具体代码(Python版本)
# coding: utf-8
#import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg')
from sklearn.preprocessing import scale
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
# boston = load_boston()
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.1, random_state=0)
X_train = scale(X_train)
X_test = scale(X_test)
y_train = scale(y_train.reshape((-1, 1)))
y_test = scale(y_test.reshape((-1, 1)))
def add_layer(inputs, input_size, output_size, activation_function=None):
with tf.variable_scope("Weights"):
Weights = tf.Variable(tf.random_normal(shape=[input_size, output_size]), name="weights")
with tf.variable_scope("biases"):
biases = tf.Variable(tf.zeros(shape=[1, output_size]) + 0.1, name="biases")
with tf.name_scope("Wx_plus_b"):
Wx_plus_b = tf.matmul(inputs, Weights) + biases
with tf.name_scope("dropout"):
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob=keep_prob_s)
if activation_function is None:
return Wx_plus_b
else:
with tf.name_scope("activation_function"):
return activation_function(Wx_plus_b)
xs = tf.placeholder(shape=[None, X_train.shape[1]], dtype=tf.float32, name="inputs")
ys = tf.placeholder(shape=[None, 1], dtype=tf.float32, name="y_true")
keep_prob_s = tf.placeholder(dtype=tf.float32)
with tf.name_scope("layer_1"):
l1 = add_layer(xs, 13, 10, activation_function=tf.nn.relu)
with tf.name_scope("y_pred"):
pred = add_layer(l1, 10, 1)
# 这里多余的操作,是为了保存pred的操作,做恢复用。
pred = tf.add(pred, 0, name='pred')
