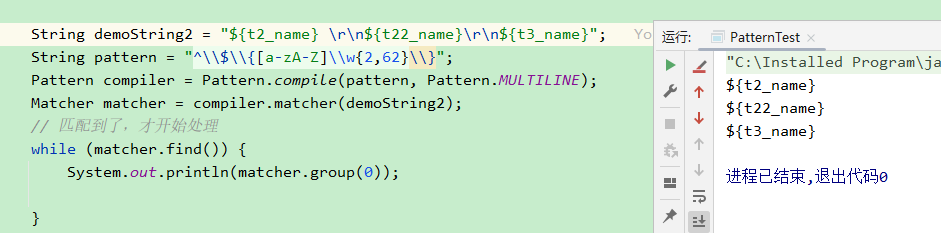
去掉^限制,也可以匹配到
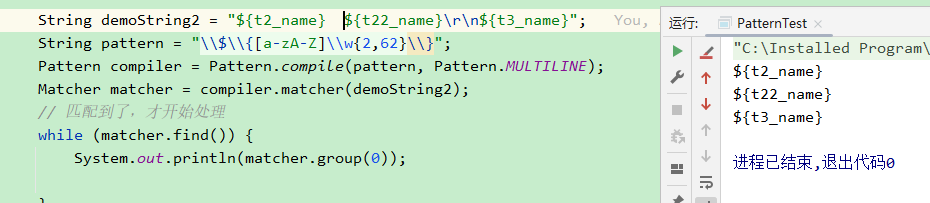
3. 代码实现
public static List<String> getStringFromPattern(String source, String pattern) {
List<String> result = new ArrayList<>();
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(source);
while (m.find()) {
result.add(m.group().substring(2, m.group().length() - 1));
}
return result;
}
4. 总结
1. pattern 和 matcher 的关系
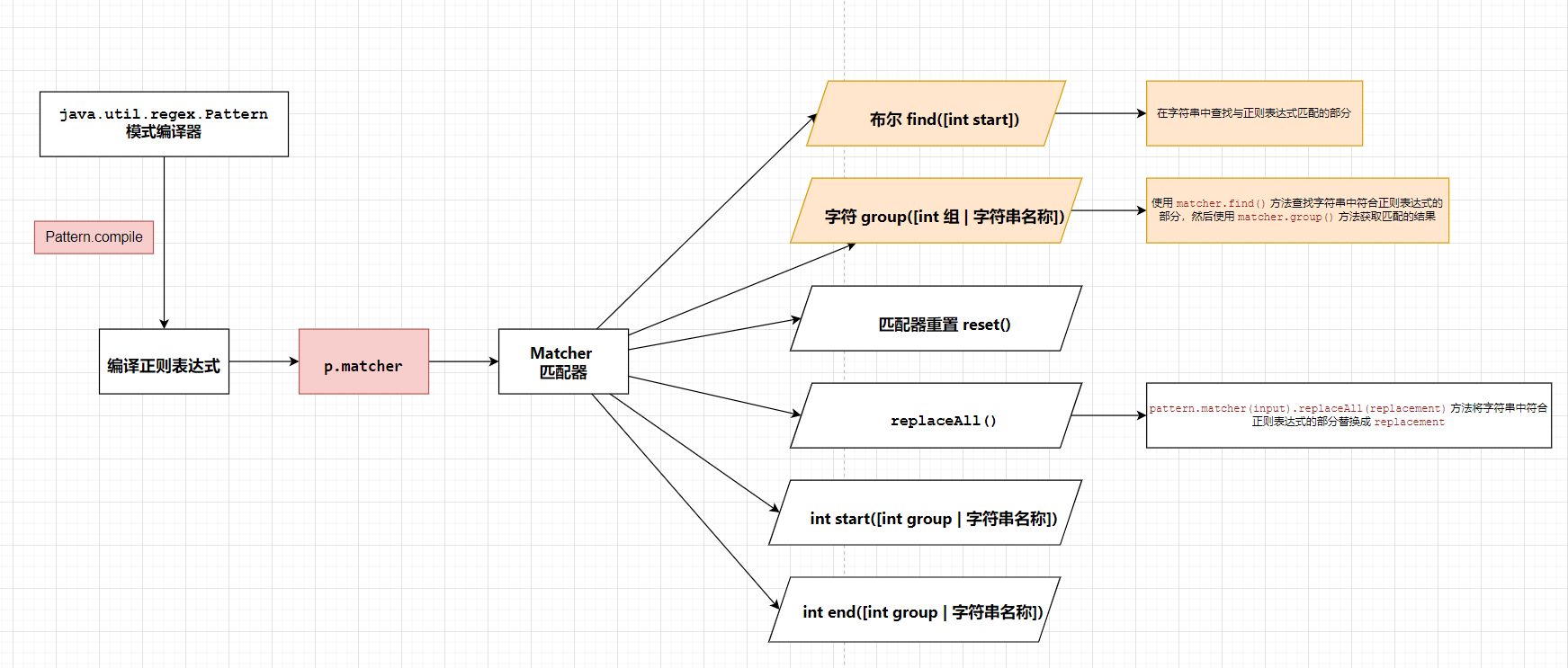
2. pattern 各类 flag 的含义
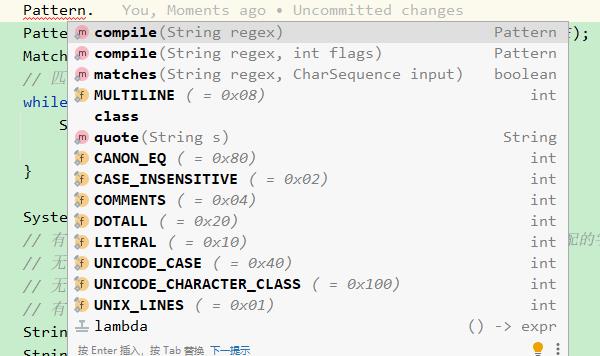
UNIX_LINES:unix lines模式,该模式下,仅以\n为结尾(行一般以\n或\r\n结尾);
