大型数据库作业相关步骤实现
1、导入Maven压缩包到虚拟机本地

2、解压maven压缩包
sudo unzip apache-maven-3.9.2-bin.zip
3、以当前主机用户名登录

4、在终端创建一个名为sparkapp2的文件夹
cd ~
mkdir -p ./sparkapp2/src/main/java
//在上面的目录下新建一个名为SimpleApp.java的文件--在/sparkapp2/src/java的目录下执行
vim SimpleApp.java

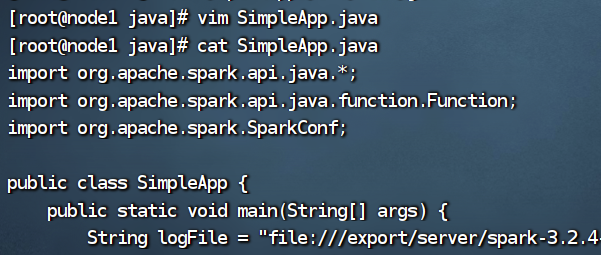
5、在SimpleApp.java文件里面写入相应代码
/*** SimpleApp.java ***/
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.SparkConf;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "file:///export/server/spark-3.2.4-bin-hadoop3.2/README.md";
SparkConf conf=new SparkConf().setMaster("local").setAppName("SimpleApp");
JavaSparkContext sc=new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile).cache();
long numAs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("a"); }
}).count();
long numBs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("b"); }
}).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
}
}
保存退出:
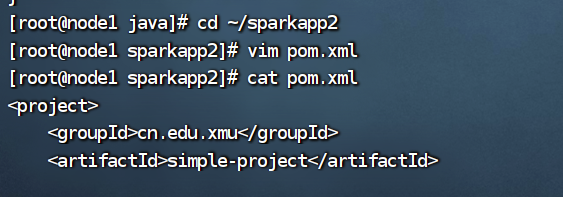
6、在sparkapp2文件中新建pom.xml文件,并将下面的代码放入,以便Maven打包
<project>
<groupId>cn.edu.xmu</groupId>
<artifactId>simple-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Simple Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<repositories>
<repository>
<id>jboss</id>
<name>JBoss Repository</name>
<url>http://repository.jboss.com/maven2/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.2.4</version>
</dependency>
</dependencies>
</project>
保存退出即可;
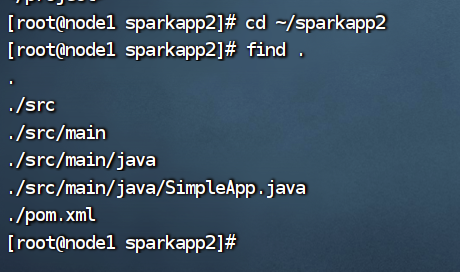
7、Maven打包Java程序之前--检索文件目录结构
首先检索整个文件夹的目录结构:
cd ~/spaekapp2
find .
得到目录结构如下:
么得问题;
8、打包进行时~~
cd ~/sparkapp2
/export/server/apache-maven-3.9.2/bin/mvn package


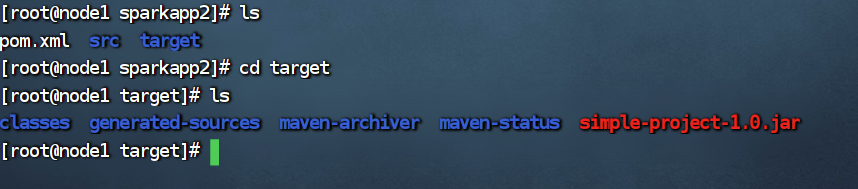
那个红色的就是我们打包好的Java程序啦~
9、通过spark-submit运行程序
/export/server/spark-3.2.4-bin-hadoop3.2/bin/spark-submit --class "SimpleApp" ~/sparkapp2/target/simple-project-1.0.jar 2>&1 | grep "Lines with a"
/export/server/spark-3.2.4-bin-hadoop3.2/bin/spark-submit --class "SimpleApp" ~/sparkapp2/target/simple-project-1.0.jar

运行成功,输出结果--直接在主目录下运行即可(我一开始在spark-shell里面运行,一直报错);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号