虚拟机的Spark安装步骤
相关代码截图
//解压压缩包
tar -zxvf spark-3.2.4-bin-hadoop3.2.tgz

//进入到spark安装目录的conf目录下
//复刻spark--env.sh.template文件
cp spark-env.sh.template spark-env.sh
//修改spark-env.sh文件配置,在文件末尾加上这些代码语句
export SPARK_DIST_CLASSPATH=$(/export/server/hadoop-3.3.0/bin/hadoop classpath)
//或者加上下面这些
export JAVA_HOME=/usr/local/java/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop
SPARK_MASTER_IP=node1 #这里的node1是我的主机名
SPARK_LOCAL_DIRS=/export/server/spark-3.2.4-bin-hadoop3.2
SPARK_DRIVER_MEMORY=1G
然后保存退出即可;

//到spark的安装目录下用spark自带示例验证spark是否安装成功
cd /export/server/spark-3.2.4-bin-hadoop3.2
//验证命令
bin/run-example SparkPi
//或者
bin/run-example SparkPi 2>&1 | grep "Pi is"
结果显示,安装成功:

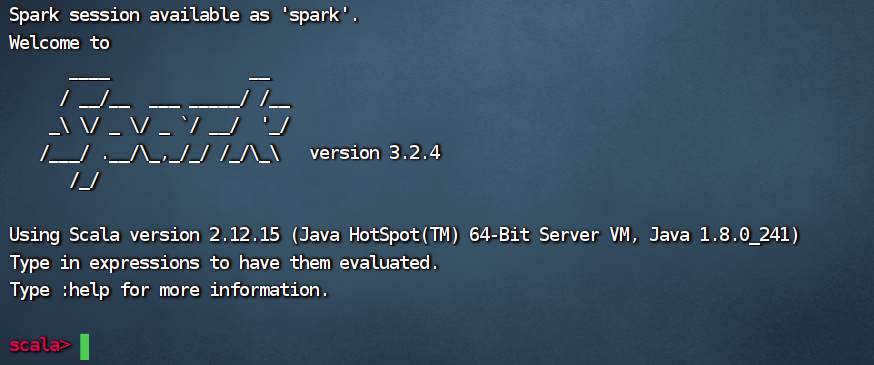
//启动Spark Shell--spark安装目录下
bin/spark-shell
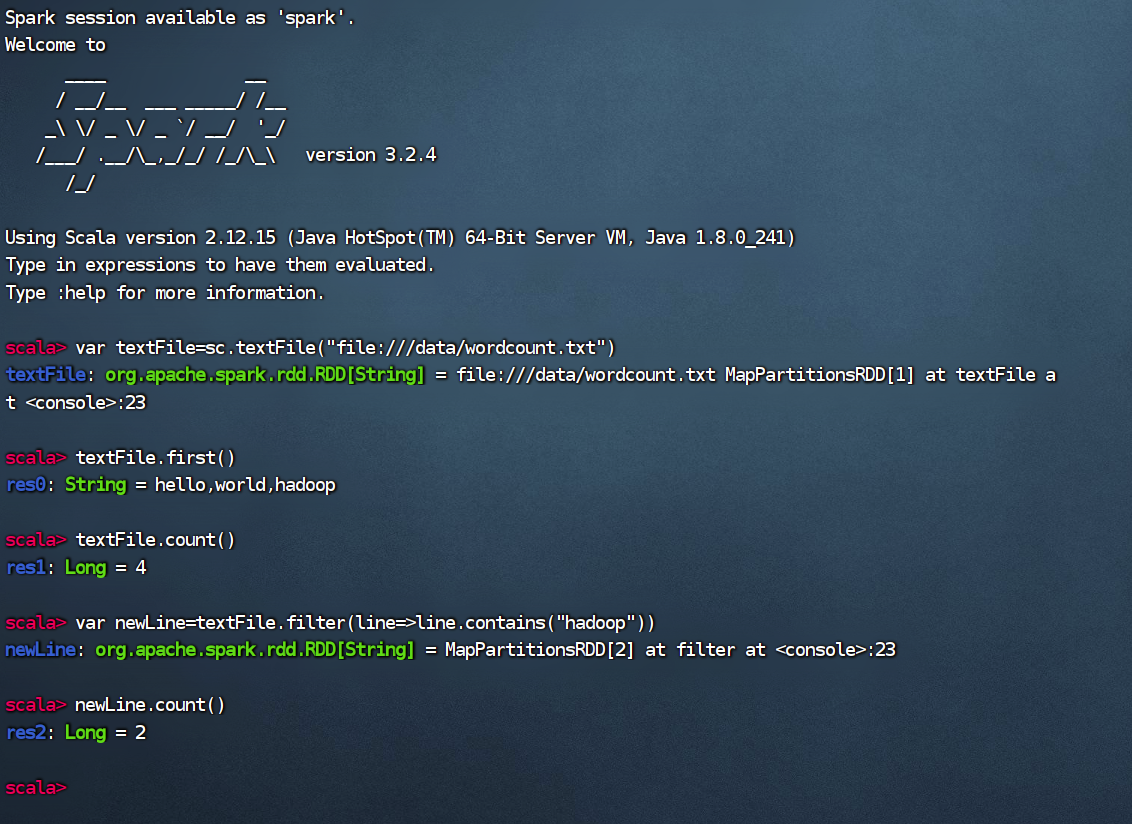
简单应用:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号