具体代码(Python版本)
import numpy as np # 导入numpy库,用于进行数值计算
import matplotlib.pyplot as plt # 导入matplotlib库,用于绘制图形
from sklearn import datasets # 从sklearn库中导入datasets模块,用于加载数据集
from sklearn.model_selection import train_test_split # 导入train_test_split函数,用于划分训练集和测试集
from sklearn.preprocessing import StandardScaler # 导入StandardScaler类,用于数据标准化
from sklearn.neighbors import KNeighborsClassifier # 导入KNeighborsClassifier类,用于创建KNN分类器
from sklearn.metrics import classification_report, confusion_matrix # 导入分类报告和混淆矩阵的计算函数
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
import matplotlib
matplotlib.use('TkAgg')
import pandas as pd
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 数据集中的特征
y = iris.target # 数据集中的标签
# 划分训练集和测试集,测试集占20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建StandardScaler对象
sc = StandardScaler()
# 对训练集进行标准化处理
X_train_std = sc.fit_transform(X_train)
# 对测试集进行标准化处理,注意这里使用训练集得到的均值和标准差
X_test_std = sc.transform(X_test)
# 创建KNN分类器,设置邻居数为3
knn = KNeighborsClassifier(n_neighbors=3)
# 使用训练集数据对KNN分类器进行训练
knn.fit(X_train_std, y_train)
# 使用训练好的KNN分类器对测试集进行预测
y_pred = knn.predict(X_test_std)
# 打印混淆矩阵
print(confusion_matrix(y_test, y_pred))
# 打印分类报告
print(classification_report(y_test, y_pred))
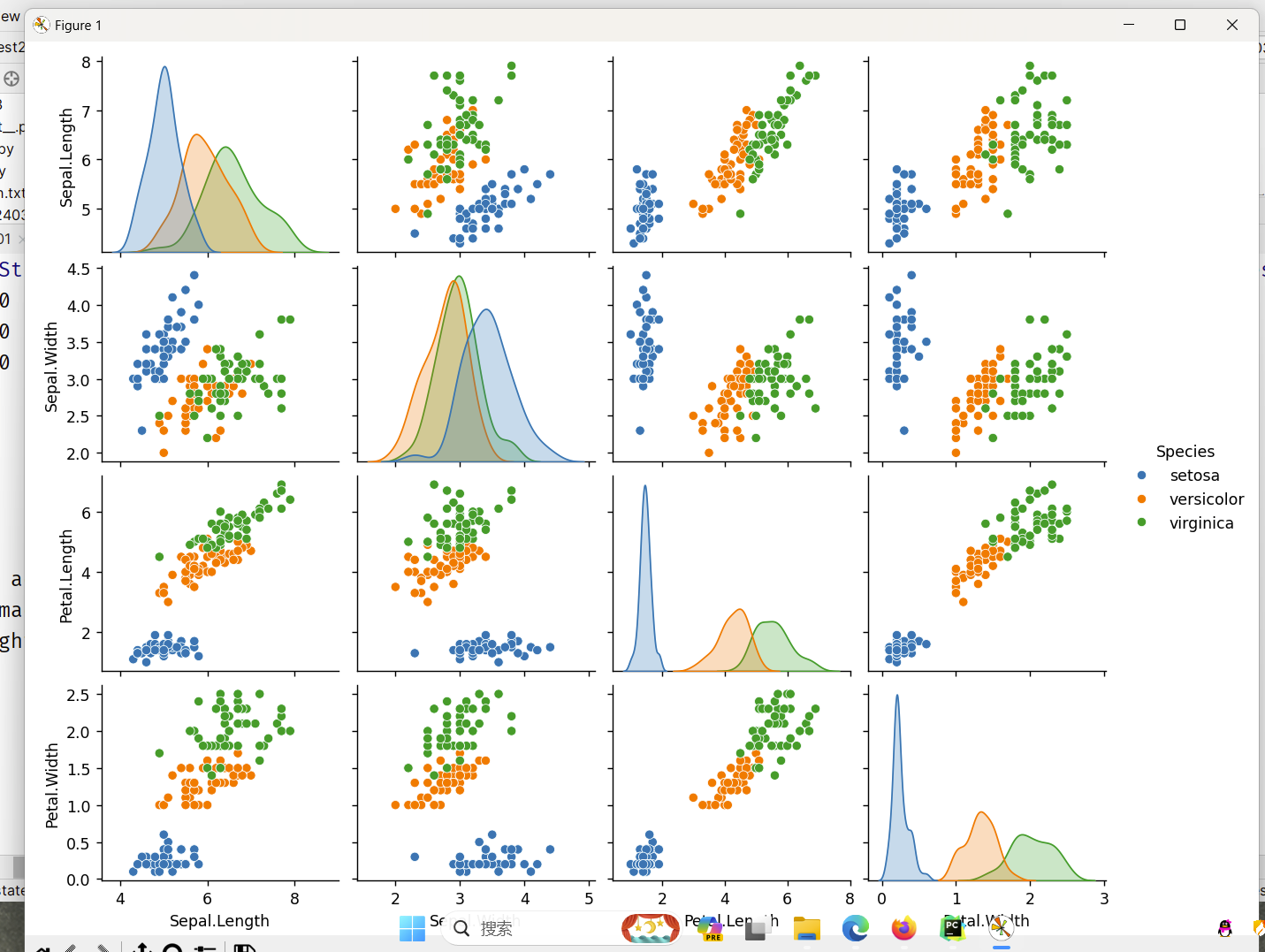
import seaborn as sns
iris = pd.read_csv('iris.csv') #读取iris数据集
sns.pairplot(iris, hue="Species") #绘图
plt.show() #显示图片
效果展示