使用python编程实现数据清洗之增加行政区划编码列
具体代码
import pandas as pd
import os
import numpy as np
# 读取第一个CSV文件并包含表头
df = pd.read_csv("D:/12140/Desktops/111/222/test001.csv", encoding="utf-8") # 编码默认UTF-8,若乱码自行更改
data = df[['联系单位地址']]
data = data.fillna(0)
data_array = np.array(data.stack()) # 首先将pandas读取的数据转化为array
data_list = data_array.tolist() # 然后转化为list形式
print(data_list)
print(len(data_list))
import cpca
df = cpca.transform(data_list)
ddd = df[['adcode']]
ddd = ddd.fillna(0)
data_array2 = np.array(ddd.stack()) # 首先将pandas读取的数据转化为array
data_list2 = data_array2.tolist() # 然后转化为list形式
print(data_list2)
print(len(data_list2))
# 添加一列新的数据
df = pd.read_csv('D:/12140/Desktops/111/222/test001.csv')
# 添加新的一列,此时新列值均为null
df['行政区划编码'] = data_list2
df.to_csv("D:/12140/Desktops/111/222/test002.csv",index=False)
# 保存到新的CSV文件
df.to_csv('D:/12140/Desktops/111/222/test002.csv', index=False)
print("增加行政区划编码列成功!")
这里面主要应用到了cpca.transform的函数转换
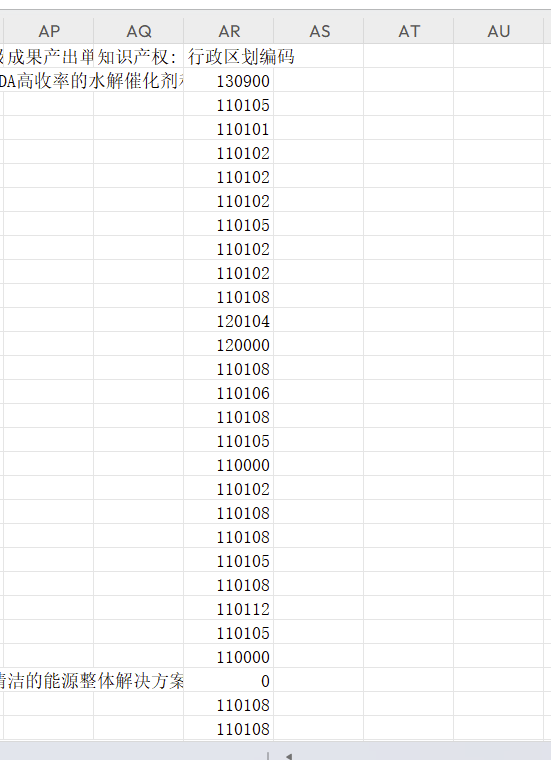
效果展示


 浙公网安备 33010602011771号
浙公网安备 33010602011771号