大型数据库实验二
实验二--熟悉常用的HDFS操作
1、向hdfs中上传任意文本文件,如果文件已经存在,由用户指定是追加文件内容还是覆盖文件内容(准备了两个文件-wordcount.txt和local.txt)

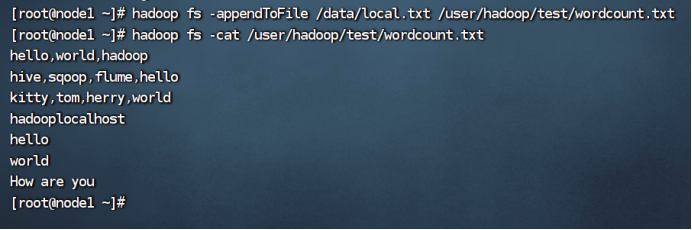
我这里定义的是在wordcount.txt文件末尾追加local.txt里面的内容:
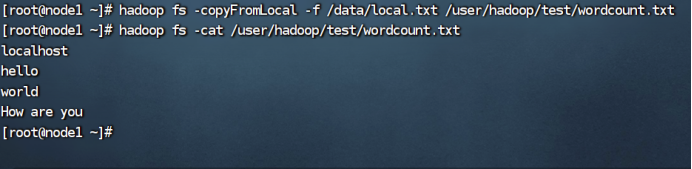
这里定义的是用local.txt的文件内容覆盖掉原来的wordcount.txt的文件内容:
2、从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动重命名
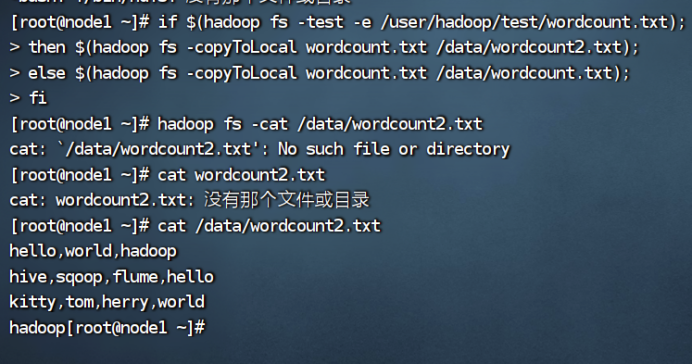
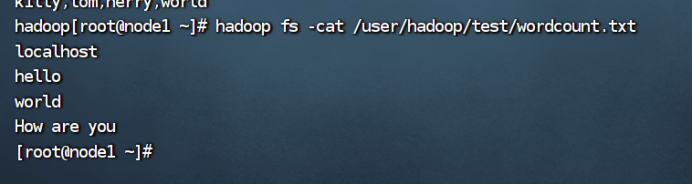
3、将HDFS中指定的内容输出到终端中
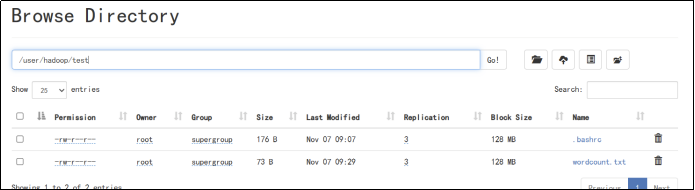
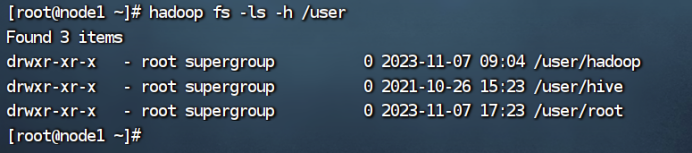
4、显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;如果文件是目录,那么就递归输出该目录下所有文件相关信息
5、提供一个HDFS内的文件路径,对该文件进行创建和删除操作,如果文件目录不存在,那么就自动创建目录
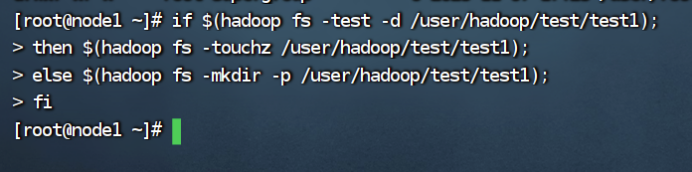


6、提供一个HDFS的目录路径,对该目录进行创建和删除操作,如果对应目录不存在,则自动创建目录;删除操作时,如果目录不为空,由用户指定是否删除该目录

创建目录操作如上图;

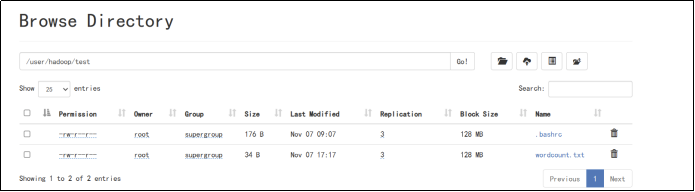
删除目录操作如上图;
7、向HDFS中的文件追加内容,由用户指定是追加到开头还是结尾
追加到文件末尾:
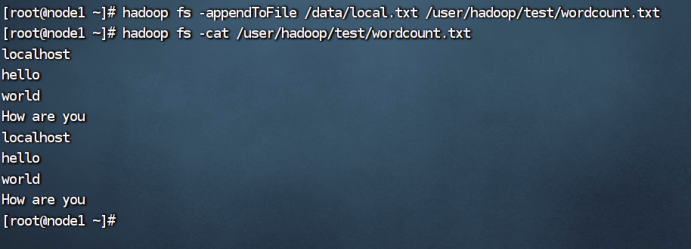
追加到文件开头:
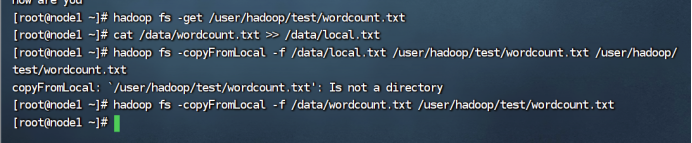
8、删除HDFS中指定的文件