CASE_INSENSITIVE:忽略大小写进行匹配;
COMMENTS:忽略空格字符(例如,表达式里的空格,tab,回车)和注释(从#开始,一直到行结束);
MULTILINE:多行模式的开启,在多行模式下,^匹配输入字符串开始的位置,$匹配输入字符串结尾的位置;
DOTALL:dotall模式,"."匹配所有字符,包括行终结符。(若该模式未开启,“.”表达式不匹配行终结符);
UNICODE_CASE:UNICODE_CASE模式结合CASE_INSENSITIVE模式,那么它会对Unicode字符进行大小写不敏感的匹配。(若未开启UNICODE_CASE模式,仅开始CASE_INSENSITIVE模式,则只适用于US-ASCII字符集);
CANON_EQ:当且仅当两个字符的正规分解都完全相同的情况下,则认定匹配。(默认情况下,不考虑规范相等性);
3. matcher 的常用方法
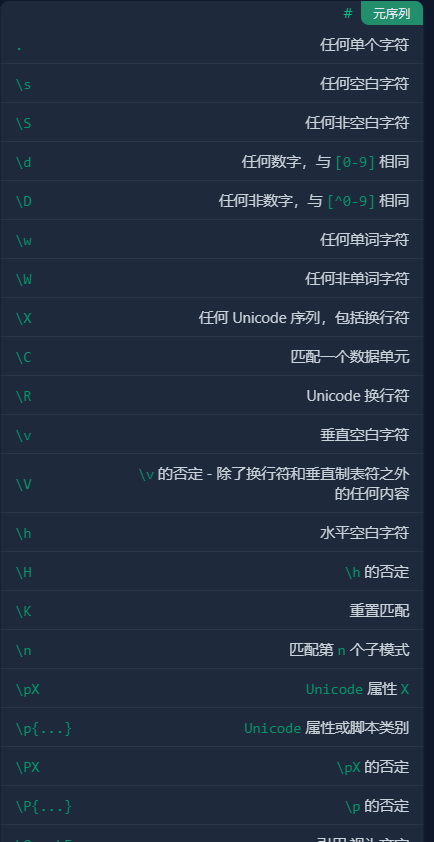
4. 正则表达式的常用组成部分
- 字符类

- 预定义字符
- 数量词

?惰性匹配,尽可能少的匹配
+贪婪匹配,尽可能多的匹配(默认)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号