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - pred), reduction_indices=[1])) # mse
tf.summary.scalar("loss", tensor=loss)
with tf.name_scope("train"):
train_op = tf.train.AdamOptimizer(learning_rate=0.01).minimize(loss)
# 画画
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
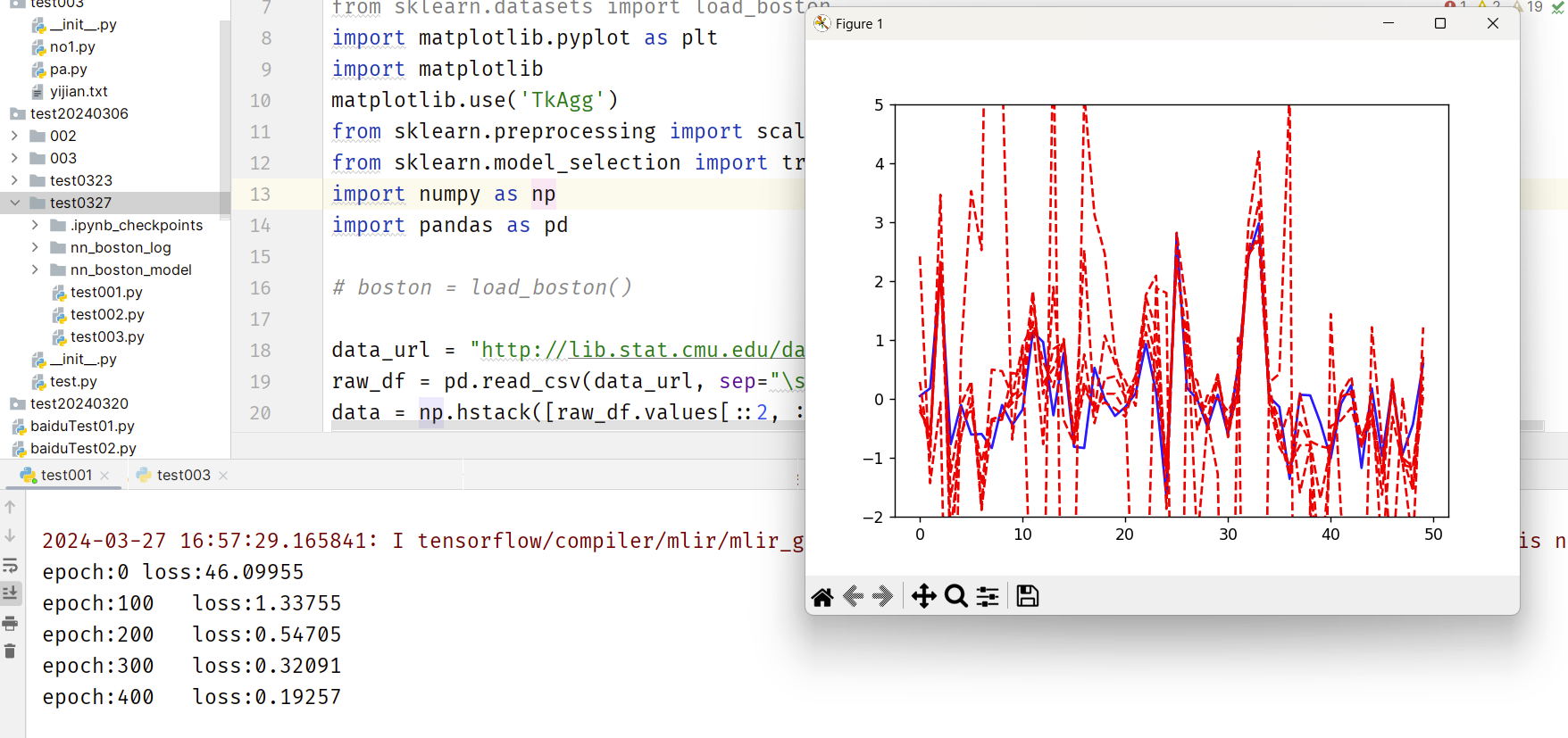
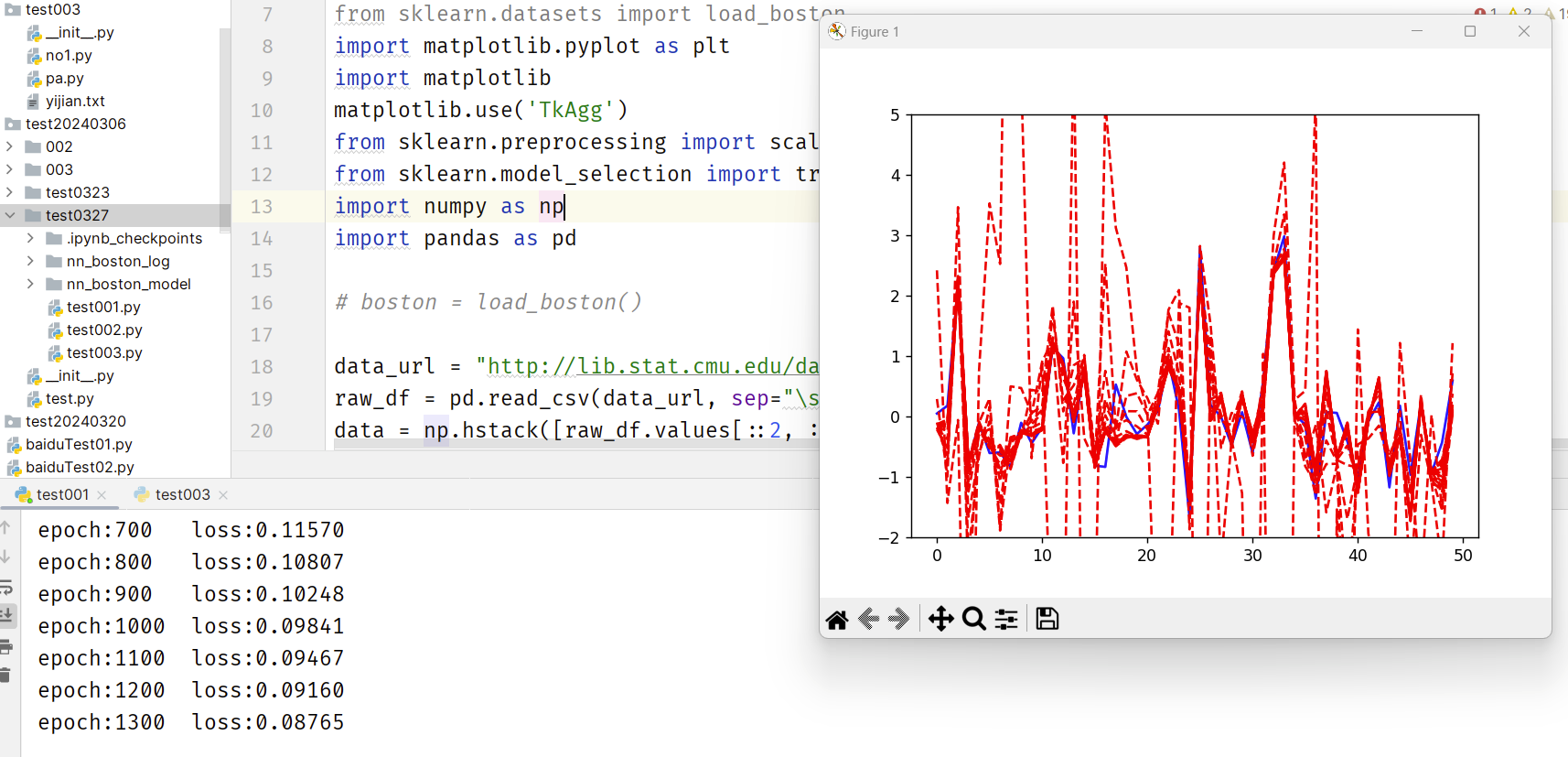
ax.plot(range(50), y_train[0:50], 'b') # 展示前50个数据
ax.set_ylim([-2, 5])
plt.ion()
plt.show()
# 参数
keep_prob = 1 # 防止过拟合,取值一般在0.5到0.8。此处是1,没有做过拟合处理
ITER = 5000 # 训练次数
def fit(X, y, ax, n, keep_prob):
init = tf.global_variables_initializer()
feed_dict_train = {ys: y, xs: X, keep_prob_s: keep_prob}
with tf.Session() as sess:
saver = tf.train.Saver(tf.global_variables(), max_to_keep=15)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter(logdir="nn_boston_log", graph=sess.graph) # 写tensorbord
sess.run(init)
for i in range(n):
_loss, _ = sess.run([loss, train_op], feed_dict=feed_dict_train)
if i % 100 == 0:
print("epoch:%d\tloss:%.5f" % (i, _loss))
y_pred = sess.run(pred, feed_dict=feed_dict_train)
rs = sess.run(merged, feed_dict=feed_dict_train)
writer.add_summary(summary=rs, global_step=i) # 写tensorbord
saver.save(sess=sess, save_path="nn_boston_model/nn_boston.model", global_step=i) # 保存模型
try:
ax.lines.remove(lines[0])
except:
pass
lines = ax.plot(range(50), y_pred[0:50], 'r--')
plt.pause(1)
saver.save(sess=sess, save_path="nn_boston_model/nn_boston.model", global_step=n) # 保存模型
fit(X=X_train, y=y_train, n=ITER, keep_prob=keep_prob, ax=ax)
效果展示