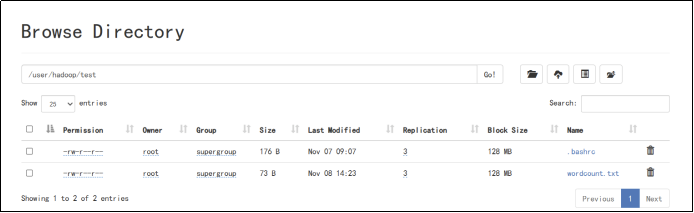
9、在HDFS中,将目录从源路径移动到指定路径

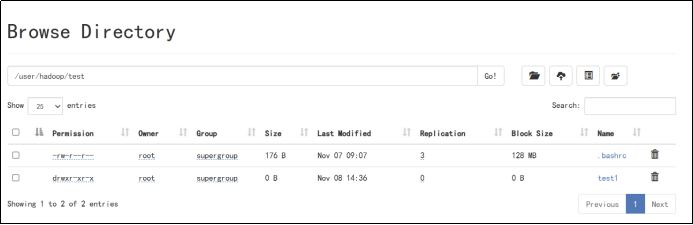
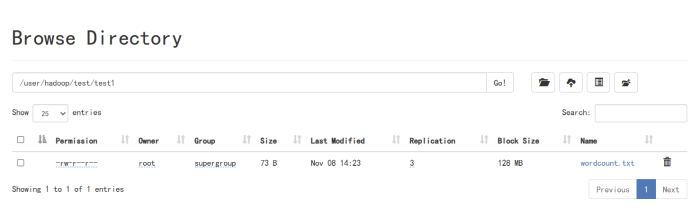
10、编程实现一个类“MyFSDataInputSt”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本
编写Java代码:
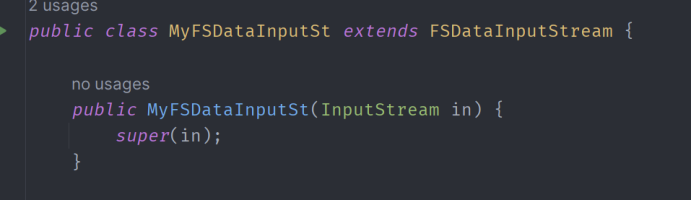
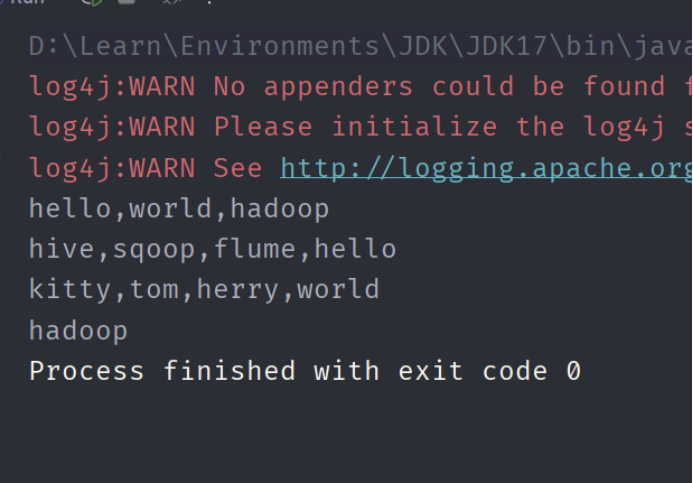
程序运行得到结果:
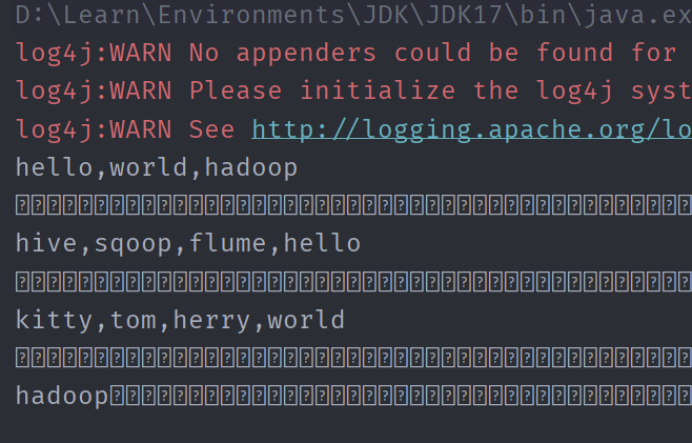
11、查看Java帮助手册或其它资料,用”java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程完成输出HDFS中指定文件的文本到终端中
编写Java代码:
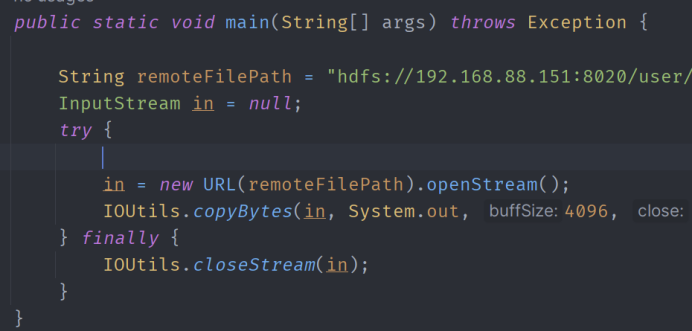
程序运行得到结果: